目录
1 Co-teaching: 面向极度噪声标签的鲁棒性深度神经网络训练模型 (NIPS 2018)
2 MixMatch: 一种全面的半监督学习方法 (NIPS 2019)
3 DivideMix: 采用半监督学习进行噪声标签学习 (ICLR 2020)
1 Co-teaching: 面向极度噪声标签的鲁棒性深度神经网络训练模型 (NIPS 2018)
1.1 动机
带噪声标签的深度学习实际上是一个挑战,因为深度模型的容量非常大,在训练过程中它们迟早可以完全记住这些噪声标签。然而,最近关于深度神经网络记忆效果的研究表明,深度神经网络会先记忆干净标签的训练数据,然后再记忆嘈杂标签的训练数据。
1.2 贡献
在本文中,我们提出了一种新的深度学习范式,称为“Co-teaching”,以对抗噪声标签。即,我们同时训练两个深度神经网络,并让它们在每个小批处理中进行互教:首先,每个网络前馈所有数据,选取一些可能是干净标签的数据;其次,两个网络相互通信,在这个小批量中应该使用哪些数据进行训练;最后,每个网络回传由其对等网络选择的数据并更新自身网络权重超参数。
本文的Co-teaching模型结构如下:

在Co-teaching中,两个网络有不同的初始化,所以有不同的学习能力,这样的误差会在信息交换的过程中被缓解。Co-teaching的两个网络,在交替过程中,由于网络的不同参数初始化,会对其中的错误数据进行遗忘,即大概率不会拟合的很好,从而起到误差累积的缓解作用。
算法伪码:

1.3 实验分析
本文的实验在MNIST,CIFAR10和CIFAR100三种数据集上进行了实验分析,具体如下:


超参数分析实验:
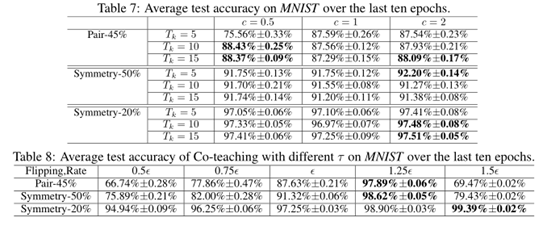
1.4 我的思考
本文的模型具有普遍性,即其Co-teaching的选择策略不会受到backbone的不同的影响,比如采用简单的MLP网络进行噪声标签训练也是适用的。另外,本文的引用量也比较高,目前以达到五百多次,在噪声标签领域也是一篇影响力很大的文章,很多新的方法都会参考本文模型的思想。
另外,本文提出的神经网络模型容易先对干净标签数据进行拟合,随着训练次数的上升,逐渐会对噪声标签数据进行拟合。这一现象可能也表明,在部分数据集上,并不是训练的epoch次数越大越好,并且也让我们对于神经网络的偏好有了一种新的理解。
然而,本文的策略也有一个比较大的问题,其会遗忘网络认定的噪声标签数据,如果遗忘率设定较大,则会导致模型难以学习到原始数据集的分布,导致预测性能较差,即很难对噪声标签率比较大的数据进行建模学习。而文章中,默认的遗忘率是0.2,相关最新文章也表明,在真实噪声标签数据集中,设定为0.3比较合理
2 MixMatch: 一种全面的半监督学习方法 (NIPS 2019)
2.1 动机
最近在训练大型深度神经网络方面取得的成功,在很大程度上要归功于大型含标签数据集的存在。然而,对于许多学习任务来说,收集有标记的数据是昂贵的,因为它必然涉及到专家知识,例如医疗领域,需要相关专业医生来对数据进行打标签。
半监督学习已经被证明是利用无标记数据来减轻对大型标记数据集的依赖的一个强有力的范例。同时,半监督学习通过利用未标记数据,在很大程度上减轻了模型对标记数据的需求。
2.2 贡献
本文通过采用数据增强对无标注数据进行标签猜测,并结合MixUp混合有标签和无标签数据的策略,提出了一种新的半监督学习方法:MixMatch。
(1)多次数据增强,平均加Sharpen策略进行标签猜测
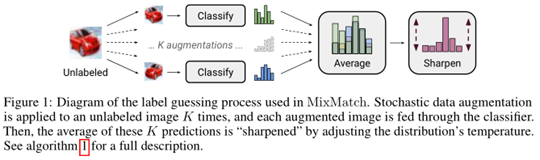
具体原理公式如下:


(2)结合改进的MixUp策略,获取经过数据增强和标签猜测处理后的含标注的数据和含猜测标注的数据

最后,看一下MixMatch的整理算法流程和损失函数的设定:

损失函数:

2.3 实验分析
本文在CIFAR10、CIFAR100、SVHN和STL-10四种数据集上进行了半监督实验分析。其中含标签的数据,从250-4000设定,其余采用无标注数据来进行分析。
相关实验结果表明本文的MixMatch算法能够在含250组标注数据的情况下,取得baseline算法需要4000组甚至5000组标注数据的性能。具体实验结果如下:



2.4 我的思考
本文算法中最重要的环节,是数据增强,而这一步骤限制了本文算法难以应用到一般的序列化数据集上,即非图像数据一般难以在下游任务应用之前合理地利用数据增强来提高模型的性能。
然而,本文对含标注的数据采用交叉熵损失函数,对无标签的数据采用均方误差损失函数的思路,可以借鉴。另外,本文最大的一个亮点在于猜测标签步骤中采用了Sharpen方法,而这一处理机制在本文的消融实验表明是本文算法的核心组成之一,而另一核心组成则是MixUp机制。
因此,在于后续研究半监督学习时,可以尝试采用MixUp和Sharen以及均方误差损失函数的思路来对模型的性能进行尝试性调节。
3 DivideMix: 采用半监督学习进行噪声标签学习 (ICLR 2020)
3.1 动机
众所周知,深度神经网络的建模学习非常依赖标签。在使用深度网络进行学习时,为了降低打标签的成本,人们做出了大量的努力。两个突出的方向包括使用带噪标签的学习和利用无标签数据的半监督学习。
3.2 贡献
在这项工作中,我们提出了DivideMix,一个利用半监督学习技术学习带噪声标签的新框架。其中,DivideMix采用混合模型对单样本损失分布进行建模,动态地将训练数据划分为干净样本的有标签数据集和噪声样本的无标签数据集,并对有标签数据和无标签数据进行半监督训练。为了避免确认偏差,我们同时训练了两个不同的网络,其中每个网络使用从另一个网络的数据集划分(Co-teaching思想)。在半监督训练阶段,我们改进了MixMatch策略,分别对已标注样本和未标注样本进行标签共细化和标签共猜测。
本文的样本交互选取策略其实和2018年的NIPS的样本Loss选择策略很类似,一个是在训练的Loss层面进行样本选择,一个是在网络开始训练时就选定好干净的含标签数据,具体模型的算法伪码如下:
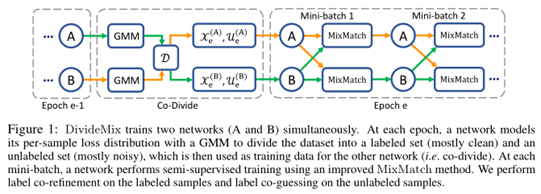

在MixMatch基础上,添加了对含标签数据的数据增强和标签认定的步骤,具体如下:

另外,本文提到了采用熵来促使模型学习不对称的噪声数据,具体如下:

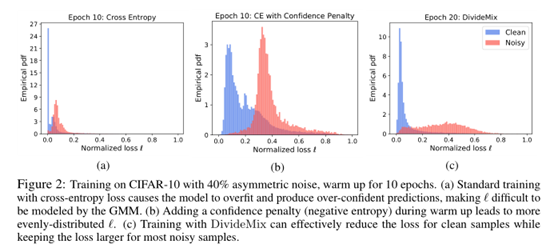
在模型的整体Loss方面添加了正则化Loss,从而使得模型能够有效区分不同类的预测能力,具体如下:

3.3 实验分析
本文在CIFAR10, CIFAR100, Clothing1M和WebVision四种数据集上进行了实验,具体如下:
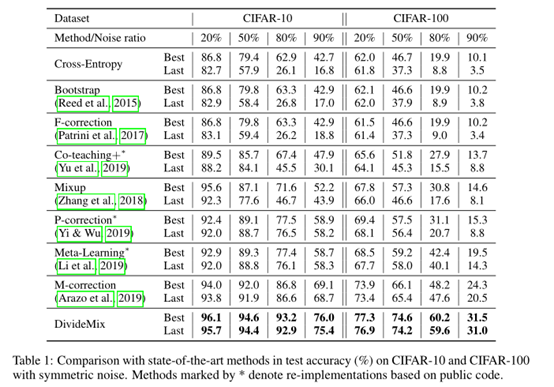
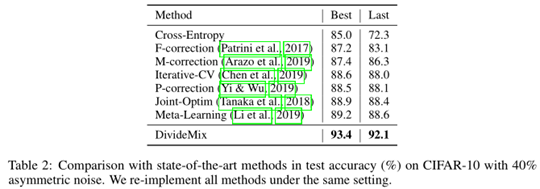
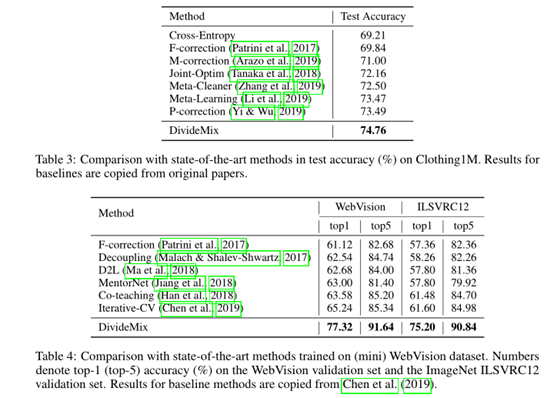
消融实验结果如下:
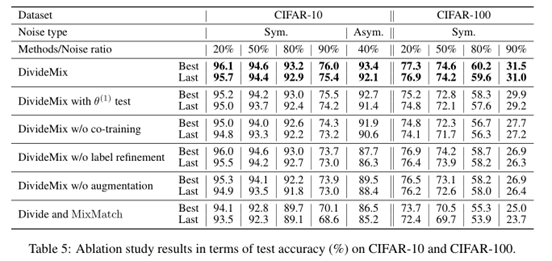
3.4 我的思考
本文最大的亮点是其最终的实验结果提升幅度较大,也是编委和评审专家最认同的一点。而文章的整体算法模型和创新都统一只给了6分。因此,在论文的创新点方面,如果最大化地提升最终的实验结果也是一个不错突破点。
另外,看了ICLR上的相关讨论和评分审稿意见,得出本文的模型过于复杂,并且可能并不太可能成为主流的噪声标签框架模型。但是,本文的实验结果确需要被最新模型拿来对比,即本文模型能够成为一个Strong baseline。
4 Boosting Co-teaching: 标签噪声的压缩正则化 (CVPR 2021)
4.1 动机
本文研究了标签噪声存在下的图像分类模型的学习问题。我们重新讨论一个简单的名为压缩正则化的Nested Dropout。我们发现Nested Dropout虽然最初被提出用于快速信息检索和自适应数据压缩,但可以适当地正则化神经网络来对抗标签噪声。
此外,由于其简单性,它可以很容易地与Co- teaching结合,以进一步提高性能。
4.2 贡献
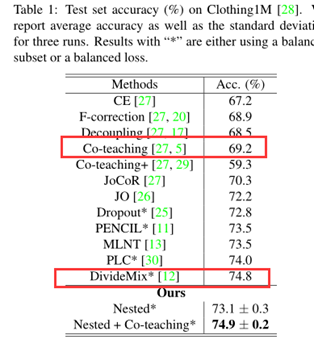
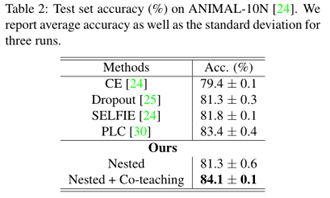
我们最终的模型仍然简单而有效:它在两个具有标签噪声的真实数据集Clothing1M和ANIMAL-10N上取得了与最先进的方法相当甚至更好的性能。在Clothing1M上,我们的方法获得了74.9%的准确率,略优于DivideMix。
本文希望其提出的简单方法可以作为标签噪声领域一个强大的baseline。
Nested Dropout原理如下:

4.3 实验分析
本文实验在Clothing 1M和ANIMAL-10N两个真实的噪声标签数据集上执行了实验,具体如下:
超参数分析:

4.4 我的思考
本文的Dropout策略很大可能对backbone的要求比较高,而且比较偏向图像数据集,对于一般的序列化或者低维数据集,其性能可能无法展现。另外,本文的类似Dropout策略,有种特征选择的思维,即选取其中能够区分样本的对于维度的representation。
相比之下,Co-teaching策略则是对于backbone的要求较低,即其是具有较高的普遍性。不过,本文的Nested Dropout的策略,很可能会让相关研究看看特征选择或者去探究dropout策略真正起作用的实质。