1. 如何用通俗的方法解释MapReduce
MapReduce是Google开源的三大技术之一,是对海量数据进行“分而治之”计算框架。为了简单的理解并讲述给客户理解。我们举下面的例子来说明.
首先,面对一堆杂乱的东西,有若干个汉堡、若干个冰淇淋、若干个可乐。如果级别都是上万数量的情况下,有没有方法把他们较快的分析出来?

第一步,调度员简单的将这一堆东西分解成若干堆。

第二步,调度员为每堆物品分配一个分拣员,注意只分拣不计数,分拣员对应MAPReduce中的Map角色。分拣员干的事情,就是将物品按类别分拣,比如分拣后的每一堆的状态应该是如下图所示。分拣员所做的也分成简单,从自己面前这一堆物品中拿一个,看是面包的话,就扔面包那。是可乐就扔可乐那。

第三步,调度员为每类物品分配一个计数员(Reducer),把所有该类型的物品都发给他计数。比如所有的面包类别都分给第一个计数员来负责计数。计数员统计出每个类别的数目,再告诉调度员。

总结:Mapper用来分类,Reduce则用来对同类型的东西做进一步处理。对于互联网的应用场景,比如分析一个网页中出现的词汇最多的单词是什么。Mapper用来将网页中的文字段落分解成一个个单词。相同的单词会被送给同一个Reducer。Reducer会计算出该单词出现了多少次。最后按照各单词出现的次数得出结论。
2. 一个文本文件的处理过程
1)对应这样一个源文本文件

2)首先由调度员通过job.setInputFormatClass(TextInputFormat.class),知道应该转换成偏移量加文本方式的键-值对;再根据当前机器个数,文件大小确定应该分解成几个待处理的片段,比如说分解成两个片段,对应两个Map程序。

3)第一个Map程序每次被调用,接受到的入参(key,value)是

Map程序的输出是
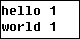
4)第二个Map程序接受的输入将是

第二个Map的输出将是

5)Map程序的输出,会被重新组合,同一个Key的内容,会被分配到同一个Reduce上。
比如上面三个单词,会被分到三个Reducer上
6)第一个Reducer接收到,如下图,注意是两个1,来自两个Map的结果

第一个Reducer的输出会是如下图,意味着hello这个单词出现了两次

7)第二个Reducer接收到

第二个Reducer输出会是

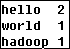
8)第三个Reducer接收到

第三个Reducer输出是

9)最后将三个Reducer进行合并,得到的结果就是
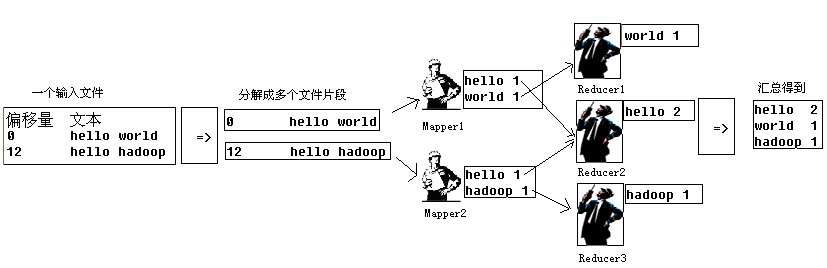
10)汇总流程描述如图所示
转载自
Hadoop的MapReduce实现原理解释
如侵删