一、硬件环境
假设有4台机,IP及主机名如下:
192.168.100.105 c1 192.168.100.110 c2 192.168.100.115 c3 192.168.100.120 c4
假设全部大数据组件都部署在/home/目录,Kafka的topic名是clotho
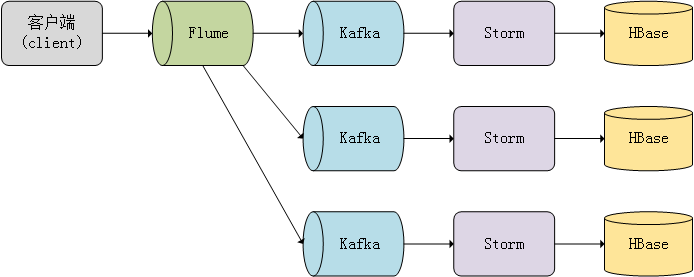
数据流图如下:
二、软件环境
操作系统:Ubuntu Server 18.04
JDK:1.8.0
1.安装JDK
https://www.cnblogs.com/live41/p/14235891.html
2.安装ZooKeeper
https://www.cnblogs.com/live41/p/15522363.html
3.安装Flume
https://www.cnblogs.com/live41/p/15554223.html
4.安装Kafka
https://www.cnblogs.com/live41/p/15522443.html
5.安装Hadoop
https://www.cnblogs.com/live41/p/15483192.html
6.安装HBase
https://www.cnblogs.com/live41/p/15494279.html
7.安装Storm
https://www.cnblogs.com/live41/p/15555719.html
三、整合Flume+Kafka
* 先登录root账号再进行以下操作
1.先进行Flume+Kafka的整合操作
https://www.cnblogs.com/live41/p/15554269.html
2.完成第1点,还需要追加一些操作
* 只需要在c1机执行
(1) 修改Flume配置文件
vim /home/flume/conf/flume-conf
这里是用Java通过Flume API发送数据,所以要把flume-conf中的a1.sources.r1.type修改为avro
a1.sources.r1.type = avro
这里假设Kafka使用的topic名是clotho,需要把flume-conf中的a1.sinks.k1.topic修改为clotho
a1.sinks.k1.topic = clotho
保存退出。
(2) 创建Kafka的topic
topic名是clotho,分区是8个,副本是2个
kafka-topics.sh --create --bootstrap-server c1:9092 --topic clotho --partitions 8 --replication-factor 2
四、启动服务
* 如果前面根据资料操作时已启动,可跳过这步
* 提醒:要按顺序启动
1.启动ZooKeeper
* 只在c1机操作
zkServer.sh start
2.启动Hadoop
* 只在c1机操作
start-all.sh
3.启动HBase
* 只在c1机操作
* 启动完后Hadoop后,最好等10秒以上再启动HBase,否则会有一定概率的启动异常。
start-hbase.sh
如果启动过程中,有服务没启动成功,可以手动启动具体服务
hbase-daemon.sh start master hbase-daemon.sh start regionserver
4.启动Kafka
* 所有机器都要操作一遍
* 如果先启动Flume的话,会因为找不到Kafka监听服务而一直报错。
kafka-server-start.sh -daemon /home/kafka/config/server.properties
5.启动Flume
* 只在c1机操作
flume-ng agent -c conf -f /home/flume/conf/flume-conf -n a1 -Dflume.root.logger=INFO,console &
6.启动Storm的Nimbus及WebUI
* 只在c1机操作
storm nimbus &
storm ui &
7.启动Storm的Supervisor
* 所有机器都要操作一遍
storm supervisor &
五、HBase创建数据表
假定表名是message,列族是content,列是text
1.登入HBase
hbase shell
2.创建数据表
create 'message', 'content'
3.测试
list describe 'message'
4.退出HBase
exit
六、开发Storm程序
建议使用IDEA
1.新建Maven项目
为了与下面的命令一致,项目名用Dataflow
2.修改pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.clotho</groupId> <artifactId>Dataflow</artifactId> <version>1.0</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <build> <finalName>Dataflow</finalName> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <appendAssemblyId>false</appendAssemblyId> <archive> <manifest> <mainClass>com.clotho.hadoop.DataflowTopology</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>2.4.7</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>2.3.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>2.3.0</version> </dependency> </dependencies> </project>
在IDEA中使用maven-assembly-plugin插件时会提示“Plugin 'maven-assembly-plugin:' not found”
解决方法:https://www.cnblogs.com/live41/p/15591217.html
3.新建package
包名为com.clotho.hadoop
4.新建Bolt类
类名为DataflowBolt,代码如下:
package com.clotho.hadoop; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import org.apache.storm.task.GeneralTopologyContext; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.MessageId; import org.apache.storm.tuple.Tuple; import org.apache.velocity.runtime.directive.Foreach; import java.util.List; import java.util.Map; public class DataflowBolt extends BaseRichBolt { private Connection connection; private final String quorum = "c1,c2,c3"; private final String tableName = "message"; private final String columnFamily = "content"; private final String column = "text"; private int count = 0; @Override public void prepare(Map map, TopologyContext context, OutputCollector collector) { try { Configuration config = HBaseConfiguration.create(); config.set("hbase.zookeeper.quorum", quorum); connection = ConnectionFactory.createConnection(config); } catch (Exception e) { e.printStackTrace(); } } @Override public void execute(Tuple tuple) { count++; String row = "id." + count; String value = tuple.getStringByField("value"); // String topic = tuple.getStringByField("topic"); // value = "#" + topic + "#" + "[" + value + "]"; try (Table table = connection.getTable(TableName.valueOf(tableName))) { Put put = new Put(Bytes.toBytes(row)); put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value)); table.put(put); } catch (Exception e) { e.printStackTrace(); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } @Override public void cleanup() { if (connection != null) { try { connection.close(); } catch (Exception e) { e.printStackTrace(); } } } }
5.新建Topology类
类名为DataflowTopology,代码如下:
package com.clotho.hadoop; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.kafka.spout.KafkaSpout; import org.apache.storm.kafka.spout.KafkaSpoutConfig; import org.apache.storm.topology.TopologyBuilder; public class DataflowTopology { public static void main(String[] args) { String spoutID = "Kafka"; String boltID = "HBase"; String kafkaServer = "c1:9092"; String kafkaTopic = "clotho"; TopologyBuilder builder = new TopologyBuilder(); builder.setSpout(spoutID, GetKafkaSpout(kafkaServer, kafkaTopic)); builder.setBolt(boltID, new DataflowBolt(), 1).setNumTasks(1).shuffleGrouping(spoutID); Config config = new Config(); try { if (args != null && args.length > 0) { StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } else { StormSubmitter.submitTopology("Dataflow", config, builder.createTopology()); // LocalCluster cluster = new LocalCluster(); // cluster.submitTopology("Dataflow", config, builder.createTopology()); // Thread.sleep(60000); // cluster.shutdown(); } } catch (Exception e) { e.printStackTrace(); } } private static KafkaSpout<String, String> GetKafkaSpout(String servers, String topics) { KafkaSpoutConfig.Builder<String, String> builder = KafkaSpoutConfig.builder(servers, topics); builder.setProp(ConsumerConfig.GROUP_ID_CONFIG, "sinensis"); // builder.setProp("enable.auto.commit", "true"); // builder.setProp(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); // builder.setProp(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); // builder.setProp(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); // builder.setOffsetCommitPeriodMs(1000); // builder.setFirstPollOffsetStrategy(KafkaSpoutConfig.DEFAULT_FIRST_POLL_OFFSET_STRATEGY.UNCOMMITTED_LATEST); builder.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); builder.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); // builder.setTupleTrackingEnforced(true); // builder.setProp("max-poll-records", 100); // builder.setProp(ProducerConfig.ACKS_CONFIG, "all"); // builder.setProp("enable.idempotence", "true"); // builder.setProp(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");d builder.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_MOST_ONCE); KafkaSpoutConfig<String, String> config = builder.build(); KafkaSpout<String, String> spout = new KafkaSpout<String, String>(config); return spout; } }
6.新建Flume的发送数据类
用于发送测试数据到Flume
类名为FlumeSender,代码如下:
package com.clotho.hadoop; import org.apache.flume.api.RpcClient; import org.apache.flume.api.RpcClientFactory; import org.apache.flume.event.EventBuilder; import java.nio.charset.StandardCharsets; public class FlumeSender { public static void main(String[] args) { RpcClient client = null; String hostname = "c1"; int port = 44444; String template = "message - NO."; try { client = RpcClientFactory.getDefaultInstance(hostname, port); for (int i = 1; i <= 10; i++) { client.append(EventBuilder.withBody(template + i, StandardCharsets.UTF_8)); } } catch (Exception e) { e.printStackTrace(); } if (client != null) { try { client.close(); } catch (Exception e) { e.printStackTrace(); } } } }
7.编译
打开IDEA下面的Terminal选项卡(或用命令行进入项目根目录),输入以下命令:
mvn assembly:assembly
七、运行测试
1.上传jar包到服务器
jar包在\Dataflow\target\目录中,文件名是Dataflow.jar
rz
2.发布jar包到Storm
发布后是激活状态,会自动持续运行
storm jar Dataflow.jar com.clotho.hadoop.DataflowTopology
3.发送测试数据
运行上面的FlumeSender类
4.测试
(1) 在Kafka测试
kafka-console-consumer.sh --bootstrap-server c1:9092 --topic clotho --from-beginning
(2) 在HBase测试
登入HBase
hbase shell
scan 'message'
看到测试数据全部入库即为成功。
八、关闭服务
* 提醒:要按顺序关闭
1.关闭Storm的WebUI
* 只在c1机操作
ps -ef|grep UIServer|grep -v grep|awk '{print $2}'|xargs kill -9
2.关闭Storm的Supervisor
* 所有机器都要操作一遍
ps -ef|grep Supervisor|grep -v grep|awk '{print $2}'|xargs kill -9
3.关闭Storm的Nimbus
* 只在c1机操作
ps -ef|grep Nimbus|grep -v grep|awk '{print $2}'|xargs kill -9
4.关闭Flume
* 只在c1机操作
ps -ef|grep Application|grep -v grep|awk '{print $2}'|xargs kill -9
5.关闭Kafka
* 所有机器都要操作一遍
kafka-server-stop.sh
6.关闭HBase
* 只在c1机操作
stop-hbase.sh
如果关闭过程中,等待“...”超过30秒,可以ctrl+c退出,然后手动关闭具体服务
hbase-daemon.sh stop master hbase-daemon.sh stop regionserver
7.关闭Hadoop
* 只在c1机操作
stop-all.sh
8.关闭ZooKeeper
* 所有机器都要操作一遍
zkServer.sh stop
9.检查是否全部关闭
jps
如果显示的结果只剩下jps服务,就是全部关闭了