一.今日内容大纲
常用模块的介绍:
- time,datetime
- os,sys
- hashlib,json,pickle,collections
二.昨日内容以及作业讲解
- 自定义模块
- 模块的两种执行方式
- __name__``__file__ , __all__
- 模块导入的多种方式
- 相对导入
- random:
- random.random():
- random.uniform(a,b):
- random.randint(a,b):
- random.shuffle(x):
- random.sample(x,k):
三.具体内容
1.time:和时间相关
封装了获取时间戳和字符串形式的时间的一些方法。
- time.time():获取时间戳
- time.gmtime([seconds]):获取格式化时间对象:是九个字段组成的
- time.localtime([seconds]):获取格式化时间对象:是九个字段组成的
- time.mktime(t):时间对象 -> 时间戳
- time.strftime(format[,t]):把时间对象格式化成字符串
- time.strptime(str,format):把时间字符串转换成时间对象
""" time 模块 三大对象: 时间戳 结构化时间对象(9大字段) 字符串!!!! """ import time # 获取时间戳 # 时间戳:从时间元年(1970 1 1 00:00:00)到现在经过的秒数。 # print(time.time()) # 1558314075.7787385 1558314397.275036 # 获取格式化时间对象:是九个字段组成的。 # 默认参数是当前系统时间的时间戳。 # print(time.gmtime()) # GMT: # print(time.localtime()) # print(time.gmtime(1)) # 时间元年过一秒后,对应的时间对象 # 时间对象 -> 时间戳 # t1 = time.localtime() # 时间对象 # t2 = time.mktime(t1) # 获取对应的时间戳 # print(t2) # print(time.time()) # 格式化时间对象和字符串之间的转换 # s = time.strftime("year:%Y %m %d %H:%M:%S") # print(s) # 把时间字符串转换成时间对象 # time_obj = time.strptime('2010 10 10','%Y %m %d') # print(time_obj) # 暂停当前程序,睡眠xxx秒 # time.sleep(xxx) # for x in range(5): # print(time.strftime('%Y-%m-%d %H:%M:%S')) # # 休眠一秒钟 # time.sleep(1)
time模块三大对象之间的转换关系:

其他方法:
- time.sleep(x):休眠x秒.
2.datetime:日期时间相关
包含了和日期时间相关的类.主要有:
- date:需要年,月,日三个参数
- time:需要时,分,秒三个参数
- datetime:需要年,月,日,时,分,秒六个参数.
- timedelta:需要一个时间段.可以是天,秒,微秒.
获取以上类型的对象,主要作用是和时间段进行数学运算.
timedelta可以和以下三个类进行数学运算:
- datetime.time,datetime.datetime,datetime.timedelta
""" datetime:日期时间模块 封装了一些和日期,时间相关的类. date time datetime timedelta """ import datetime # date类: # d = datetime.date(2010,10,10) # print(d) # # 获取date对象的各个属性 # print(d.year) # print(d.month) # print(d.day) # time类: # t = datetime.time(10,48,59) # print(t) # # time类的属性 # print(t.hour) # print(t.minute) # print(t.second) # datetime # dt = datetime.datetime(2010,11,11,11,11,11) # print(dt) # datetime中的类,主要是用于数学计算的. # timedelta:时间的变化量 # td = datetime.timedelta(days=1) # # print(td) # # 参与数学运算 # # 创建时间对象: # # 只能和以下三类进行数学运算: date,datetime,timedelta # d = datetime.date(2010,10,10) # res = d - td # print(res) # 时间变化量的计算是否会产生进位? # t = datetime.datetime(2010,10,10,10,10,59) # td = datetime.timedelta(seconds=3) # res = t + td # print(res) # t = datetime.datetime(2010,10,10,10,10,00) # td = datetime.timedelta(seconds=3) # res = t - td # print(res) # 练习:计算某一年的二月份有多少天. # 普通算法:根据年份计算是否是闰年.是:29天,否:28 # 用datetime模块. # 首先创建出指定年份的3月1号.然后让它往前走一天. year = int(input("输入年份:")) # 创建指定年份的date对象 d = datetime.date(year, 3, 1) # 创建一天 的时间段 td = datetime.timedelta(days=1) res = d - td print(res.day) # 和时间段进行运算的结果 类型:和另一个操作数保持一致 # d = datetime.date(2010,10,10) # d = datetime.datetime(2010,10,10,10,10,10) # d = datetime.timedelta(seconds=20) # td = datetime.timedelta(days=1) # res = d + td # print(type(res))
3.os模块
和操作系统相关的模块,主要是文件删除,目录删除,重命名等操作.
""" os:和操作系统相关的操作被封装到这个模块中. """ import os # 和文件操作相关,重命名,删除 # os.remove('a.txt') # os.rename('a.txt','b.txt') # 删除目录,必须是空目录 # os.removedirs('aa') # 使用shutil模块可以删除带内容的目录 # import shutil # shutil.rmtree('aa') # 和路径相关的操作,被封装到另一个子模块中:os.path # res = os.path.dirname(r'd:/aaa/bbb/ccc/a.txt') # 不判断路径是否存在. # print(res) # # # 获取文件名 # res = os.path.basename(r'd:/aaa/bbb/ccc/a.txt') # print(res) # 把路径中的路径名和文件名切分开,结果是元组. # res = os.path.split(r'd:/aaa/bbb/ccc/a.txt') # print(res) # 拼接路径 # path = os.path.join('d:\','aaa','bbb','ccc','a.txt') # print(path) # 如果是/开头的路径,默认是在当前盘符下. # res = os.path.abspath(r'/a/b/c') # 如果不是以/开头,默认当前路径 # res = os.path.abspath(r'a/b/c') # print(res) # 判断 # print(os.path.isabs('a.txt')) # print(os.path.isdir('d:/aaaa.txt')) # 文件不存在.False # print(os.path.exists('d:/a.txt')) # print(os.path.isfile('d:/asssss.txt')) # 文件不存在.False
4.sys模块
和解释器操作相关的模块.
主要两个方面:
- 解释器执行时获取参数:sys.argv[x]
- 解释器执行时寻找模块的路径:sys.path
例如:有a.py内容如下:
import sys print('脚本名称:',sys.argv[0]) print('第一个参数:',sys.argv[1]) print('第二个参数:',sys.argv[2])
使用脚本方式运行:
python a.py hello world
""" 和python解释器相关的操作 """ # 获取命令行方式运行的脚本后面的参数 import sys # print("脚本名:",sys.argv[0]) # 脚本名 # print("第一个参数:",sys.argv[1]) # 第一个参数 # print("第二个参数:",sys.argv[2]) # 第二个参数 # print(type(sys.argv[1])) # str # arg1 = int(sys.argv[1]) # arg2 = int(sys.argv[2]) # print(arg1 + arg2) # 解释器寻找模块的路径 # sys.path # 已经加载的模块 # print(sys.modules)
5.json模块
JavaScript Object Notation:java脚本兑现标记语言.
已经成为一种简单的数据交换格式.
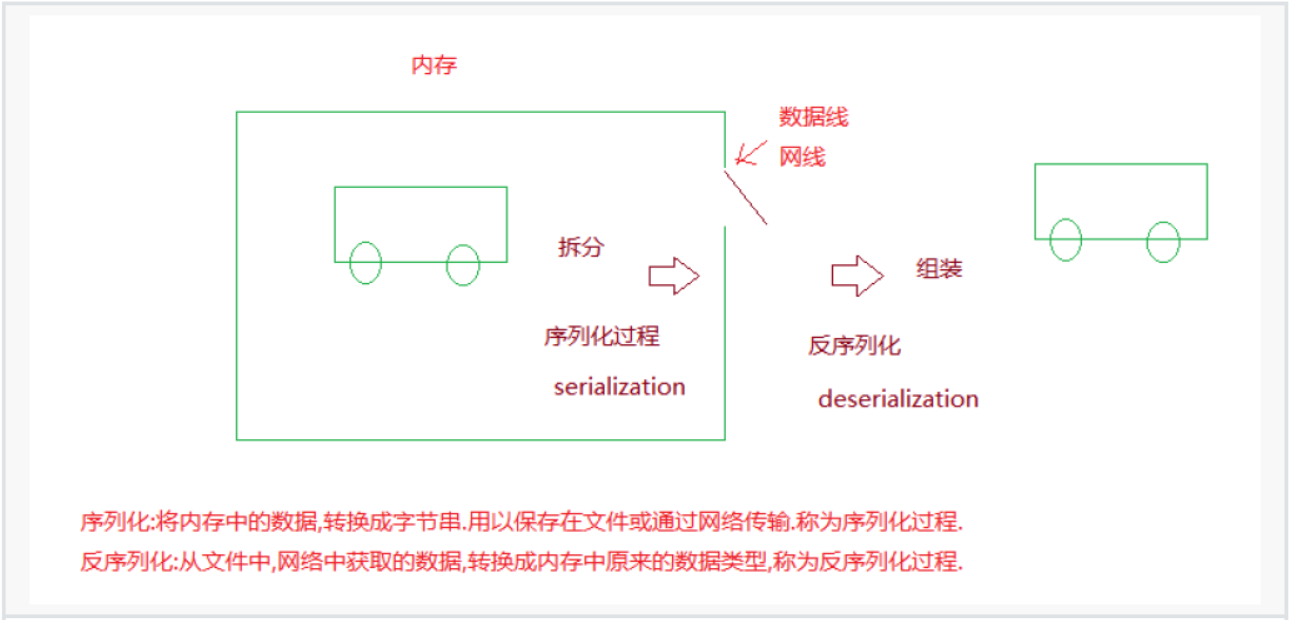
序列化:将其他数据格式转换成json字符串的过程.
反序列化:将json字符串转换其他数据类型的过程.
涉及到的方法:
- json.dumps(obj):将obj转换成json字符串返回到内存中.
- json.dump(obj,fp):将obj转换成json字符串并保存在fp指向的文件中.
- json.loads(s):将内存中的json字符串转换成对应的数据类型对象
- json.load(f):从文件中读取json字符串,并转换回原来的数据类型.
注意:
- json并不能序列化所有的数据类型:例如:set.
- 元组数据类型经过json序列化后,变成列表数据类型.
- json文件通常是一次性写入,一次性读取.但是可以利用文件本身的方式实现:一行存储一个序列化json字符串,在反序列化时,按行反序列化即可.
内存中的数据:结构化的数据
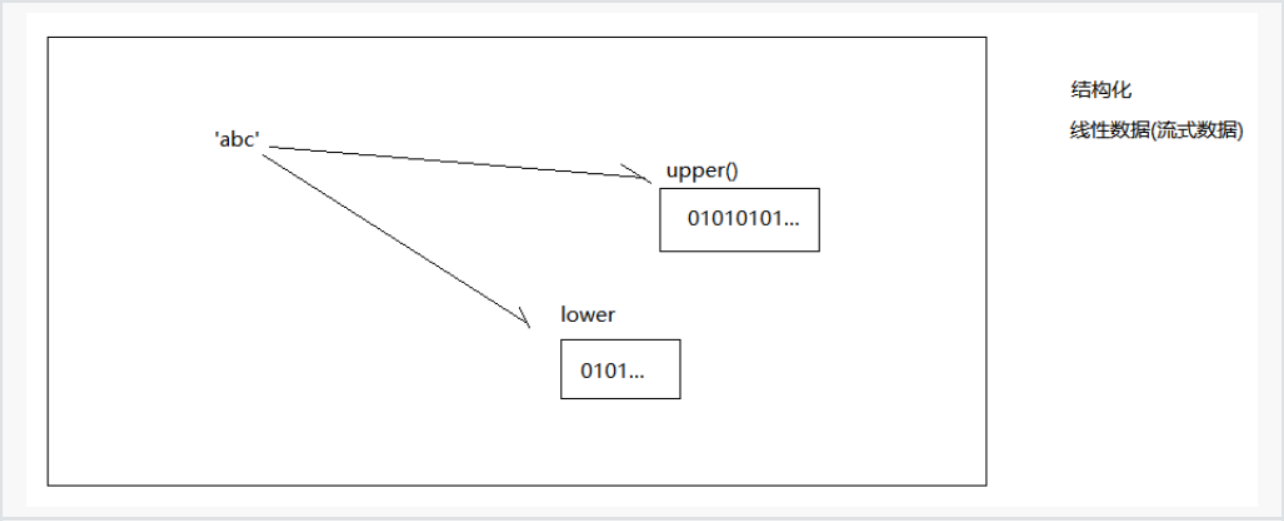
磁盘上的数据:线性数据.
序列化比喻:
""" 序列化: 把内存中的数据,转换成字节或字符串的形式,以便于进行存储或者 网络传输. 内存中数据 -> 字节串/字符串 : 序列化 字节串/字符串 -> 内存中的数据 : 反序列化 """ # json :将数据转换成字符串,用于存储或网络传输. import json # s = json.dumps([1,2,3]) # 把指定的对象转换成json格式的字符串 # print(type(s)) # print(s) # '[1,2,3]' [1,2,3] # # s = json.dumps((1,2,3)) # 元组序列化后,变成列表 # print(s) # res = json.dumps(10) # print(res) # '10' # res = json.dumps({'name':'Andy','age':10}) # print(res) # {"name": "Andy", "age": 10} # res = json.dumps(set('abc')) # Object of type 'set' is not JSON serializable # 将json结果写到文件中 # with open('a.txt',mode='at',encoding='utf-8') as f: # json.dump([1,2,3],f) # 反序列化 # res = json.dumps([1,2,3]) # lst = json.loads(res) # 反序列化 # print(type(lst)) # print(lst) # 元组会变成列表 # res = json.dumps((1,2,3)) # lst = json.loads(res) # 反序列化 # print(type(lst)) # print(lst) # 从文件中反序列化 # with open('a.txt',encoding='utf-8')as f: # res = json.load(f) # print(type(res)) # print(res) # json # json.dumps(obj) # json.dump(obj,f) # json.loads(s) # json.load(f) # json文件通常是一次性写,一次性读. # 使用另一种方式,可以实现多次写,多次读. # 把需要序列化的对象.通过多次序列化的方式, 用文件的write方法,把多次序列化后的json字符串 # 写到文件中. # with open('json.txt',mode='at',encoding='utf-8') as f: # f.write(json.dumps([1,2,3]) + ' ') # f.write(json.dumps([4,5,5]) + ' ') # 把分次序列化的json字符串,反序列化回来 with open('json.txt',mode='rt',encoding='utf-8') as f: # res = json.loads(f.readline().strip()) # print(res) # res2 = json.loads(f.readline().strip()) # print(res2) # 使用循环改进: for x in f: print(json.loads(x.strip()))
6.pickle模块
python专用的序列化模块.
和json的方法一致.
区别在于:
json:
- 不是所有的数据类型都可以序列化.结果是字符串.
- 不能多次对同一个文件序列化.
- json数据可以跨语言
pickle:
- 所有python类型都能序列化,结果是字节串.
- 可以多次对同一个文件序列化
- 不能跨语言.
""" pickle: 将Python中所有的数据类型.转换成字节串.序列化过程 将字节串转换成python中数据类型,反序列化过程. """ import pickle # # bys = pickle.dumps([1,2,3]) # print(type(bys)) # <class 'bytes'> # print(bys) # b'x80x03]qx00(Kx01Kx02Kx03e.' # 保存了元组的数据类型 # bys = pickle.dumps((1,2,3)) # # print(bys) # # # res = pickle.loads(bys) # print(type(res)) # 所有的数据类型都可以进行序列化 # bys = pickle.dumps(set('abc')) # res = pickle.loads(bys) # print(type(res)) # 把pickle序列化内容写入文件中 # with open('c.txt',mode='wb') as f: #mode下wb中,w代表操作方向,b代表操作单位 # pickle.dump([1,2,3],f) # 从文件中反序列化pickle数据 # with open('c.txt',mode='rb') as f: # res = pickle.load(f) # print(type(res)) # print(res) # 多次pickle数据到同一个文件中 # with open('c.txt',mode='ab') as f: # pickle.dump([1,2,3],f) # pickle.dump([1,2,3],f) # pickle.dump([1,2,3],f) # 从文件中反序列化pickle数据 # with open('c.txt',mode='rb') as f: # for x in range(4): # res = pickle.load(f) # print(res) # pickle常用场景:和json一样,一次性写入,一次性读取. # json,pickle的比较: """ json: 1.不是所有的数据类型都可以序列化.结果是字符串. 2.不能多次对同一个文件序列化. 3.json数据可以跨语言 pickle: 1.所有python类型都能序列化,结果是字节串. 2.可以多次对同一个文件序列化 3.不能跨语言. """
7.hashlib模块
封装一些用于加密的类.
md5(),...
加密的目的:用于判断和验证,而并非解密.
import hashlib print(dir(hashlib)) # 输出结果如下: ''' ['__all__', '__builtin_constructor_cache', '__builtins__', '__cached__', '__doc__', '__file__', '__get_builtin_constructor', '__loader__', '__name__', '__package__', '__spec__', '_hashlib', 'algorithms_available', 'algorithms_guaranteed', 'blake2b', 'blake2s', 'md5', 'new', 'pbkdf2_hmac', 'scrypt', 'sha1', 'sha224', 'sha256', 'sha384', 'sha3_224', 'sha3_256', 'sha3_384', 'sha3_512', 'sha512', 'shake_128', 'shake_256'] '''
特点:
- 把一个大的数据,切分成不同块,分别对不同的块进行加密,再汇总的结果,和直接对整体数据加密的结果是一致的.
- 单向加密,不可逆.
- 原始数据的一点小的变化,将导致结果的非常大的差异,'雪崩'效应.
""" md5加密算法: 给一个数据加密的三大步骤: 1.获取一个加密对象 2.使用加密对象的update,进行加密,update方法可以调用多次 3.通常通过hexdigest获取加密结果,或digest()方法. """ import hashlib # 获取一个加密对象 # m = hashlib.md5() # # 使用加密对象的update,进行加密 # m.update('abc中文'.encode('utf-8')) # m.update('def'.encode('utf-8')) # 通过hexdigest获取加密结果 # res = m.hexdigest() # res = m.digest() # print(res) # 1af98e0571f7a24468a85f91b908d335 # 给一个数据加密, # 验证:用另一个数据加密的结果和第一次加密的结果对比. # 如果结果相同,说明原文相同.如果不相同,说明原文不同. # 不同加密算法:实际上就是加密结果的长度不同; # s = hashlib.sha224() # s.update(b'abc') # print(len(s.hexdigest())) # # print(len(hashlib.md5().hexdigest())) # print(len(hashlib.sha224().hexdigest())) # print(len(hashlib.sha256().hexdigest())) # 在创建加密对象时,可以指定参数,称为salt. # m = hashlib.md5(b'abc') # print(m.hexdigest()) # # m = hashlib.md5() # m.update(b'abc') # print(m.hexdigest()) # m = hashlib.md5() # m.update(b'abc') # m.update(b'def') # print(m.hexdigest()) # # # # m = hashlib.md5() # m.update(b'abcdef') # print(m.hexdigest()) # 注册,登录程序: def get_md5(username,passwd): m = hashlib.md5(username[::-1].encode('utf-8')) m.update(username.encode('utf-8')) m.update(passwd.encode('utf-8')) return m.hexdigest() def register(username,passwd): # 加密 res = get_md5(username,passwd) # 写入文件 with open('login',mode='at',encoding='utf-8') as f: f.write(res) f.write(' ') # username:xxxxxx def login(username,passwd): # 获取当前登录信息的加密结果 res = get_md5(username, passwd) # 读文件,和其中的数据进行对比 with open('login',mode='rt',encoding='utf-8') as f: for line in f: if res == line.strip(): return True else: return False while True: op = int(input("1.注册 2.登录 3.退出")) if op == 3 : break elif op == 1: username = input("输入用户名:") passwd = input("输入密码:") register(username,passwd) elif op == 2: username = input("输入用户名:") passwd = input("输入密码:") res = login(username,passwd) if res: print('登录成功') else: print('登录失败')
不同的加密对象,结果长度不同,长度越长,越耗时.常用的是md5.
8.collections模块
此模块定义了一些内置容器类数据类型之外,可用的集合类数据类型.
往往针对的是特殊的应用场景.
""" collections模块 namedtuple():命名元组 defaultdict():默认值字典. Counter():计数器 """ from collections import namedtuple, defaultdict, Counter # namedtuple() # Rectangle = namedtuple('Rectangle_class',['length','width']) # # # r = Rectangle(10,5) # # 通过属性访问元组的元素 # print(r.length) # print(r.width) # # # 通过索引的方式访问元素 # print(r[0]) # print(r[1]) # defautldict: # 创建一个字典的方式: # d = {'name':'Andy','age':10} # d = dict([('name','Andy'),('age',10)]) # d = {k:v for k,v in [(1,2),(3,4)]} # print(d) # defaultdict() # d = defaultdict(int,name='Andy',age=10) # print(d['name']) # print(d['age']) # print(d['addr']) # {'addr':0} 也会被添加 # print(d) # 自定义函数充当第一个参数: # 要求,不能有参数 # def f(): # return 'hello' # # d = defaultdict(f,name='Andy',age=10) # print(d['addr']) # print(d) # Counter:计数器 c = Counter('abcdefabccccdd') print(c) print(c.most_common(3))
四.今日总结
- time:和时间相关
- datetime:日期时间相关
- os:和操作系统相关
- sys:和解释器相关
- json:和操作JSON(一种数据交换格式)相关
- pickle:序列化
- hashlib:加密算法
- Collections:集合类型
总结:
自定义模块
random
time
datetime
os
sys
json,pickle
hashlib
collections