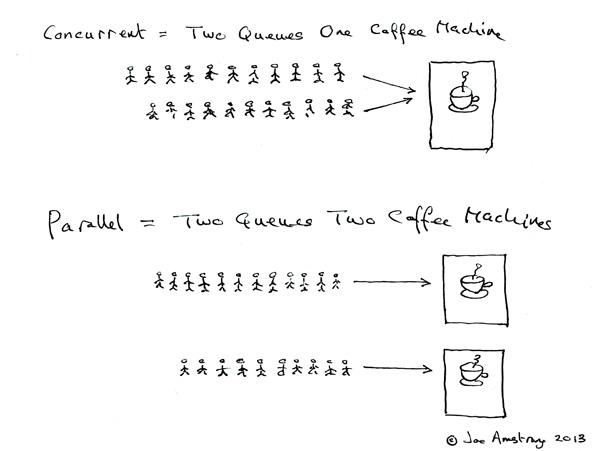
关于并发,百科中给出的精准的定义:“ 在计算机科学中,并行性(英语:Concurrency)是指在一个系统中,拥有多个计算,这些计算有同时执行的特性,而且他们之间有着潜在的互动。因此系统可进行的执行路径会有相当多个,而且结果可能具有不确定性。并发计算可能会在具备多核心的同一个晶片中复合运行,以优先分时线程在同一个处理器中执行,或在不同的处理器执行”。这里强调一下,“并发”不是“并行”,或者说“并发”仅仅是“并行”的一个子集,具有并行的“表面特性”,然而概念上是不同的,可以用下图简单说明一下:
并发的优点就不赘述了,主要想介绍一下并发编程相关的技术点。并发常规做法主要有:多进程、单进程多线程、多路复用等,无论哪种方案都存在资源竞争问题,以多线程为例,介绍一下如何保证并发安全性问题,传统的手段:锁、原子操作等,当然传统的手段很难保证开发效率,于是有涌现了很多更高级的并发方案,如Actor、CSP并发模型等,下面简单介绍一下。
一.传统的“锁”机制
前辈们为了做高性能并发也是费尽苦心了,提出了各种锁来保证并发的效率和安全性,常见的锁:互斥锁(Mutex)、信号量(Semaphore)、读写锁(RWLock)、条件变量(Cond)、临界区(Critical Section)
1.信号量
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施,是可以用来保证两个或多个关键代码段不被并发调用,核心的三个方法签名:
#include <semaphore.h> //初始化一个信号量,Value指该资源可被同时使用的个数 int sem_init(sem_t *sem, int Value) //尝试获得一个信号量,--Value int sem_wait(sem_t c) //释放信号量,++Value int sem_post(sem_t *sem)
信号量其实就是操作系统中P、V原语的封装,属于内核对象,其工作原理大致如下:
信号量只能进行两种操作等待和发送信号,即P(s)和V(s),他们的行为是这样的:
P(s):如果s的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行
V(s):如果有其他进程因等待s而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1.
2.互斥锁(Mutex)
和信号量之间有啥关系呢,Mutex可以看做Semaphore的一种特殊情况,也就是Value被初始化为1的时候,这种叫做“二元信号量(binary semaphore),通常叫做 “互斥锁”,大多数用法中都对它提供了封装,如C++的std::mutex,C#的Mutex类等
public sealed class Mutex : WaitHandle{ //Blocks the current thread until the current //WaitHandle receives a signal.(Inherited from WaitHandle.) public virtual bool WaitOne() //Releases the Mutex once. public void ReleaseMutex() }
有了互斥锁似乎就能解决大部分“共享变量”问题了(不考虑效率问题),但也并不是所有,考虑下面的方法调用需求:
public class MutexText { private Mutex mutex = new Mutex(); public void Method_A() { mutex.WaitOne(); Method_B(); //Do Somthing…… mutex.ReleaseMutex(); } public void Method_B() { mutex.WaitOne(); //Do Somthing…… mutex.ReleaseMutex(); } }
Method_A获得锁后再调Method_B,然而Method_B中却也在请求锁,会发生”死锁“吗? 答案是:不会,如果是PV原语的二元信号量实现的”单纯“互斥锁的确会出现死锁的问题,但是这里有个”递归锁“的概念,简单说就是一个锁维护了线程对锁的请求次数,如果在线程A已经拥有所mlock的情况下再次请求锁,mlock会将该线程拥有次数加1,当然如果此时有另外一个线程请求mlock,就会进入等待线程队列。
3.读写锁(RWLock)
相对互斥量只有加锁和不加锁两种状态,读写锁有三种状态:读模式下的加锁,写模式下的加锁,不加锁。
读写锁的使用规则:
1.只要没有写模式下的加锁,任意线程都可以进行读模式下的加锁;
2.只有读写锁处于不加锁状态时,才能进行写模式下的加锁;
#include <pthread.h> /* 初始化读写锁属性对象 */ int pthread_rwlockattr_init (pthread_rwlockattr_t *__attr); /* 申请读锁 */ int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); /* 申请写锁 */ int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); /* 释放锁 */ int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
为什么需要读写锁呢?考虑一个简单的应用场景:有个模块维护了一个链表mList,大多数情况下会有很多线程并发访问,比如提供个readData方法给外部索引链表中的元素,然而有极少情况需要增删mList,这时如果使用互斥锁,就会出现访问时只能单线程调用,模块的吞吐能力急剧下降,这时RWLock就派上用场了,示例代码如下:
struct{ pthread_rwlock_t rwlock; int product; }sharedData = {PTHREAD_RWLOCK_INITIALIZER, 0}; List books = new List(); void * RemoveBook(int index) { pthread_rwlock_wrlock(&sharedData.rwlock); books.remove(index); pthread_rwlock_unlock(&sharedData.rwlock); } void Book* GetBook(int i) { Book book = null; pthread_rwlock_rdlock(&sharedData.rwlock); book = books.Get(i); pthread_rwlock_unlock(&sharedData.rwlock); return book; } void Book* PeekBook(int i) { Book book = null; pthread_rwlock_rdlock(&sharedData.rwlock); book = books.Get(i); pthread_rwlock_unlock(&sharedData.rwlock); return book; }
4.条件变量(Cond)
条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待"条件变量的条件成立"而挂起;另一个线程使"条件成立"(给出条件成立信号)。为了防止竞争,条件变量的使用总是和一个互斥锁结合在一起。
/* 常量初始化 */ pthread_cond_t cond = PTHREAD_COND_INITIALIZER /* 动态初始化 */ int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr) /* 等待被触发 */ int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex) /* 销毁 */ int pthread_cond_destroy(pthread_cond_t *cond)
那么什么情况下需要用条件变量去同步呢,举个简单的例子:有个处理文件的过滤器线程,但该文件创建的时机不确定,此时可以考虑让过滤器线程等待文件创建条件,当文件创建完成时,发送通知,唤醒过滤器线程开始工作……贴个示例代码:
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; static pthread_cond_t cond = PTHREAD_COND_INITIALIZER; static void *Filter_File(File *f) { while (f == NULL) { pthread_cond_wait(&cond, &mtx); } //Filter something…… } void main(void) { //创建等待线程 pthread_create(&tid, NULL, Filter_File, NULL); //do something…… laoding file or …… sleep(1000); //发送信号,唤醒等待线程 pthread_cond_signal(&cond); }
5.临界区(Critical Section)
临界区的概念其实和互斥锁有些重合,甚至很多文章中直接是:临界区 == 互斥锁,但是这里提一个在实现原理上稍有不同的“临界区”,在MFC编程中有个临界区的API,签名大致长这样:
/* 初始化临界区,指定自旋次数 */ BOOL WINAPI InitializeCriticalSectionAndSpinCount( _Out_ LPCRITICAL_SECTION lpCriticalSection, _In_ DWORD dwSpinCount ); /* 进入临界区 */ void WINAPI EnterCriticalSection( _Inout_ LPCRITICAL_SECTION lpCriticalSection ); /* 离开临界区 */ void WINAPI LeaveCriticalSection( _Inout_ LPCRITICAL_SECTION lpCriticalSection );
当一个线程进入关键代码段,其它请求进入关键代码段的线程就会进入等待状态,这意味着该线程必须从用户方式转入内核方式(大约1000个C P U周期),这种转换是要付出很大代价的。 而对于多CPU系统,有时候这是没有必要的,实际上拥有资源的线程可以在另一个线程完成转入内核方式之前释放资源。
所以,为了提高性能,Microsoft将自旋锁引入临界区。当EnterCriticalSection函数被调用时,如果临界区已经被其它线程持有时,它就原地自旋,当自旋一定次数后还不能获取关键代码段,此时线程才转入内核方式,进入等待状态。找个简单的示例代码:
const int COUNT = 10; int g_nSum = 0; CRITICAL_SECTION g_cs; DWORD WINAPI FirstThread(PVOID pvParam) { EnterCriticalSection(&g_cs); g_nSum = 0; for (int n = 1; n <= COUNT; n++) { g_nSum += n; } LeaveCriticalSection(&g_cs); return(g_nSum); }
当线程A已经在执行FirstThread的情况下,线程B请求进入临界区代码,此时线程B不会直接进入等待,而是不停的自旋,当自旋一定次数,发现还是不能进入临界区,此时再进入等待状态。
写一个完善的“单例”
水了那么多关于锁的内容,下面简单写一个多线程中“完备的”懒单例,示例代码如下:
/* 所谓的双检锁实现的单例 */ public sealed class Singleton { private Singleton() { } private static Object o_lock = new Object(); private static Singleton inst = null; public Singleton GetInst() { if (inst != null) return inst; Monitor.Enter(o_lock); if (inst == null) { Singleton temp = new Singleton(); Volatile.Write(ref inst, temp); } Monitor.Exit(o_lock); return inst; } }
用这种方案写出的单例,若非真的有“懒初始化”需求,那么多少存在一些“炫技”的嫌疑,哈哈……Monitor锁的作用很简单,就是为了防止多线程并发访问时创建多个Singleton,那么Volatile.Write有什么作用,为什么不写成“inst = new Singleton()”呢?主要防止编译器在处理new Singleton()时,先将inst先赋值了引用,在暗搓搓地去调构造方法,如果此时有其他线程访问Singleton,它会判断inst!=null,然后开心地去用inst,于是dump啦……所以用了一个Volatile.Write,保证了new Singleton()初始化完成,然后再复制。
二.原子操作 和 自旋锁
自旋锁(Spinlock)是一种广泛运用的底层同步机制。自旋锁是一个互斥设备,它只有两个值:“锁定”和“解锁”。它通常实现为某个整数值中的某个位。希望获得某个特定锁得代码测试相关的位。如果锁可用,则“锁定”被设置,而代码继续进入临界区;相反,如果锁被其他人获得,则代码进入忙循环(而不是休眠,这也是自旋锁和一般锁的区别)并重复检查这个锁,直到该锁可用为止,这就是自旋的过程。“测试并设置位”的操作必须是原子的,这样,即使多个线程在给定时间自旋,也只有一个线程可获得该锁。大多数语言都对自旋锁提供了支持,这里简单实现一个暴力自旋锁:
public class SimpleSpinLock { //0:未被占用, 1:已经占用 private int resRefCount = 0; //请求锁,进入代码段 public void Enter() { while(true){ /** * 原子操作,CAS * 只有resRefCount == 0时,resRefCount才会被赋值1 * 返回值是resRefCount原始值 * 所以,如果该锁已经被占用,则该线程会一直自旋 */ if (Interlocked.CompareExchange(ref resRefCount, 1, 0) == 0) { return; } } } //释放锁,离开代码段 public void Leave() { //重置resRefCount状态 Interlocked.Exchange(ref resRefCount, 0); } }
自旋锁还有些优化方案,比如自旋一定次数后仍未获得锁就走内核调用,转入等待队列。如上述锁中的“Cirtical Section” 和 “Monitor”锁,在实现上都做了自旋机制。
2.原子操作
原子操作(atomic operation)是不需要synchronized",这是Java多线程编程的老生常谈了。所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch,
原子性不可能由软件单独保证--必须需要硬件的支持,因此是和架构相关的。在x86 平台上,CPU提供了在指令执行期间对总线加锁的手段。CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀"LOCK",经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。
简单说,原子操作保证一条语句不会被中断,可以一次性执行完成,而这种保证是硬件提供的,大多数语言都提供了CAS(compare and swap)的操作接口,如C#的Interlocked类,C++:
bool atomic_compare_exchange_weak( volatile std::atomic* obj, T* expected, T desired );
有篇不错的文章推荐一下CAS 和 无锁队列,大致讲清楚了CAS使用,和无锁队列的原理
3,简单的无锁队列
//简单版无锁队列 public class LockFreeQueue<T> { //队列节点 private class Node<T> { public T value; public Node<T> next; } private Node<T> head; private Node<T> tail; private int count; public LockFreeQueue() { head = new Node<T>(); tail = head; } public int Count { get { return count; } } //进队列 public void EnQueue(T item) { var node = new Node<T>(); node.value = item; node.next = null; Node<T> tmpTail = null; bool isReplace = false; do { tmpTail = tail; //强制取到队列尾指针 while (tmpTail.next != null) { tmpTail = tmpTail.next; } //保证替换中tmpTail是尾指针 var result = Interlocked.CompareExchange<Node<T>>(ref tmpTail.next, node, null); //替换是否成功 isReplace = result != tmpTail.next; } while (!isReplace);//替换不成功就自旋 Interlocked.Exchange<Node<T>>(ref tail, node); Interlocked.Increment(ref count); } //出队列 public T Dequeue() { bool isReplace = false; Node<T> tmpHead = null; Node<T> oldHeadNext = null; do { //缓存头部相关信息 tmpHead = head; oldHeadNext = tmpHead.next; //空队列 if (oldHeadNext == null) { return default(T); } else { //出队列前头部指针为发生变化 var result = Interlocked.CompareExchange<Node<T>>(ref head, oldHeadNext, tmpHead); isReplace = result != oldHeadNext; } } while (!isReplace); Interlocked.Decrement(ref count); return oldHeadNext.value; } }
三.“锁”相关的一些名词
1.“死锁“、”活锁“
死锁: 是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。 由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象:死锁
活锁(英文 livelock),指线程1可以使用资源,但它让其他线程先使用资源;线程2可以使用资源,但它也让其他线程先使用资源,于是两者一直谦让,都无法使用资源。
所谓饥饿,是指如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求......T2可能永远等待,这就是饥饿。
活锁有一定几率解开。而死锁(deadlock)是无法解开的。避免活锁的简单方法是采用先来先服务的策略。当多个事务请求封锁同一数据对象时,封锁子系统按请求封锁的先后次序对事务排队,数据对象上的锁一旦释放就批准申请队列中第一个事务获得锁。
2.”乐观锁“、”悲观锁
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系 统不会修改数据)。
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库 性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。 而乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如 果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。