1,
背景:复杂模型不好直接部署,简单模式更容易直接部署在服务器中
目的:模型压缩
解决办法:
1,使用Distillation:将老师(复杂模型)学到的“知识”灌输给学生(简单模型),所谓的知识其实是泛化能力。
2,衡量模型的复杂程度:模型中参数的数量。
模型容量的概念:模型的容量是指它拟合各种函数的能力。例如:(y = w3x3 + w2x2 +w1x + b)
w的个数(或者是w的个数和b的个数),补充:尽管输入是x的高次幂,输出任然是参数的线性函数(此时未知数不是x,未知数是parameters),不要以为只有x的一次方才算线性函数。
容量低的模型可能很难模拟数据,也就是underfitting。容量高的可能过拟合,即overfitting。
3,我们的训练目标是在训练数据集上建立模型描述输入和输出的关系,我们已经得到了泛化能力强的Net-T,在利用Net-T蒸馏训练Net-S时,需要将这种泛化能力转移过去,而迁移泛化能力高效的方法就是,使用softmax层输出的类别概率作为soft target。
3,soft target vs hard target:
hard target只使用到正标签,对所有负标签一视同仁,而soft target不仅使用到正标签也使用到负标签(负标签也带有大量的信息),softmax中某些负标签的概率远远大于其他负标签的概率。
4,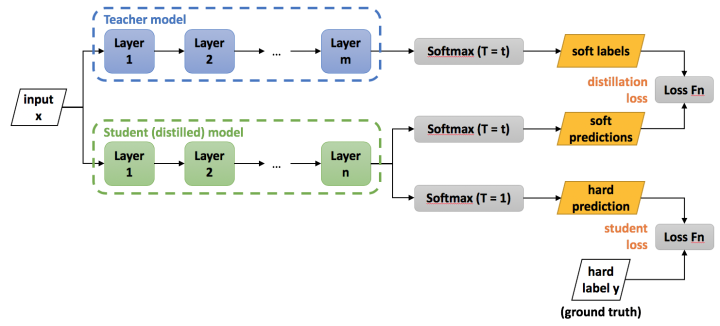
此图,只是使用了最后的输出结果进行计算loss,而在老师的论文中,CNN的每一层都会有一个inference,来实现Net-T泛化能力向Net-S的迁移。
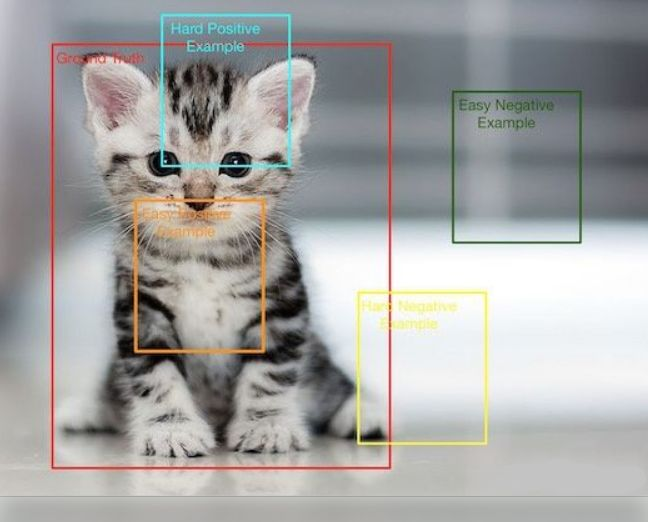
5,正负样本 vs ground truth
正负样本都是针对于程序生成的框框而言,而非GT数据。选取的正负样本是用来训练回归损失或者分类损失的。
5.1, 分类(classification)问题中的正负样本问题:
正样本就是我们想要检测出类别的样本,或者是检测类别和正确标签一致的样本,负样本就是不是目标类别的样本。
5.2,检测(detection)问题中的正负样本问题:
程序标出的框框,与Ground Truth重合度达到一个程度就称为正样本,低于某个阈值时,就称为负样本。