1:查询某一段落内的几条数据,按时间降序。 LIMIT 5,10; //检索记录行6-15
select * from FtpPublicFile order by date_created DESC limit #{page},10
2:创建视图, 查询出某些类别的数据,保存在视图中。 || 的优先级高于and
create view newpoint as select * from newslist where (pid=2 and id=1) || (pid=2 and id=2);
3: 查询出某些字段的数据。
select * from tablec where cat in {'c1','c2'};
4:查询出表中的前几条数据,top在mysql中 不支持,可以用limit代替。
select top 2 * from newpoint order by date_created desc;
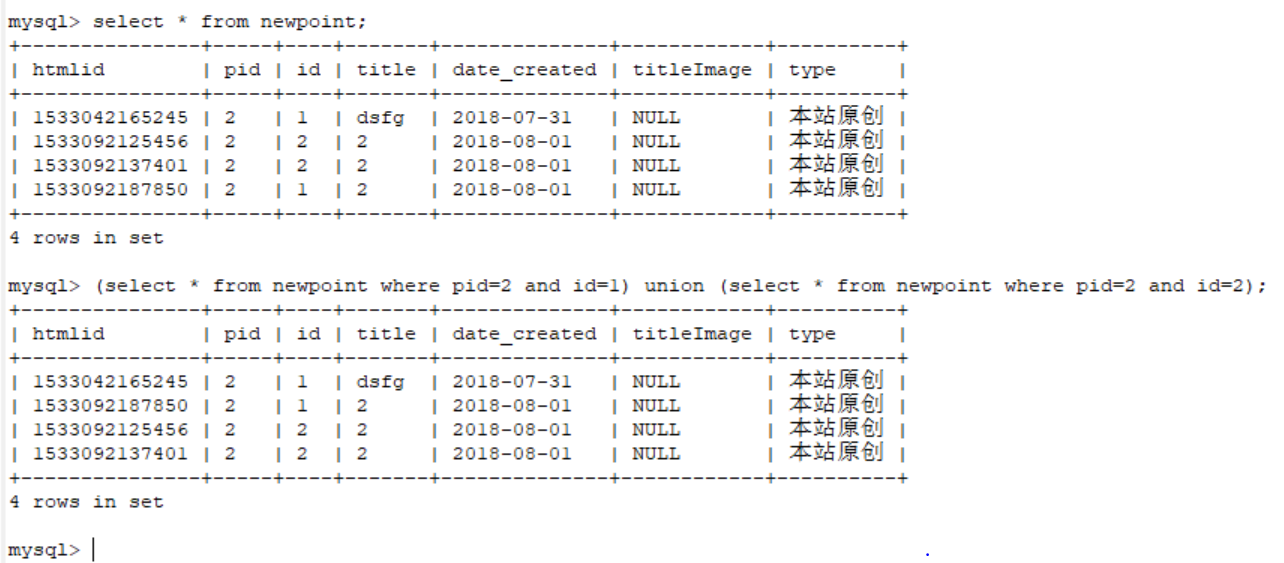
5:查询某些类别之后,union进行合并. 查询的两个表相加。
(select * from newpoint where pid=2 and id=1) union (select * from newpoint where pid=2 and id=2);
6:查询pid和id个数大于2的分组,然后在每一个分组中找到最大的htmlid.
表newslist:
mysql> select * from newslist; +---------------+-----+----+----------+--------------+------------+----------+ | htmlid | pid | id | title | date_created | titleImage | type | +---------------+-----+----+----------+--------------+------------+----------+ | 1533107342607 | 6 | 1 | 国内交流 | 2018-08-01 | NULL | 本站原创 | | 1533107362998 | 2 | 2 | 教学简报 | 2018-08-01 | NULL | 本站原创 | | 1533390471987 | 2 | 1 | test | 2018-08-04 | NULL | 本站原创 | | 1533627497794 | 6 | 1 | 再次交流 | 2018-08-07 | NULL | 本站原创 | | 1533042165245 | 2 | 1 | dsfg | 2018-07-31 | NULL | 本站原创 | | 1533092125456 | 2 | 2 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092137401 | 2 | 2 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092154982 | 2 | 3 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092173217 | 2 | 4 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092187850 | 2 | 1 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533107323029 | 2 | 5 | 学子风采 | 2018-08-01 | NULL | 本站原创 | +---------------+-----+----+----------+--------------+------------+----------+ 11 rows in set
6.1首先创建临时表tempA,找出pid和id个数都大于2的分组。
order by htmlid desc可以不要
create temporary table tempA select distinct * from (select * from newslist where pid in (select pid from newslist group by pid having count(pid)>2) and id in (select id from newslist group by id having count(id)>2) order by htmlid desc) tablea;
mysql> select * from tempA; +---------------+-----+----+----------+--------------+------------+----------+ | htmlid | pid | id | title | date_created | titleImage | type | +---------------+-----+----+----------+--------------+------------+----------+ | 1533390471987 | 2 | 1 | test | 2018-08-04 | NULL | 本站原创 | | 1533107362998 | 2 | 2 | 教学简报 | 2018-08-01 | NULL | 本站原创 | | 1533092187850 | 2 | 1 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092137401 | 2 | 2 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533092125456 | 2 | 2 | 2 | 2018-08-01 | NULL | 本站原创 | | 1533042165245 | 2 | 1 | dsfg | 2018-07-31 | NULL | 本站原创 | +---------------+-----+----+----------+--------------+------------+----------+ 6 rows in set
6.2在临时表中查询 每组的最大htmlid
mysql> select max(htmlid) from tempA group by pid,id; +---------------+ | max(htmlid) | +---------------+ | 1533390471987 | | 1533107362998 | +---------------+ 2 rows in set
6.3查询tempA中共几个pid,id分组
mysql> select distinct pid,id from tempA; +-----+----+ | pid | id | +-----+----+ | 2 | 1 | | 2 | 2 | +-----+----+ 2 rows in set
6.4将1,2步骤合在一起
mysql> select max(htmlid) from (select distinct * from (select * from newslist where pid in (select pid from newslist group by pid having count(pid)>2) and id in (select id from newslist group by id having count(id)>2)) tablea) tableb group by pid,id; +---------------+ | max(htmlid) | +---------------+ | 1533390471987 | | 1533107362998 | +---------------+ 2 rows in set
7 创建数据库employees https://www.nowcoder.com/practice/ec1ca44c62c14ceb990c3c40def1ec6c?tpId=82&tqId=29754&tPage=1&rp=&ru=%2Fta%2Fsql&qru=%2Fta%2Fsql%2Fquestion-ranking
查找最晚入职员工的所有信息 CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL, `birth_date` date NOT NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, `gender` char(1) NOT NULL, `hire_date` date NOT NULL, PRIMARY KEY (`emp_no`));
mysql> insert into employees values(1,2018-01-03,'li','yafei','male','2018-01-02'); mysql> insert into employees values(2,2018-01-03,'li','yafei','male','2018-01-03'); mysql> insert into employees values(3,2018-01-03,'li','yafei','male','2018-01-04'); mysql> insert into employees values(5,2018-01-03,'li','yafei','male','2018-01-06'); mysql> insert into employees values(6,2018-01-03,'li','yafei','male','2018-01-02');
7.1 :查询最晚入职的所有员工,max函数可以用于字符串和日期
select * from employees where hire_date=(select max(hire_date) from employees);
7.2 :查找入职员工时间排名倒数第三的员工所有信息
select * from employees where hire_date=(select hire_date from (select distinct hire_date from employees order by hire_date desc) tableA limit 2,1);
7.3: 部门领导和薪水表,数据.
CREATE TABLE `dept_manager` ( `dept_no` char(4) NOT NULL, `emp_no` int(11) NOT NULL, `from_date` date NOT NULL, `to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`dept_no`)); CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL, `salary` int(11) NOT NULL, `from_date` date NOT NULL, `to_date` date NOT NULL, PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO dept_manager VALUES('d001',10002,'1996-08-03','9999-01-01'); INSERT INTO dept_manager VALUES('d002',10006,'1990-08-05','9999-01-01'); INSERT INTO dept_manager VALUES('d003',10005,'1989-09-12','9999-01-01'); INSERT INTO dept_manager VALUES('d004',10004,'1986-12-01','9999-01-01'); INSERT INTO dept_manager VALUES('d005',10010,'1996-11-24','2000-06-26'); INSERT INTO dept_manager VALUES('d006',10010,'2000-06-26','9999-01-01'); INSERT INTO salaries VALUES(10001,60117,'1986-06-26','1987-06-26'); INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25'); INSERT INTO salaries VALUES(10001,66074,'1988-06-25','1989-06-25'); INSERT INTO salaries VALUES(10001,66596,'1989-06-25','1990-06-25'); INSERT INTO salaries VALUES(10001,66961,'1990-06-25','1991-06-25'); INSERT INTO salaries VALUES(10001,71046,'1991-06-25','1992-06-24'); INSERT INTO salaries VALUES(10001,74333,'1992-06-24','1993-06-24'); INSERT INTO salaries VALUES(10001,75286,'1993-06-24','1994-06-24');
查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no
sql
select distinct salaries.emp_no,salary,salaries.from_date,salaries.to_date,dept_no from dept_manager,salaries where salaries.emp_no=dept_manager.emp_no and salaries.to_date='9999-01-01' and dept_manager.to_date='9999-01-01';
7.4:查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
select e.last_name,e.first_name,d.dept_no from employees e left outer join dept_emp d on e.emp_no=d.emp_no;
8:concat 的用法, 连接字符串
mysql> select concat('11','22','33'); -> // +------------------------+ | concat('11','22','33') | +------------------------+ | 112233 | +------------------------+ 1 row in set
9:各种数据类型的转换:cast(intNum as char);
https://www.cnblogs.com/yangchunze/p/6667502.html
10:sql中 find_in_set(str1,str2)用法 ,找到字符串str1在str2中的位置。https://www.cnblogs.com/mytzq/p/7090197.html
mysql> SELECT FIND_IN_SET('b','a,b,c,d'); +----------------------------+ | FIND_IN_SET('b','a,b,c,d') | +----------------------------+ | 2 | +----------------------------+ 1 row in set
11: group_concat ,将某一分组的某个字段连接起来。
https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc
mysql> select * from salarie; +----------+--------+----+ | name | salary | id | +----------+--------+----+ | zhangsan | 2100 | 1 | | lisi | 2600 | 2 | | wangwu | 3000 | 3 | | wangwu | 200 | 4 | | wangwu | 200 | 5 | | wangwu | 200 | 6 | | wangwu | 200 | 7 | | wangwu | 200 | 8 | | wangwu | 200 | 9 | | wangwu | 200 | 10 | | wangwu | 200 | 11 | | wangwu | 200 | 12 | | wangwu | 200 | 13 | | lisi | 200 | 14 | | lisi | 200 | 15 | | lisi | 200 | 16 | | lisi | 200 | 17 | | lisi | 200 | 18 | | lisi | 200 | 19 | | zhangsan | 400 | 20 | | zhangsan | 400 | 21 | | zhangsan | 400 | 22 | | zhangsan | 400 | 23 | | zhangsan | 400 | 24 | | zhangsan | 400 | 25 | | zhangsan | 400 | 26 | | zhaoliu | 1300 | 28 | +----------+--------+----+ 27 rows in set
-- find_in_set()用法
mysql> select * from salarie where find_in_set('wangwu',name); +--------+--------+----+ | name | salary | id | +--------+--------+----+ | wangwu | 3000 | 3 | | wangwu | 200 | 4 | | wangwu | 200 | 5 | | wangwu | 200 | 6 | | wangwu | 200 | 7 | | wangwu | 200 | 8 | | wangwu | 200 | 9 | | wangwu | 200 | 10 | | wangwu | 200 | 11 | | wangwu | 200 | 12 | | wangwu | 200 | 13 | +--------+--------+----+ 11 rows in set
group_concat()
mysql> select name,salary,group_concat(id) from salarie group by(name); +----------+--------+---------------------------+ | name | salary | group_concat(id) | +----------+--------+---------------------------+ | lisi | 200 | 14,15,16,17,18,19,2 | | wangwu | 200 | 13,12,11,10,3,4,5,6,7,8,9 | | zhangsan | 400 | 26,25,24,23,22,21,20,1 | | zhaoliu | 1300 | 28 | +----------+--------+---------------------------+ 4 rows in set
group_concat()
mysql> select name,salary,group_concat(id) from salarie group by(salary); +----------+--------+-------------------------------------------+ | name | salary | group_concat(id) | +----------+--------+-------------------------------------------+ | lisi | 200 | 14,19,18,17,16,15,13,12,11,10,9,4,5,6,7,8 | | zhangsan | 400 | 24,25,26,20,21,22,23 | | zhaoliu | 1300 | 28 | | zhangsan | 2100 | 1 | | lisi | 2600 | 2 | | wangwu | 3000 | 3 | +----------+--------+-------------------------------------------+ 6 rows in set
12:mysql实现rank函数,mysql自带的没有rank函数,所以需要自己实现该函数。 https://blog.csdn.net/qq686867/article/details/79355760
A=B
A表中的薪水取出,从B表中查询出比该薪水大的个数,就是该薪水的排名。
select id,salary,name,(1+(select count(*) from salarie B where B.salary>A.salary)) as s_rank from salarie A order by s_rank;
mysql> select id,salary,name,(1+(select count(*) from salarie B where B.salary>A.salary)) as s_rank from salarie A order by s_rank; +----+--------+----------+--------+ | id | salary | name | s_rank | +----+--------+----------+--------+ | 3 | 3000 | wangwu | 1 | | 2 | 2600 | lisi | 2 | | 1 | 2100 | zhangsan | 3 | | 28 | 1300 | zhaoliu | 4 | | 22 | 400 | zhangsan | 5 | | 26 | 400 | zhangsan | 5 | | 25 | 400 | zhangsan | 5 | | 24 | 400 | zhangsan | 5 | | 23 | 400 | zhangsan | 5 | | 21 | 400 | zhangsan | 5 | | 20 | 400 | zhangsan | 5 | | 18 | 200 | lisi | 12 | | 19 | 200 | lisi | 12 | | 5 | 200 | wangwu | 12 | | 17 | 200 | lisi | 12 | | 16 | 200 | lisi | 12 | | 15 | 200 | lisi | 12 | | 6 | 200 | wangwu | 12 | | 7 | 200 | wangwu | 12 | | 8 | 200 | wangwu | 12 | | 9 | 200 | wangwu | 12 | | 10 | 200 | wangwu | 12 | | 11 | 200 | wangwu | 12 | | 12 | 200 | wangwu | 12 | | 13 | 200 | wangwu | 12 | | 4 | 200 | wangwu | 12 | | 14 | 200 | lisi | 12 | +----+--------+----------+--------+ 27 rows in set
排名,按顺序 。 @salary_rank:=@salary_rank+1 ,从上往下查,每查询一个salary_rank就加1
mysql> set @salary_rank:=0; select s.*,@salary_rank:=@salary_rank+1 from salarie s order by salary; Query OK, 0 rows affected +----------+--------+----+------------------------------+ | name | salary | id | @salary_rank:=@salary_rank+1 | +----------+--------+----+------------------------------+ | lisi | 200 | 14 | 1 | | lisi | 200 | 19 | 2 | | lisi | 200 | 18 | 3 | | lisi | 200 | 17 | 4 | | lisi | 200 | 16 | 5 | | lisi | 200 | 15 | 6 | | wangwu | 200 | 13 | 7 | | wangwu | 200 | 12 | 8 | | wangwu | 200 | 11 | 9 | | wangwu | 200 | 10 | 10 | | wangwu | 200 | 9 | 11 | | wangwu | 200 | 4 | 12 | | wangwu | 200 | 5 | 13 | | wangwu | 200 | 6 | 14 | | wangwu | 200 | 7 | 15 | | wangwu | 200 | 8 | 16 | | zhangsan | 400 | 24 | 17 | | zhangsan | 400 | 25 | 18 | | zhangsan | 400 | 26 | 19 | | zhangsan | 400 | 20 | 20 | | zhangsan | 400 | 21 | 21 | | zhangsan | 400 | 22 | 22 | | zhangsan | 400 | 23 | 23 | | zhaoliu | 1300 | 28 | 24 | | zhangsan | 2100 | 1 | 25 | | lisi | 2600 | 2 | 26 | | wangwu | 3000 | 3 | 27 | +----------+--------+----+------------------------------+ 27 rows in set
13: mysql中:= 与=的区别, select中使用=需要先set
:=与=都是赋值语句,但是=只有在set以及select语句中才为赋值语句,还有逻辑比较的功能
14: mysql实现row_number 的功能
select @rd := @rd+1 as rownum, id from (select @rd:=0, id from salarie) b;
15: mysql中的各种查询
https://blog.csdn.net/evankaka/article/details/46954751
16:mysql中实现tile
mysql> set @num=1; select id,round((@num:=@num+1)/((select count(*) from salarie where name='wangwu')/3)) as tile from salarie where name='wangwu'; Query OK, 0 rows affected +----+------+ | id | tile | +----+------+ | 3 | 1 | | 4 | 1 | | 5 | 1 | | 6 | 1 | | 7 | 2 | | 8 | 2 | | 9 | 2 | | 10 | 2 | | 11 | 3 | | 12 | 3 | | 13 | 3 | +----+------+ 11 rows in set
17:mysql中 函数大全
https://www.cnblogs.com/xuyulin/p/5468102.html
18: enum的用法,ENUM中为每个数据按照整数形式存储。
mysql> create table enum_table( -> e ENUM('fish','apple','dog') not null); Query OK, 0 rows affected mysql> insert into enum_table values('fish'),('dog'),('apple'); Query OK, 3 rows affected Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from enum_table; +-------+ | e | +-------+ | fish | | dog | | apple | +-------+ 3 rows in set mysql> select e+0 from enum_table; +-----+ | e+0 | +-----+ | 1 | | 3 | | 2 | +-----+ 3 rows in set
高效Mysql
19:inet_aton() 将IP地址和整数的相互转化,可以将IP地址转化为整数存储,效率较高,因为整数比较比字符串比较算法不同,更快。
20: 为某个字段(url)计算索引值,作为改字段存储的索引值。
mysql> select crc32('http://www.mysql.com'); +-------------------------------+ | crc32('http://www.mysql.com') | +-------------------------------+ | 1560514994 | +-------------------------------+ 1 row in set
创建一个函数,为某个子段计算索引值,可以使用触发器。
mysql> drop table if exists pseudoHash; create table pseudoHash( id int not null auto_increment, url varchar(255) not null, crc32 int unsigned not null default 0, primary key(id) ); delimiter// drop trigger if exists insertCrc32ForUrl;// create trigger insertCrc32ForUrl before insert on pseudoHash for each row begin set new.crc32=crc32(new.url); end;// delimiter; Query OK, 0 rows affected Query OK, 0 rows affected Query OK, 0 rows affected Query OK, 0 rows affected mysql> insert into pseudoHash(url) values('http://www.mysql.com'); Query OK, 1 row affected mysql> select * from pseudoHash; +----+----------------------+------------+ | id | url | crc32 | +----+----------------------+------------+ | 1 | http://www.mysql.com | 1560514994 | +----+----------------------+------------+ 1 row in set
查询的时候要用字段和crc32的值同时查询,因为不同的字段可能crc32值相同,然后需要根据内容判断。
mysql> select * from pseudoHash where url='http://www.mysql.com' and crc32=crc32('http://www.mysql.com'); +----+----------------------+------------+ | id | url | crc32 | +----+----------------------+------------+ | 1 | http://www.mysql.com | 1560514994 | +----+----------------------+------------+ 1 row in set
21: 计算每次sql执行时间 https://blog.csdn.net/lin443514407lin/article/details/54911120?locationNum=10&fps=1
22: 用户定义变量
set @var1:=1; -- 定义变量 set @var2:='abc'; select @var1:=@var1+1 as variable1 from t1; set @var1:=select count(*) from t1; -- 使用变量
23: 让应用直接访问多个数据源,绝对是个糟糕的设计,因为这会增加许多复杂的代码。一个好办法是,把这些代码都放在一个抽象层里,这个抽象层要完成以下这些任务。
a: 连接到正确的数据分块上,并查询数据。
b:分布式一致性校验。
c: 跨分块查询后的数据聚合。
d:跨分块连接。
e:锁和事务管理
f:创建新数据分块(至少是在运行时找到新的数据分块),然后重新平衡所有分块(如果你有时间实现它)。
数据分块的工具例如:mysql-proxy, 美团的meituan-proxy就是给数据库抽象层,提供这种作用。mysql-proxy, 美团的meituan-proxy 也可以做负载平衡。
24: 负载平衡算法
a: 随机,b:轮询 c: 最小连接优先d:最快响应优先e:散列化f:权重。
25:mysql通信协议:a:tcp/ip,b:socket c: 共享内存, d:信号量
26:备份工具
26.1 :mysqldump
将表从一台服务器复制到另一台
26.2 innodb引擎的 ibbackup 实现热备份。
26.3 perl脚本 mysqlhotcopy
26.4 ZRM 使用最广泛的
26: 权限
grant [privileges] on [objects] to [user]; grant select on test.salary to 'liyafei'@'127.0.0.1'; -- 授予某个服务器,某个用户对salary表的查询权限 grant [privileges] on [objects] to [user] identified by [password]; revoke [privileges] on [objects] from [user]; -- 收回权限 grant all privileges on *.* to 'root'@'localhost' identified by [password] with grant option; -- 赋予超级用于权限
27: mysql中的并发控制
27.1: 多版本机制
a: 多版本时间戳排序,每当write(data)时,就创建一个data的版本。 形成一个版本序列, 当发出read(data)操作时,就立即返回其中一个版本的数据。
b:当事务Ti发出write(data),如果事务Ti的开始时间TS(Ti) 小于(早于)data(Qk版本)的读取时间R-timestamp(Qk)。说明该数据已经被读取了,该事物不能写入了。 如果TS(Ti)<R-timestamp(Qk) ,则系统回滚事务Ti。 如果TS(Ti)>R-timestamp(Qk) ,创建data的一个新版本。
27.2 快照隔离
a: 快照隔离在事务开始执行时给它数据库的一份快照(snapshot)。然后,事务在该快照上操作,和其它并发事务完全隔离开。
b: 快照隔离的更新操作, 采取先更新者获胜。 如果两个事务T1和T2对同一数据项进行更新,那么当T1要更新时,会获得该数据项的更新锁,T2操作发现被其它事务跟新了,T2将中止。
c: 快照隔离不能保证可串行化
d: 快照隔离中,在查询语句之后,添加for update可以防止快照的并发修改。
select * from t1 where id=2222 for update;
28: MySql中DECLARE CONTINUE HANDLER FOR NOT FOUND 解释https://blog.csdn.net/wanglha/article/details/51434148
1.解释:
在MySQL的存储过程中经常会看到这句话:DECLARE CONTINUE HANDLER FOR NOT FOUND。
它的含义是:若没有数据返回,程序继续,并将变量IS_FOUND设为0 ,这种情况是出现在select XX into XXX from tablename的时候发生的。
sql中处理异常 https://www.cnblogs.com/datoubaba/archive/2012/06/20/2556428.html
29: exists 的使用,exists只做判断不做筛选
mysql> select * from t1; +------+-------+ | name | grade | +------+-------+ | 3 | 64 | | 3 | 59 | | 5 | 80 | | 5 | 64 | +------+-------+ 4 rows in set (0.02 sec) mysql> select * from t1 where name=5 and exists(select * from t1 where grade=80); +------+-------+ | name | grade | +------+-------+ | 5 | 80 | | 5 | 64 | +------+-------+ 2 rows in set (0.03 sec) mysql>
子查询
mysql> select * from (select avg(grade) as avg_grade from t1 group by name)t where t.avg_grade>60; +-----------+ | avg_grade | +-----------+ | 61.5000 | | 72.0000 | +-----------+ 2 rows in set (0.04 sec) mysql> select * from (select avg(grade) as avg_grade from t1 group by name)t where t.avg_grade>62; +-----------+ | avg_grade | +-----------+ | 72.0000 | +-----------+ 1 row in set (0.04 sec)