4-23
现在无论原生还是网页端,表情符号绝大部分都可以正常显示,但是也有一部分是不能正常显示的。但存入到mysql的时候,不能够正常显示的表情符号,就会让mysql(utf-8)拜拜了。这个不仅仅是显示问题,很重要的一点是,会让绝大部分玩家的游戏记录被无情抹去,无法记录。
先举两个例子:
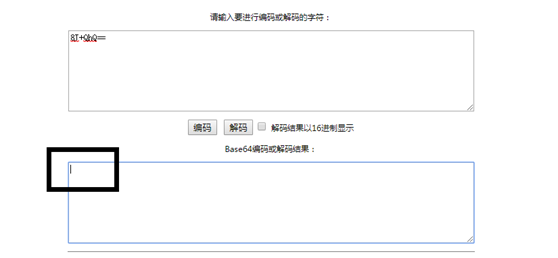
微信名:  base64加密后:8J+Xrw==
base64加密后:8J+Xrw==
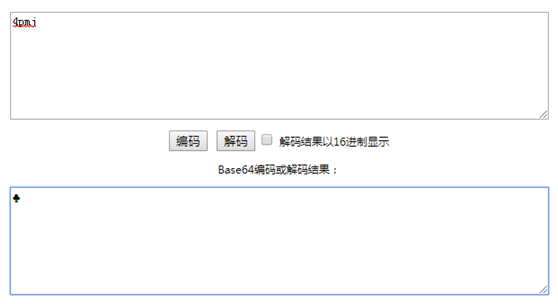
微信名:  base64加密后:4pmj
base64加密后:4pmj
第一个名字,算是一个比较新的表情符号,我参考了TX的游戏,
在王者荣耀上面,在S10赛季前,这个表情符号是用两个特殊字符来表现的(忘了截图),大概就是这样的吧
,而S11赛季更新之后就变成这样显示了
,而且,以前的表情符号在王者荣耀里面是可以输入的,现在已经禁止输入表情
符号了,现在统一由这个字符代表表情符号 。
。
表情符号的处理还有待改进呀
占2个字节的:带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、
叙利亚文及它拿字母则需要二个字节编码
占3个字节的:基本等同于GBK,含21000多个汉字
占4个字节的:中日韩超大字符集里面的汉字,有5万多个
再来看看这个表情符号的base64解码,能够正常显示
但是 这个就挂了,完全显示不出来
这个就挂了,完全显示不出来
下面就来看看,解密后他是个什么东西
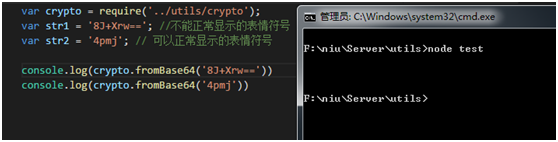



不能正常显示的表情符号解密后长度为2,能正常显示的就是1
再来看看他们的Unicode编码(charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数),看起来也没什么大的区别。但是长度却不同,UTF-8编码有可能是两个、三个、四个字节,Emoji表情是4个字节,而MySQL的utf8编码最多3个字节,所以数据插不进去,这就导致了数据腰斩的问题,数据都被这个不能插入的东西切成两份了。
接下来翻查一下这两个表情,
输入55357(不显示的表情的第一个字符),显示如下:

长度为2的字符串(显示不出来的表情符号),我们可以这样理解,它里面有两个字符(55357和56815),每一个字符转出来有三个字符,长度达到了3,那就是55357这个字符占了9个字节 ,就是说他一个字符占位已经超出了3字节的长度了 (本人的理解下,只是猜测)。
输入9827(♣),显示如下:
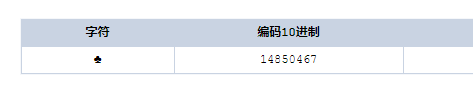

以上是长度为1的字符串,我们可以这样理解,那他占了3个字节,完全可以显示和存储在utf-8的数据结构里。
再看一下普通汉字的字节占位

也是可以显示的。
来看看游戏数据库里游戏记录的数据结构:

Utf-8/不区分大小写,可以,那样这个结构就会被我那个表情搞死了。
很明显,一些比较新的表情符号,是超过了3个字节的,所以就会出现类似以下的腰斩数据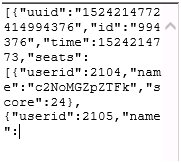
, name的值和后面的数据已经被KO了,而这个问题不仅仅是影响使用这个名字的玩家,而是和他一起游戏过的玩家也会出现数据腰斩的情况,所以这个问题必须要解决。
在网上搜不到相关的文章,对特殊表情符号的处理而又是少之又少,没什么有价值的参考的话,那就自己来一下吧,首先我可以想到的方案:
- 把特殊表情符号替换掉,或者屏蔽掉
- 看看能不能转换一下编码
- 看看能不能换一种加解密
第一种情况,体验太不好了,在大厅明明能把表情显示出来,但是战绩却看不到?不行。第三种呢,貌似很大工程,这个以后在探讨。比较适合的,简便的应该是第二种了,直接在数据库上面操作,好了,现在开始动数据库吧。
我上网搜一下utf-8和utf-8mb4的区别,这个是肯定有详细的文案可以查看的。
送上地址:http://blog.xieyc.com/utf8-and-utf8mb4/ 摘要:
二、为什么会有UTF8MB4?
既然utf8应付日常使用完全没有问题,那为什么还要使用utf8mb4呢? 低版本的MySQL支持的utf8编码,最大字符长度为 3 字节,如果遇到 4 字节的字符就会出现错误了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xFFFF,也就是 Unicode 中的基本多文平面(BMP)。也就是说,任何不在基本多文平面的 Unicode字符,都无法使用MySQL原有的 utf8 字符集存储。这些不在BMP中的字符包括哪些呢?最常见的就是Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和一些不常用的汉字,以及任何新增的 Unicode 字符等等。
三、扩展阅读:UTF-8编码
理论上将, UTF-8 格式使用一至六个字节,最大能编码 31 位字符。最新的 UTF-8 规范只使用一到四个字节,最大能编码21位,正好能够表示所有的 17个 Unicode 平面。关于UTF编码,请阅读《常见编码总结》一文。
而utf8 则是 Mysql 早期版本中支持的一种字符集,只支持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多文本平面。这可能是因为在MySQL发布初期,基本多文种平面之外的字符确实很少用到。而在MySQL5.5.3版本后,要在 Mysql 中保存 4 字节长度的 UTF-8 字符,就可以使用 utf8mb4 字符集了。例如可以用utf8mb4字符编码直接存储emoj表情,而不是存表情的替换字符。为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8,事实上,最新版的phpmyadmin默认字符集就是utf8mb4。诚然,对于 CHAR 类型数据,使用utf8mb4 存储会多消耗一些空间
-----------------------------------------------------------------------------------------------
上面说的很清楚:utf8编码,最大字符长度为 3 字节,如果遇到 4 字节的字符就会出现错误了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xFFFF,也就是 Unicode 中的基本多文平面(BMP)。也就是说,任何不在基本多文平面的 Unicode字符,都无法使用MySQL原有的 utf8 字符集存储。这些不在BMP中的字符包括哪些呢?最常见的就是Emoji 表情。
这下就应该选对方案了,一切都是从打印出解密后的字符的长度引发的思考。