一、组件
- Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
- Worker:工作进程,每个工作进程中都有多个Task。
- Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
- Topology:计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
- Stream:数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
- Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout可以发送多个数据流。
- Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
- Stream grouping:为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
- Reliability:可靠性。Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
二、架构
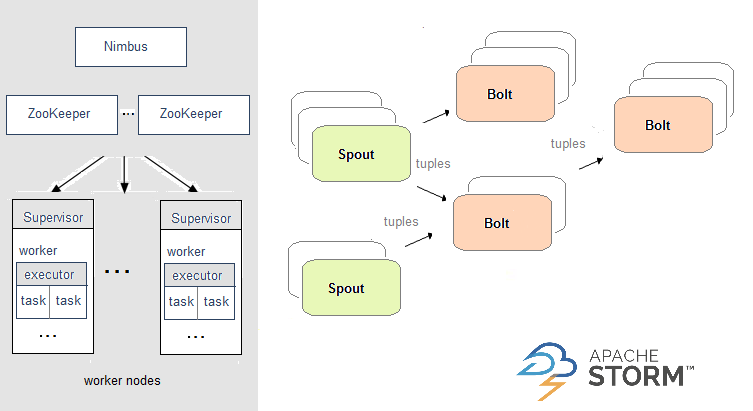
三、机制
1.数据流类型
(1) Spout -> Bolt
(2) Spout -> Bolt1 -> Bolt2 -> .. (即多层Bolt,把逻辑和算法分解成多个环节执行)
(3) Spout*n -> Bolt (即多个spout发数据给1个Bolt处理)
(4) Spout -> Bolt*n (即1个spout发数据给多个Bolt处理)
2.Grouping策略
Grouping策略就是在Spout与Bolt、Bolt与Bolt之间传递Tuple的方式
(1) shuffleGrouping(随机分组)
(2) fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
(3) allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)
(4) globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)
(5) noneGrouping(随机分派)
(6) directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
(7) Local or shuffle Grouping
(8) customGrouping (自定义的Grouping)
3.代码逻辑
(1) 创建任务拓扑Topology
Topology用于绑定任务和提交执行
(2) 绑定Spout类
Spout一般用于获取数据,并用turple把数据发送给Bolt
(3) 绑定Bolt类
Bolt一般是用户处理数据,可以有多层Bolt,即Bolt1处理完把结果发给Bolt2做下一步处理
(4) 提交Topology给Storm
(5) 打包成jar文件,发布到Storm环境运行
附录:
Storm的安装与部署
https://www.cnblogs.com/live41/p/15555719.html
Storm的开发使用