一,先来介绍MongoDB的简单知识,请点击先下面链接
https://www.cnblogs.com/liyanyinng/p/10922204.html
二,测试MongoDB
下面以中国最好大学排名为例,从网上爬取数据并存为csv文件
1 # -*- coding: UTF-8 -*- 2 import requests 3 import pandas as pd 4 from bs4 import BeautifulSoup 5 allUniv=[] #建立二维数组储存 6 def getHTMLText(url): #获取网页Text内容 7 try: 8 r=requests.get(url,timeout=30) 9 r.raise_for_status() 10 r.encoding='utf-8' 11 return r.text 12 except: 13 return "" 14 def fillUnivList(soup): #寻找单个大学的数据 15 data=soup.find_all('tr') #寻找一行的开头 16 for tr in data: 17 ltd=tr.find_all('td') #寻找一格 18 if len(ltd)==0: 19 continue 20 singleUniv=[] 21 for td in ltd: #对每格数据进行存储 22 singleUniv.append(td.string) 23 allUniv.append(singleUniv) 24 text=pd.DataFrame(allUniv) 25 text.to_excel("D:\CFUB.xlsx",encoding="GBK") 26 def printUnivList(num): #输出数据兼格式 27 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}" 28 .format(chr(12288),"排名","学校名称","省市","总分","培养规模")) 29 for i in range(num): 30 u=allUniv[i] 31 print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format 32 (chr(12288),u[0],u[1],u[2],eval(u[3]),u[6])) 33 def main(num): #{}里表示占用多少个字符 34 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' 35 html=getHTMLText(url) 36 soup=BeautifulSoup(html,"html.parser") 37 fillUnivList(soup) 38 printUnivList(num) 39 main(50)
再来看看效果:
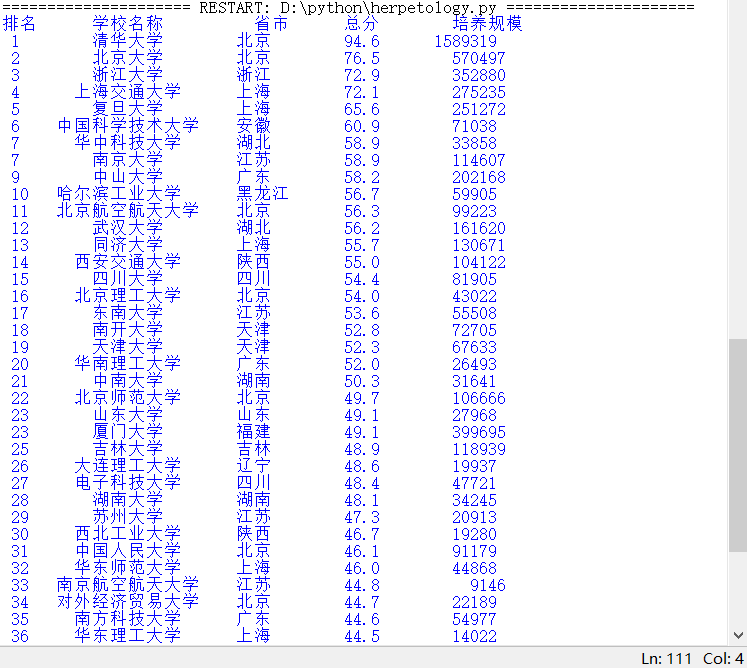
2、把爬取到的数据存入MongoDB数据库
1 from bs4 import BeautifulSoup 2 import pandas as pd 3 import pymongo 4 import requests 5 def getHTMLText(url): #获取网页Text内容 6 try: 7 r=requests.get(url,timeout=30) 8 r.raise_for_status() 9 r.encoding='utf-8' 10 return r.text 11 except: 12 return "" 13 14 def fillUnivList(soup): #寻找单个大学的数据 15 data=soup.find_all('tr') #寻找一行的开头 16 for tr in data: 17 ltd=tr.find_all('td') #寻找一格 18 if len(ltd)==0: 19 continue 20 singleUniv=[] 21 for td in ltd: #对每格数据进行存储 22 singleUniv.append(td.string) 23 save_list_to_Mongodb(singleUniv) 24 25 def client_Mongodb(port, path): 26 myclient = pymongo.MongoClient(host='localhost', port=port) # 连接 27 my_set = myclient.path # 连接path,如果没有则创建一个数据库 28 return my_set 29 30 def save_mongo(result): 31 myclient = pymongo.MongoClient(host='localhost', port=27017) 32 my_set = myclient.CFUS 33 try: 34 if my_set.product.insert_one(result): #如果保存成功 35 pass#print("数据保存成功") 36 except Exception: 37 print("数据保存失败") 38 39 def save_list_to_Mongodb(lists): 40 my_set = client_Mongodb(27017, 'CFUS') 41 product = { 42 '排名': lists[0], 43 '学校名称': lists[1], 44 '省份': lists[2], 45 '总分': lists[3], 46 '生源质量(新生高考成绩得分)': lists[4], 47 '培养结果(毕业生就业率': lists[5], 48 '社会声誉(社会捐赠收入·千元': lists[6], 49 '科研规模(论文数量·篇)': lists[7], 50 '科研质量(论文质量·FWCI)': lists[8], 51 '顶尖成果(高被引论文·篇)': lists[9], 52 '顶尖人才(高被引学者·人)': lists[10], 53 '科技服务(企业科研经费·千元': lists[11], 54 '成果转化(技术转让收入·千元)': lists[12], 55 '学生国际化(留学生比例)': lists[13], 56 } # 字典类型数据 57 save_mongo(product) 58 59 def main(): 60 url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' 61 html = getHTMLText(url) 62 soup = BeautifulSoup(html, "html.parser") 63 fillUnivList(soup) 64 print("完成") 65 for i in pymongo.MongoClient(host='localhost', port=27017).University.ranking.product.find(): 66 print(i) # 输出 67 main()
再来查看期效果:

如此,爬取的数据就存进了数据库了
4、对数据库的数据进行提取
可在上面的代码中追加下面的代码,即可按照指定的信息提取数据
1 myquery = {"学校名称": "广东技术师范大学"} 2 for i in pymongo.MongoClient(host='localhost', port=27017).CFUS.product.find(myquery): 3 print(i)
查看效果:

再追加下面代码,其实就是修改了信息
1 myquery = {"省份": "广东"} 2 for i in pymongo.MongoClient(host='localhost', port=27017).CFUS.product.find(myquery): 3 print(i)
查看效果:

这样就可以完成对数据库的一些操作了