一、利用R进行关联规则挖掘
数据结构如下:
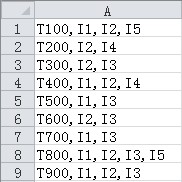
(共9个itemsets,5个items)
首先读入数据:
demodata = read.transactions("C:\Documents and Settings\Administrator\桌面\DemoData.csv", rm.duplicates= TRUE, format="basket",sep=",",cols =c(1))
查看数据:
inspect(demodata)

或者:
summary(demodata)
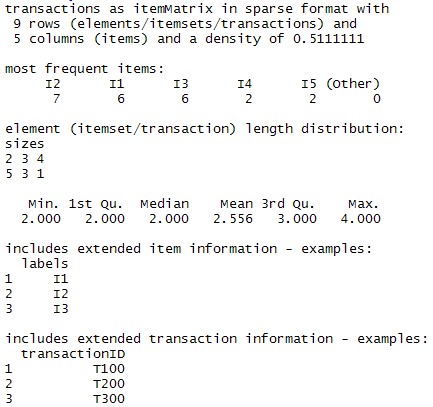
加载arules包
library(arules)
先求频繁项集(建议用eclat)
frequentsets=eclat(demodata,parameter=list(support=0.2,maxlen=4))
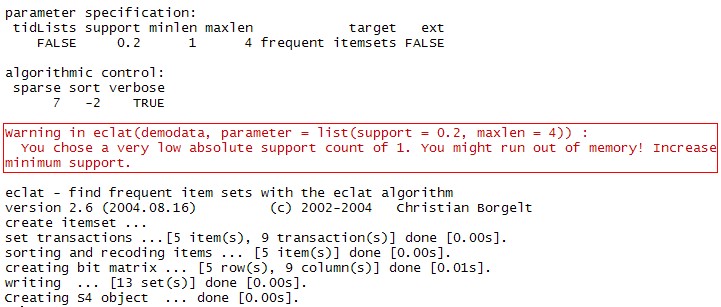
(没办法,itemsets太少了,红色框中的warning可以无视)
观察挖掘出来的频繁项集
inspect(frequentsets)

当频繁项集较多时可以根据支持度对挖掘出来的频繁项集排序并察看最前面的几个即可
inspect(sort(frequentsets,by="support")[1:10])

接着就可以挖掘关联规则了(使用apriori,可以适当调整支持度)
rules=apriori(demodata,parameter=list(support=0.2,confidence=0.5))
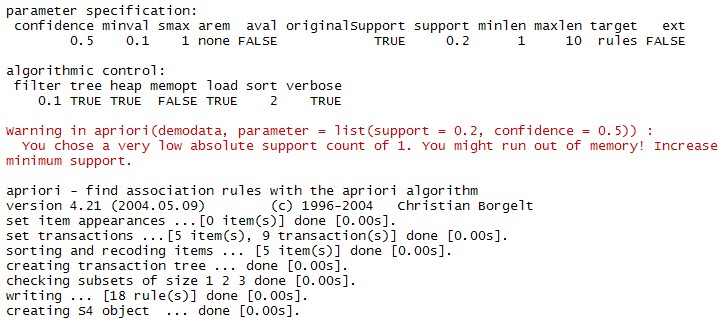
察看关联规则的主要内容
summary(rules)
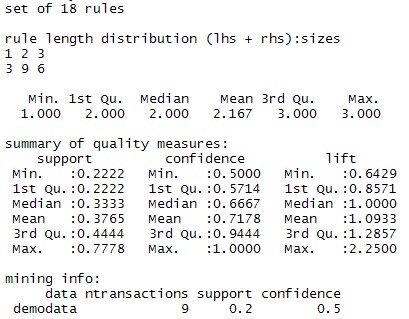
最后求出所需要的关联规则子集(注意:lift > 1 时才表示前项、后项正相关,且越大越好,此处取1.2)
results=subset(rules,subset=lift>=1.2) inspect(sort(results,by="support"))
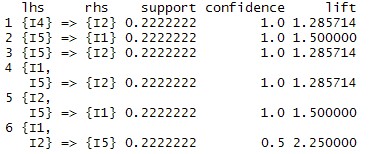
到此,利用R进行关联规则挖掘就暂时告一段落。
二、利用SAS进行关联规则挖掘
(留坑,待填)