1 报文与实体
如果将HTTP对内容的传输比喻成实际生活中一些货物的运输的化。那HTTP报文就相当于是用于运输货物的“箱子”,而实体内容则是我们真正需要运输的“货物”。所以实体也就是被封装在了报文当中。
现实货物运输中,一般箱子上也会有一些描述信息,用于对运输的货物进行描述说明。HTTP报文中也是一样,也会有相应的实体首部,对实体内容进行描述说明,以便我们的接收方能正确处理实体内容。在HTTP/1.1中常用的实体首部如下所示:
- Content-Type:实体内容的MIME类型
- Content-Length:实体内容的长度或大小
- Content-Language:传输的实体内容最匹配的语言类型
- Content-Encoding:对实体数据所做的变换(如:压缩)
- Content-Location:实体数据的一个备用位置
- Content-Range:将实体分为几个部分进行传输的时候,说明该部分实体是属于哪个部分
- Content-MD5:内容数据的校验和
- Last-Modified:所传输内容最近一次创建或者修改时间
- Expires:数据的失效时间
- Allow:该资源所允许的请求方法(如:GET, HEAD等)
- ETag:该份实体数据的唯一验证码
- Cache-Control:实体内容缓存有关的控制
2 实体大小(长度)控制
Content-Length首部指示出报文中实体主体的字节大小。此处的大小是指内容编码之后的大小。
比如我们传输一份文档,在传输之前我们进行了gzip压缩,最终传输的是这份压缩后的文档,此时,这里的Content-Length的大小是指gzip压缩后的大小,而不是原始文档大小。
2.1 一些注意事项
a)、正确携带Content-Length首部
同时为了接收端能正确处理实体内容,除非是使用分块编码,其他情况都应该带上Content-Length的值。有了这个值,通过对收到的内容实际长度和该首部的值进行对比,接收端就能正确判断报文是正常结束,还是因为连接断开等其他非正常结束。
b)、要避免给出错误的Content-Length的值
Content-Length的值错误比缺少Content-Length首部带来的影响还要打。缺少该首部是在某些情况会影响到对内容的处理,但是如果值错误,这个时候接收端始终会认为收到的内容有误,无法正确处理内容。
c)、持久连接必须携带Content-Length
持久连接是必须有Content-Length首部。因为持久连接一直处于连接状态,接收端是无法从关闭连接判别报文的结束,就必须通过Content-Length的值来判断报文再哪里结束,下一条报文从哪里开始。
2.2 确定实体(大小)长度的规则
既然Content-Length首部对于正确处理实体内容如此重要,正常情况也需要给出该首部正确的值,但是并不是所有的服务器或者客户端都严格遵循这一规定。实际处理当中,为了正确确定实体内容的长度,我们一般遵循如下几条规则:
- 如果是某些特定不允许携带有实体内容的报文类型,直接忽略Content-Length首部(比如HEAD响应和GET一样,也应该有Content-Length首部,但是其是不会携带实体内容的,这个时候我们直接忽略该首部即可)
- 如果报文中含有Transfer-Encoding首部(不采用HTTP默认的恒等编码),这个时候判断报文结束是根据一个称为“零字节块”(zero-byte chunk)的特殊模式,或者是因为连接断开关闭。也就意味着这个时候如果即使有Content-Length首部,也应该被忽略。
- 如果报文类型允许携带实体内容,同时也没有非恒等的Transfer-Encoding首部,这个时候,就应该以Content-Length首部的值就是报文实体的长度。
- 如果报文使用了multipart/byteranges(多部分 / 字节范围)媒体类型,允许报文可以不携带Content-Length首部,这个时候每个分块就必须说明自己的大小,接收端可以通过这个数据判断出整个实体内容的大小。但是使用该种方式有个前提,是发送端要知道接收端是能识别和处理这种类型的报文,否则就不能使用这种类型。
- 如果对于以上几种规则都不匹配,这个时候默认就以连接关闭为报文结束。但是这种方式一般只有服务器对客户端使用。因为客户端如果对服务器使用这种方式,服务端的响应就没法送回客户端了。如果客户端非要使用这种方式,可以通过半关闭的方式(即先关闭发送端,接收端保持连接),具体信息可以查阅Http权威指南笔记(四)——连接管理。
3 实体摘要
现在我们的请求很多时候都会经过一些代理。如果我们中间的代理处于有误,或者转码出现不兼容等问题的时候,就可能会造成我们收到的报文实体是不正确的。这个时候为了接收端能够自己进行验证收到实体是否正确,发送端可以生成一个实体数据的校验和给接收端用于检测报文的完整性。该校验和正常的中间代理是不会对此进行修改的。不过这种方式只能防止非恶意的修改,如果是恶意修改,除了修改报文实体也会同时修改校验和,这个时候接收端是无法判断的。
一般校验和会放入Content-MD5首部进行传输。应该注意的是该校验对是在内容编码之后(如果存在内容编码),传输编码之前(如果存在传输编码)的数据进行计算生成的。所以接收端在收到报文后,需要先进行传输编码的解码,然后对解码后的内容进行验证。
4 媒体类型和字符集
Content-Type首部用于说明实体主体的MIME类型。关于MIME类型,使用的是在IANA中注册标准MIME类型,一般格式为“主类型/子类型”,如:text/html, img/jpeg等。这里就不详细说明了,感兴趣的可以自己搜索下相关资料。
注:该首部说明的是原始实体主体的媒体类型,就算实体经过内容编码,Content-Type首部说明的仍是编码之前的实体主体即原始实体内容的类型。
该首部除了说明实体的MIME类型外,还可以说明实体所使用的字符编码信息,如:
Content-Type: text/html; charset=utf-8
字符的信息,一般是跟在MIME类型后面,用charset进行指定。它说明把实体中的比特转换为文本文件中的字符的方法。
指定的MIMI类型中,有个稍微特殊的类型就是多部分媒体类型。一般我们在提交表格或者将文档内容作为多个片段进行传世的时候会用到。
HTTP 使用 Content-Type:multipart/form-data 或 Content-Type:multipart/mixed 这样的首部以及多部分主体来发送这种请求,举例如下:
Content-Type: multipart/form-data; boundary=[abcdefghijklmnopqrstuvwxyz]
其中boundary用于说明用于分隔各个部分的字符串,如下面的传输内容是一段提交表单内容的示例:
Content-Type: multipart/form-data; boundary=AaB03x --AaB03x Content-Disposition: form-data; name="submit-name" Sally --AaB03x Content-Disposition: form-data; name="files"; filename="essayfile.txt" Content-Type: text/plain ...contents of essayfile.txt... --AaB03x--
同时这种方式还可以进行嵌套的,比如我们在上述传输表单普通文本内容的基础上,增加一个附件的功能(传输一个text文件和一张gif图片),报文示例如下:
Content-Type: multipart/form-data; boundary=AaB03x --AaB03x Content-Disposition: form-data; name="submit-name" Sally --AaB03x Content-Disposition: form-data; name="files" Content-Type: multipart/mixed; boundary=BbC04y --BbC04y Content-Disposition: file; filename="essayfile.txt" Content-Type: text/plain ...contents of essayfile.txt... --BbC04y” Content-Disposition: file; filename="imagefile.gif" Content-Type: image/gif Content-Transfer-Encoding: binary ...contents of imagefile.gif... --BbC04y-- --AaB03x--
可以看到,整个表单的内容使用多部分媒体传输的时候使用--AaB03x--进行分割,在涉及到附件的时候,我们再次使用多部分媒体类型进行传输,这个时候使用--BbC04y--进行内容分割。
除了请求,我们的响应也是可以使用多部分媒体类型的,如果下面的示例,展示了一个对文档不同范围请求产生的响应:
HTTP/1.0 206 Partial content Server: Microsoft-IIS/5.0 Date: Sun, 10 Dec 2000 19:11:20 GMT Content-Location: http://www.joes-hardware.com/gettysburg.txt Content-Type: multipart/x-byteranges; boundary=--[abcdefghijklmnopqrstu vwxyz]-- Last-Modified: Sat, 09 Dec 2000 00:38:47 GMT --[abcdefghijklmnopqrstuvwxyz]-- Content-Type: text/plain Content-Range: bytes 0-174/1441 Fourscore and seven years ago our fathers brought forth on this continent a new nation, conceived in liberty and dedicated to the proposition that all men are created equal. --[abcdefghijklmnopqrstuvwxyz]-- Content-Type: text/plain Content-Range: bytes 552-761/1441 But in a larger sense, we can not dedicate, we can not consecrate, we can not hallow this ground. The brave men, living and dead who struggled here have consecrated it far above our poor power to add or detract. --[abcdefghijklmnopqrstuvwxyz]-- Content-Type: text/plain Content-Range: bytes 1344-1441/1441 and that government of the people, by the people, for the people shall not perish from the earth. --[abcdefghijklmnopqrstuvwxyz]--
5 内容编码
很多时候我们在传输内容实体之前,会对实体内容进行编码处理。比如进行gzip压缩,或者是加密等。一般我们称之这个过程为内容编码。
5.1 内容编码的过程
内容编码的主要过程有如下3步:
- 生成原始报文,一般原始报文中含有Content-Type和Content-Length首部。
- 编码服务器(可能是原始发送端本身,也有可能是发送端的下行代理)对报文实体进行编码。编码后一般也会携带Content-Type和Content-Length。Content-Type和原始报文一致,但是Content-Length可能会有变化。比如我们进行gzip压缩后,这里的Content-Length就是压缩后的大小。
- 接收端收到报文后,先对报文进行解码,获得原始报文后再做处理
5.2 内容编码的类型
HTTP定义了一些
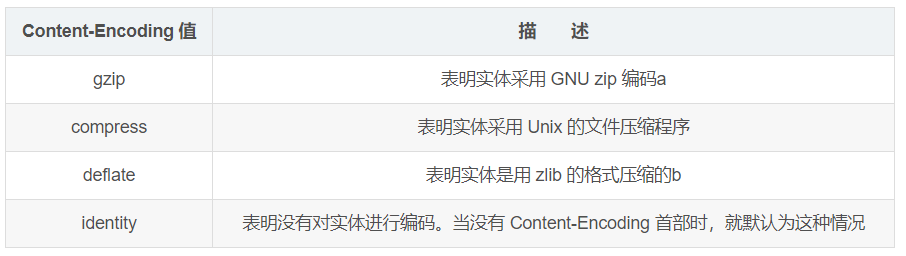
这里面gzip是使用比较平凡的一种压缩编码方式。
内容编码一般都是服务器进行编码,客户端收到报文后进行解码。这样,可能存在一种情况是服务器用了一种客户端无法解码的类型进行编码,这个时候就会出现错误。在HTTP中为了解决这种错误,引入了Accept-Encoding首部。客户端在请求的时候,可以使用该首部告知服务器端客户端可以处理的编码类型。同样,如果可以接收处理多个编码类型,我们可以使用“,”隔开每种编码,同时可以为每种编码指定一个优先级,告知服务器,优先选择哪种编码,示例如下:
Accept-Encoding: compress, gzip Accept-Encoding: * Accept-Encoding: compress;q=0.5, gzip;q=1.0
Accept-Encoding: gzip;q=1.0, identity;q=0.5, *;q=0
其中"*"代表可以接收任务编码类型,如果客户端请求的时候没有使用Accept-Encoding首部,也即默认可以处理所有编码类型。
客户端可以给每种编码附带Q(质量)值参数来说明编码的优先级。
Q(0.0~1.0):0.0说明客户端不想接受所说明的编码
1.0则表明最希望使用的编码,
* 表示“任何其他方法”
identity编码代号只能在Accept-Encoding首部中出现,客户端用它来说明相对于其他内容编码算法的优先级
6. 传输编码和分块编码
6.1 传输编码
虽然这里的传输编码和前面介绍的内容编码都是用于对实体操作。但是两种编码的目的不太一样,内容编码一般是为了对内容进行压缩和转换等,而传输编码是为了其他一些架构的因素考虑进行使用,同内容的格式无关。同样两种编码对某些首部的影响也不一样,比如实体摘要Content-MD5,一般是用作于内容编码之后,传输编码之前。同样,如果一般代用传输编码后,Content-Length首部的值也通常会做忽略处理。
实际使用当中,一般传输编码主要用于解决报文未知大小和安全性的问题。不过由于安全性现在通常用HTTPS就能很好处理了。所以大多数时候传输编码就是用于解决报文未知大小的问题。比如一些动态生成的报文,如果不能生成完成我们就没法得知报文实体的大小,但是有时候我们又希望在完全生成完成之前就开始传输数据,提高效率。
HTTP协议中提供了Transfer-Encoding和TE两个首部用于控描述和控制传输编码。
- Transfer-Encoding 用于发送方告知接收方用了何种传输编码。
- TE和Accept-Encoding类似,用于请求手中,告之服务器可以使用哪些传输编码扩展
传输编码的值都是大小写无关的。
6.2 分块编码
目前HTTP规范中,仅仅定义了一种传输编码——分块编码。
分块编码把报文分割为若干个大小已知的块。块之间是紧挨着发送的,这样就不需要在发送之前知道整个报文的大小了,也就解决了我们上面提到的未知报文大小的问题。
注:分块编码是一种传输编码,因此是报文的属性,而不是主体的属性
在正常情况,如果不是使用的持久连接。那么客户端直接可以一直读取到连接关闭就意味着报文结束了。
但是如果是在持久连接中,如果事先不知道报文实体的大小。这个时候就可以使用分块编码。分块编码允许服务器把主体逐块发送,说明每块的大小就可以了。因为主体是动态创建的,服务器可以缓冲它的一部分,发送其大小和相应的块,然后在主体发送完之前重复这个过程。服务器可以用大小为 0 的块作为“主体结束”的信号,这样就可以继续保持连接,为下一个响应做准备。
如果客户端的 TE 首部中说明它可以接受拖挂的话,服务器就可以在分块的报文最后加上拖挂。不过该选项为可选选项,所以就看你是否需要了。比如我们可以在最后拖挂一个报文整个实体内容的校验和。客户端在接收完全部分块内容后,也可以计算出报文实体的校验和,然后进行对比,以验证报文内容的完整性。
我们在使用传输编码的时候,一定要注意遵守如下规则:
- 传输编码集合中必须包含“分块”,除非使用连接关闭来结束报文
- 当使用分块编码的时候,必须是最后一个作用到报文主体之上的
- 分块编码不能多次使用在同一个报文主体上
新鲜度
Expires(过期) :客户端和服务器为了能正确使用Expires首部,他们的时钟必须同步。
Cache-Control|(缓存控制):首部可以使用秒数来规定文档最长使用期---从文档离开服务器之后算起的总计时间
有条件的请求
仅当资源改变时才请求副本,这种特殊请求称为有条件的请求,有条件的请求是标准的HTTP请求报文
有条件的请求是通过以“If-” 开头的有条件的首部来实现的。
每个有条件的请求都通过特定的验证码来发挥作用,验证码是文档实例的一个特殊属性,用来测试条件是否为真
HTTP两种验证码
Last-Modified 和ETag
HTTP把验证码分为两类:
弱验证码(weak validators)
强验证码(strong validators)
7 范围请求
有些时候,我们并不需要请求一个完整的文档内容,可能只需要文档中的某个片段。比如在多线程下载的时候,可能每个线程都只需请求资源的部分内容即可。这个时候就可以利用范围请求来实现。HTTP中,通过Range首部实现范围请求。如下:
GET /bigfile.html HTTP/1.1 Host: www.joes-hardware.com Range: bytes=4000- ……
该示例中,客户端通过Range首部,告诉服务器我只要资源第4000字节以后的内容。这里我们不知道文档总的打下,所以可以通过不指定结尾字节数,告知服务器返回从4000到结尾的部分。如果你知道具体需要的范围,也可以指定具体的区间。
服务器可以通过在响应中包含Accept-Ranges首部的形式向客户端说明可以接受的访问请求
HTTP/1.0 206 Partial content Date:FRI, 05 Nov 1999 22:35:15 GMT Server:Apache/1.2.4 Accept-Ranges :bytes ...
8 差异编码
服务器上的文档并不是一层不变的,如果我们服务器上的文档发生了变化。客户端缓存了变化之前的文档内容,这个时候客户端发起请求的时候。如果把整个文档全部返回给客户端,那是很浪费资源的,特别是有时候改动很小的时候。这个时候如果我们可以只返回有改动(差异)的部分,客户端拿到这部分内容之后,将本地缓存更新后展示给用户即可。这样既节约资源,也能提高传输的速度。这种情况就可以利用差异编码实现。
差异编码是HTTP协议的一个扩展,它通过交换对象改变的部分而不是完整的对象来优化传输性能。
差异编码也是一类实例操控,因为它依赖客户端和服务器之间针对特定的对象实例来交换信息。
差异编码的过程如下图所示:
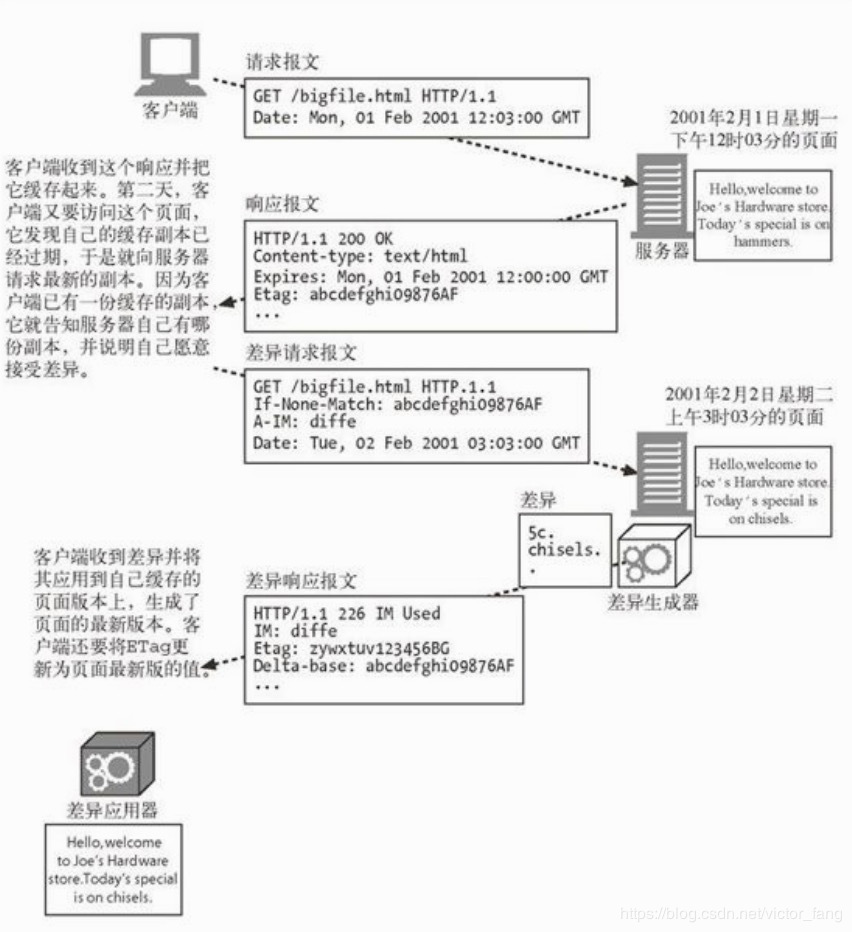
上图展示了差异编码的结构,包括请求、生成、接收和装配文档的全过程。
- 客户端必须告诉服务器它有页面的哪个版本,它愿意接受页面最新版的差异(delta),它懂得哪些将差异应用于现有版本的算法。
- 服务器必须检查它是否有这个页面的客户端现有版本,计算客户端现有版本与最新版之间的差异(有若干算法可以计算两个对象之间的差异)。
- 然后服务器必须计算差异,发送给客户端,告知客户端所发送的是差异,并说明最新版页面的新标识(ETag),因为客户端将差异应用于其老版本之后就会得到这个版本。
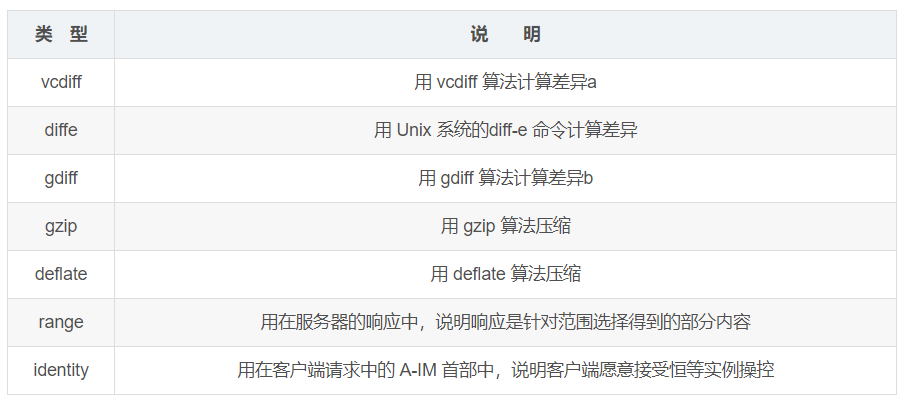
A-IM 是 Accept-Instance-Manipulation(接受实例操控)的缩写,用于告诉服务器可以接受差异的类型(算法)。服务器在响应中用IM首部告诉客户端,本次返回的差异数据是用的何种操作类型(算法)。
服务端发送:一个特殊的响应代码-----226 IM Used 告知客户端它正在发送的是所请求对象的实例操控,而不是那个完整的对象本身。
另外这里总结一下,目前在IANA中注册实例操作类型(不仅仅是差异操作类型,还包括前面的一些内容编码的操作)如下表所示: