一、发展历程
早期淘宝内部有两套消息中间件系统:Notify和Napoli。 先有的Notify(至今12历史),后来因有序场景需求,且恰好当时Kafka开源(2011年),所以参照Kafka的设计理念自研了RocketMQ。 目前Notify和RocketMQ二者的定位如下:
- RocketQ 主要面向消息有序的场景,能够提供更大的消息堆积能力,拉模式,消息持久化在磁盘
- Notify主要面向更加安全可靠地交易类场景,无序、推模式、消息持久化在mysql
RocketMQ发展历程如下:
- Metaq 1.x 开源社区维护killme2008维护,因为依赖zk挂了,导致上下游服务全网宕机,到了12年基于开源Kafka,直接用java语言翻译重写
- Metaq 2.x 2012年11月上线,淘宝内部使用
- RocketMQ 3.x 后来一统江湖成为整个阿里系主流MQ。基于公司内部开源共建原则, RocketMQ项目只维护核心功能,且去除了所有其他运行时依赖,核心功能最简化。每个BU的个性化需求都在RocketMQ项目之上进行深度定制。RocketMQ向其他BU提供的仅仅是Jar包,例如要定制一个Broker,那么只需要依赖rocketmq-broker这个jar包即可,可通过API进行交互,如果定制client,则依赖rocketmq-client这个jar包,对其提供的api进行再封装。
- RocketMQ 4.x.x 捐献给Apache社区,经过一年时间重构孵化成为顶级项目
Metaq改名为RocketMQ,RocketMQ项目做核心功能,淘宝内部其他个性化需求有做定制化开发,如:
com.taobao.metaq v3.0 (为淘宝应用提供消息服务 ) com.alipay.zpullmsg v1.0 (为支付宝应用提供消息服务) com.alibaba.commonmq v1.0 (为 B2B 应用提供消息服务)
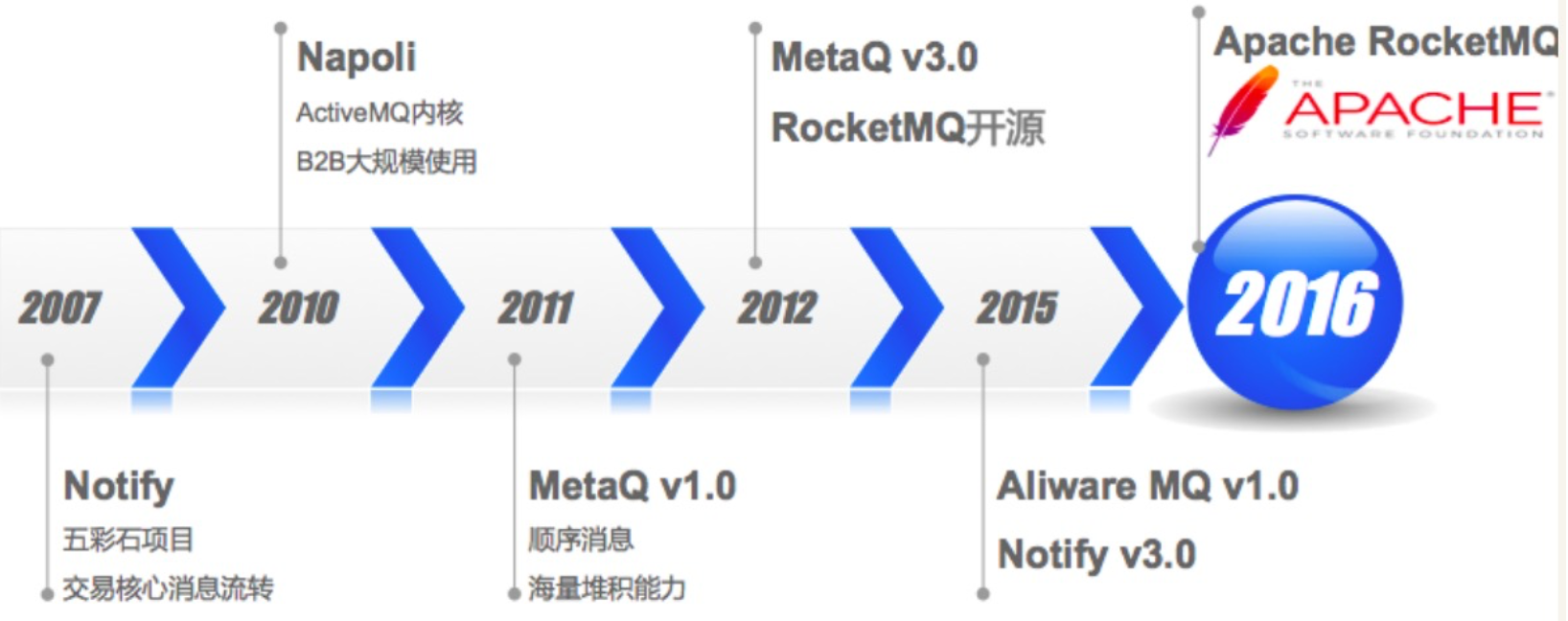
RocketMQ一共经历了三代里程碑演进:
- Notify 为阿里系第一代MQ产品。推模式,数据存储采用关系型数据库。
- Metaq 为阿里系第二代MQ产品。拉模式,自研的专有消息存储,在日志处理方面参考Kafka,典型代表MetaQ。
- RocketMQ为阿里系第三代MQ产品。以拉模式为主,兼有推模式,低延迟消息引擎RocketMQ,在二代功能特性的基础上,为电商金融领域添加了可靠重试、基于文件存储的分布式事务等特性。使用在了阿里大量的应用上,典型如双11场景,具有万亿级消息堆积能力。
RocketMQ项目根据开源与商业分成2个版本:
- Apache RocketMQ是对外开源版
- 2013年,阿里云ONS(功能相比较更齐全,特别是运维体系完善,例如:运维管控,安全授权,深度培训等纳入商业重中之重)
- 2015年,Aliware MQ(Message Queue)是RocketMQ的商业版本,是阿里云商用的专业消息中间件,是企业级互联网架构的核心产品,基于高可用分布式集群技术,搭建了包括发布订阅、消息轨迹、资源统计、定时(延时)、监控报警等一套完整的消息云服务。
二、系统架构
系统定位
- 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点
- 同时支持Push与Pull方式消费消息
- 能支撑天猫双十一海量消息考验
- 能够保证严格的消息顺序
- 提供丰富的消息拉取模式
- 高效的订阅者水平扩展能力
- 亿级消息堆积能力

四种集群部署方式:
- 单master (缺点:broker宕机,服务不可用)
- 多master无slave (缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅)
- 多master多slave,异步复制 (缺点:Master 宕机,磁盘损坏情况,可能会丢失少量消息)
- 多master多slave,同步双写(缺点:性能比异步复制模式略低,大约低 10%左右)
生产环境部署都是多主多从。下面以2主2从为例
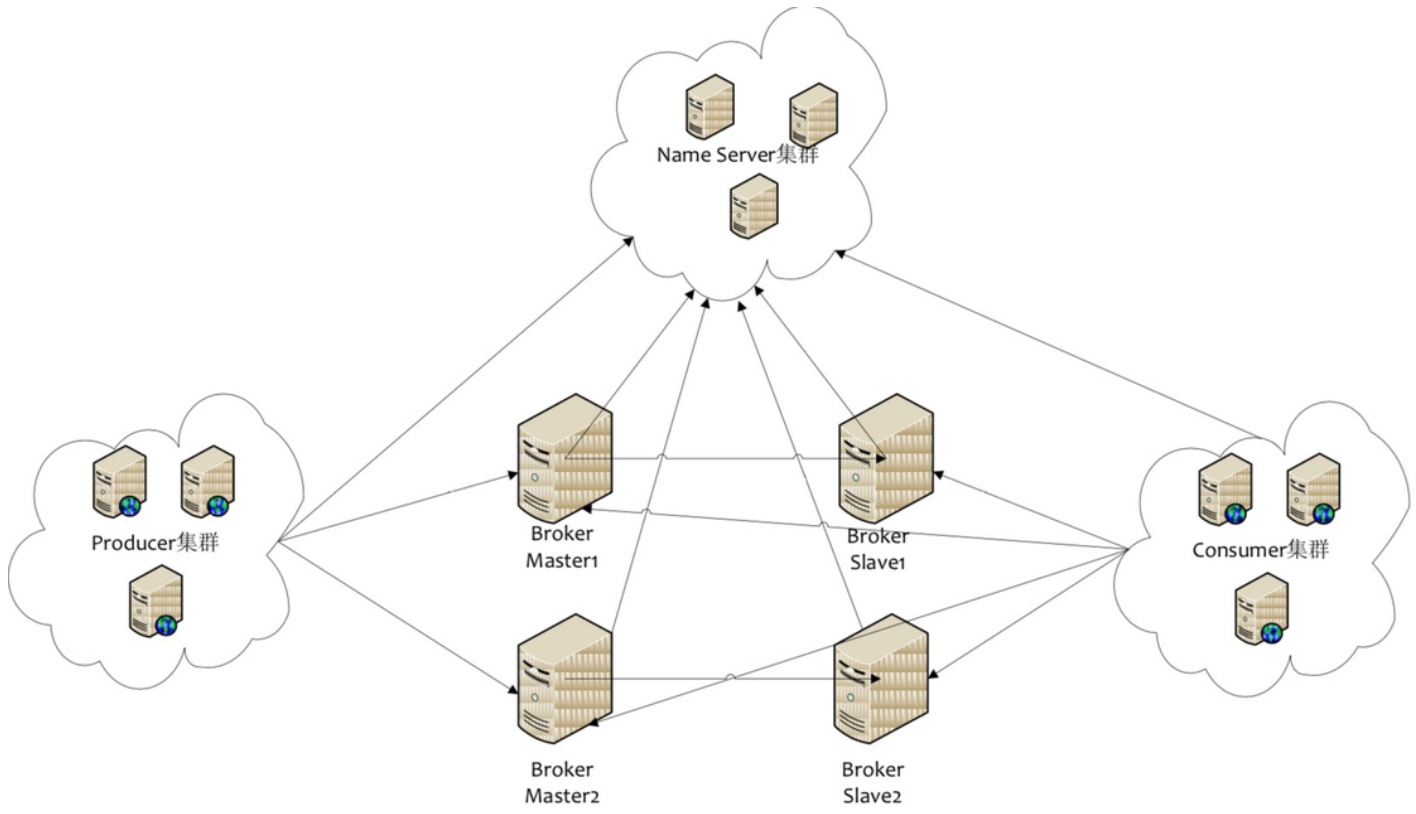
组件角色
- Producer:消息发布的角色,支持分布式集群方式部署。与NameServer(随机)中的其中一个节点建立长链接,定期获取Topic路由信息,并向提供Topic服务的Master建立长链接,另外和 Master之间做心跳。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
- Consumer:消息消费的角色,支持分布式集群方式部署。与NameServer(随机)中的其中一个节点建立长链接,定期获取Topic路由信息,并向提供topic服务的Master、Slave建立长连接 ,由Broker配置订阅规则。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求。
- NameServer:NameServer是一个非常简单的Topic路由注册中心,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。主要包括两个功能:Broker管理,NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活;路由信息管理,每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费。NameServer通常也是集群的方式部署,各实例间相互不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以动态感知Broker的路由的信息。
-
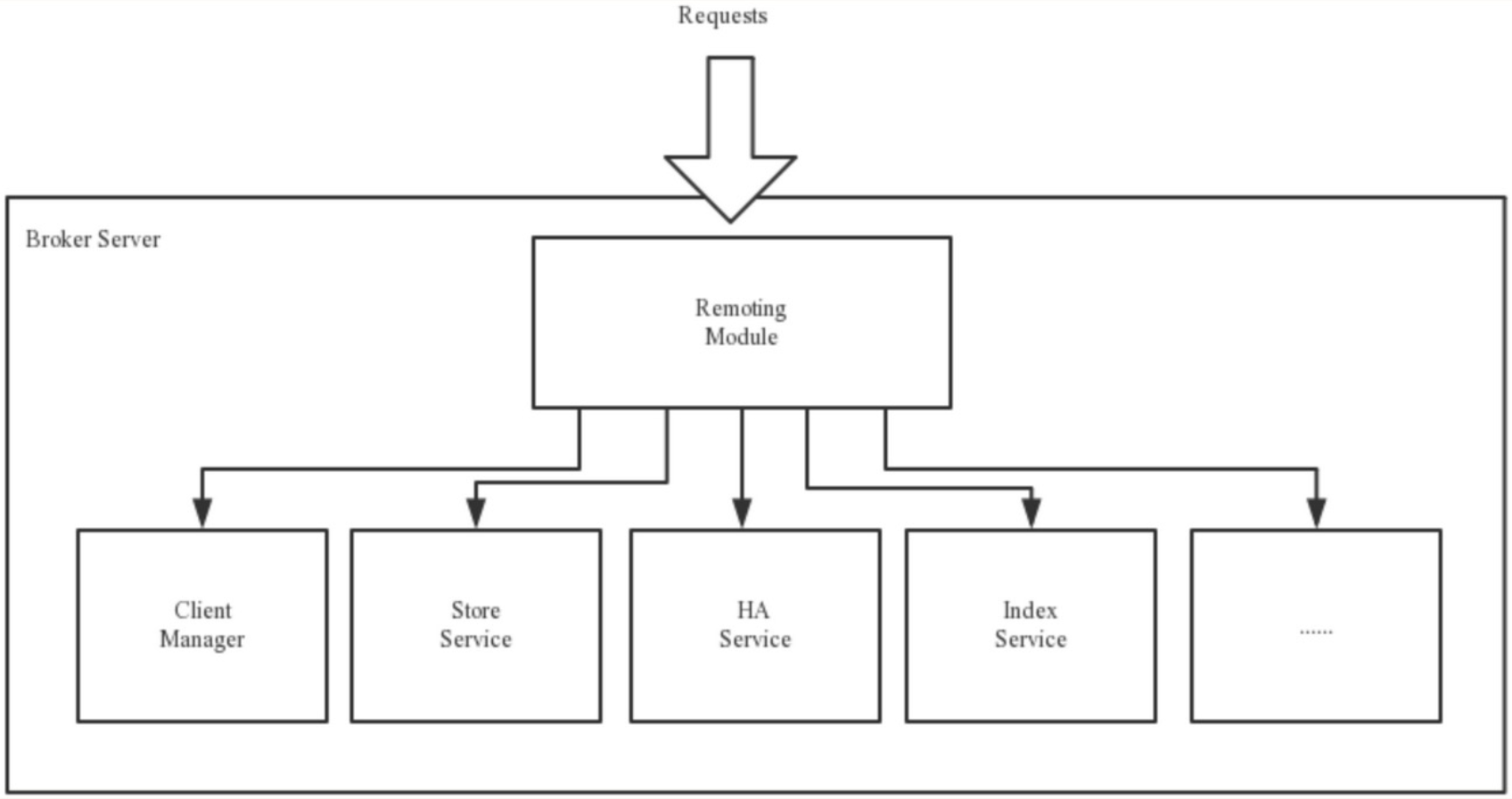
BrokerServer:Broker主要负责消息的存储、投递和查询以及服务高可用保证,为了实现这些功能,Broker包含了以下5个重要子模块:
- Remoting Module:整个Broker的实体,负责处理来自clients端的请求。
- Client Manager:负责管理客户端(Producer/Consumer)和维护Consumer的Topic订阅信息
- Store Service:提供方便简单的API接口处理消息存储到物理硬盘和查询功能。
- HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能。
- Index Service:根据特定的Message key对投递到Broker的消息进行索引服务,以提供消息的快速查询。
三、关键特性
1.单机支持1万以上持久化队列
- 顺序写,随机读。 consumerQueue是逻辑队列存储元数据信息,commitlog负责存储消息,consumerQueue只存储消息在commitlog中的位置信息,定长存储,支持串行方式刷盘。
2.刷盘策略
- 同步刷盘
- 异步刷盘
二者的区别在于是写完PageCache直接返回,还是刷盘后返回
3.消息查询/消息回溯
- 支持MessageID和MessageKey查询。(业务场景:如某个订单处理失败,是消息没收到还是收到处理出错了)
- 按照时间来回溯消息,精度毫秒。(业务场景:订单分析,程序bug,导致今天从某个时间点的消息需要重新开始消费)
4.消息过滤
- Broker端(tag的哈希值比对,丢到对应的consumeQueue中) consumer端(直接和tag比)
5.消息获取机制
本质上都是Pull机制(据官方资料显示其中PushConsumer的实时性接近于push)。
- PushConsumer: consumer通过长轮询拉取消息后回调MessageListener接口完成消费,业务只需要完成MessageListener完成业务逻辑即可。(注册监听回调,一个线程专门长轮训从broker端拉消息,push到一个本地可配置队列)辑即可。(注册监听回调,一个线程专门长轮训从broker端拉消息,push到一个本地可配置队列)
- PullConsumer: 完全由业务系统去控制,定时拉取消息,指定队列消费,主要由业务控制。
6.单队列并行消费
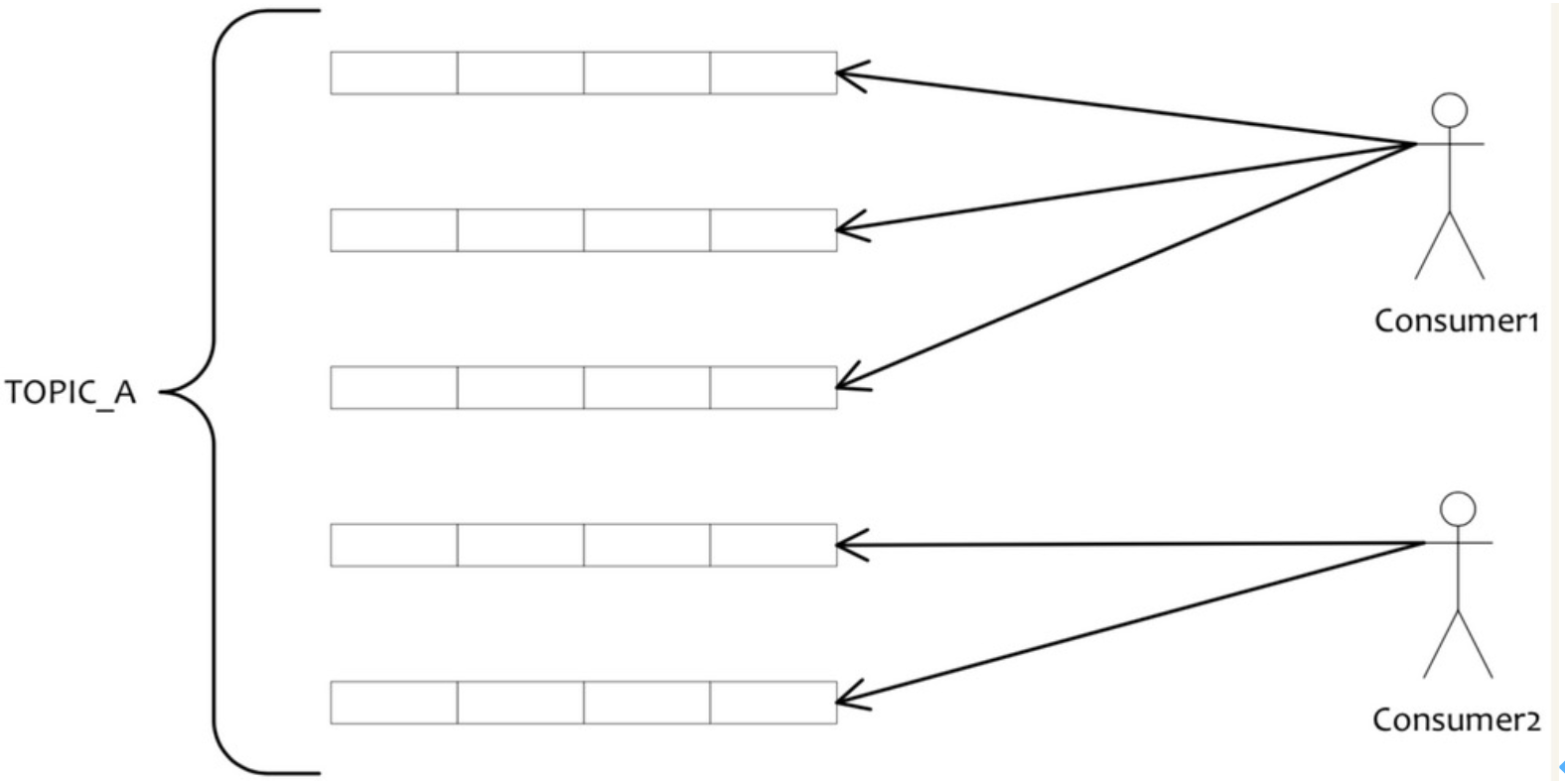
- 单队列一批消息拉取到消费端,既可以支持单线程串行有序消费,也可以支持多线程乱序消费提高并发性能,如下图所示:

采用滑动窗口方式并行消费,多个线程消费,提交offset都是最小offset。
7.消费负载均衡
都在客户端实现
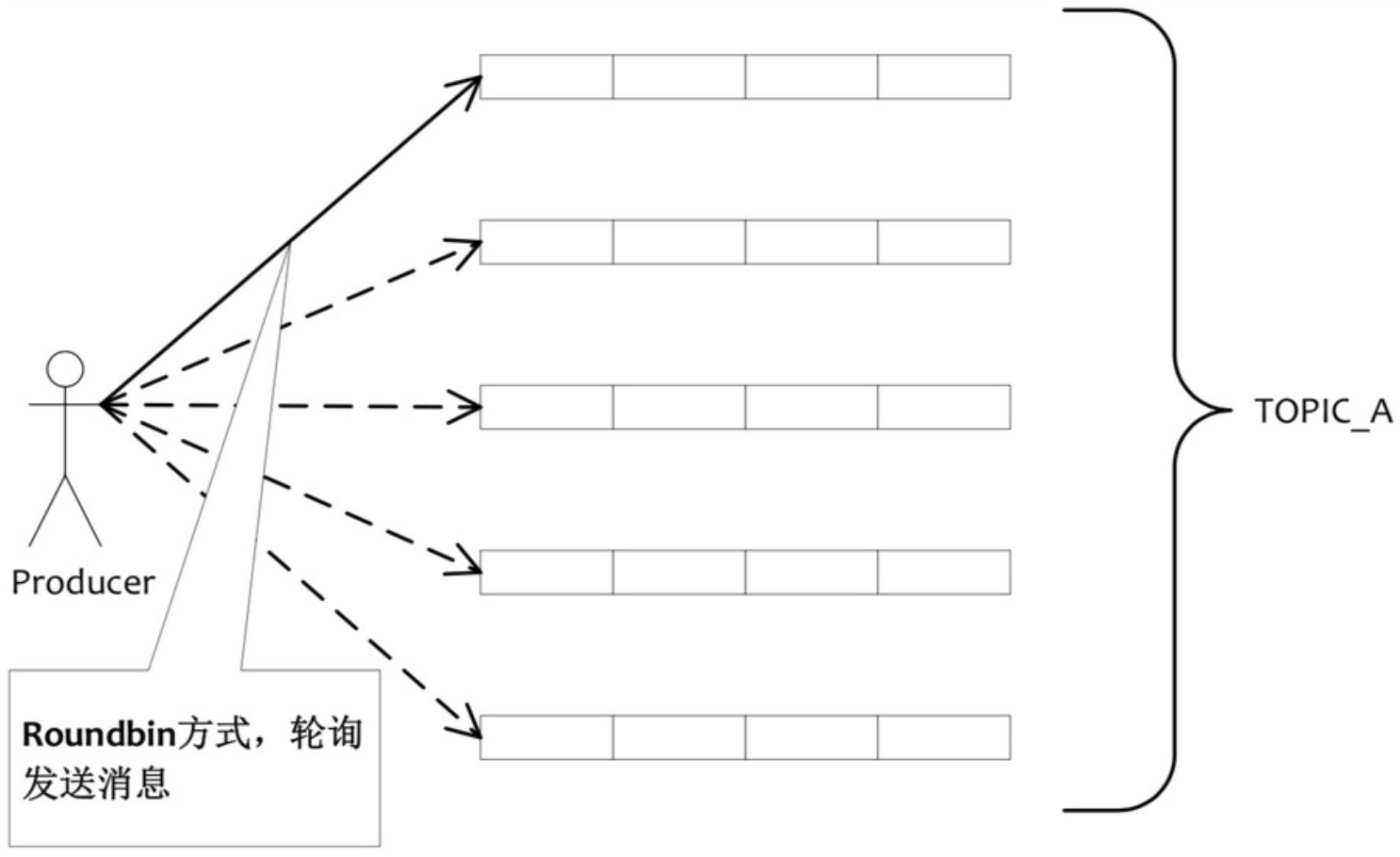
Producer端:从NameServer获取MessageQueue列表,RR选择具体的消息队列发送消息。
Consumer端: 从NameServer获取MessageQueue列表和其他Consumer状态信息,达到平均消费目的(consumer超过队列数则处于空闲状态)
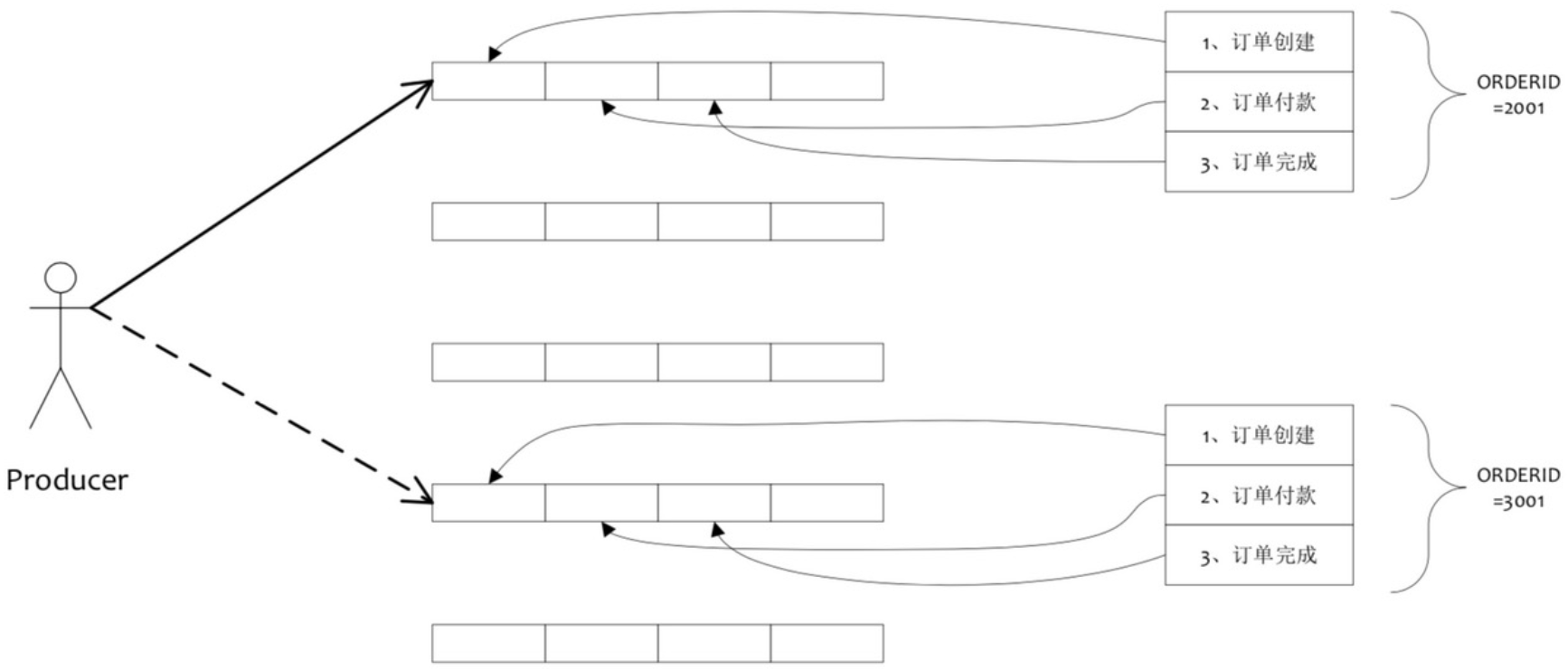
8.顺序消息原理
在RocketMQ中,主要指的是局部顺序,即一类消息为满足顺序性,必须 Producer 单线程顺序发送,且发送到同一个队列,这样 Consumer 就可以按照 Producer 发送 的顺序去消费消息。
- 普通顺序消息:Broker重启,队列总数发生变化,导致哈希取模后定位队列变化,导致短暂消息顺序不一致。
- 严格顺序消息:只要一台机器不可用,整个集群不可用。(同步双写保证)
9.事务支持
RocketMQ采用了2PC的方案来提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息,如下图所示:
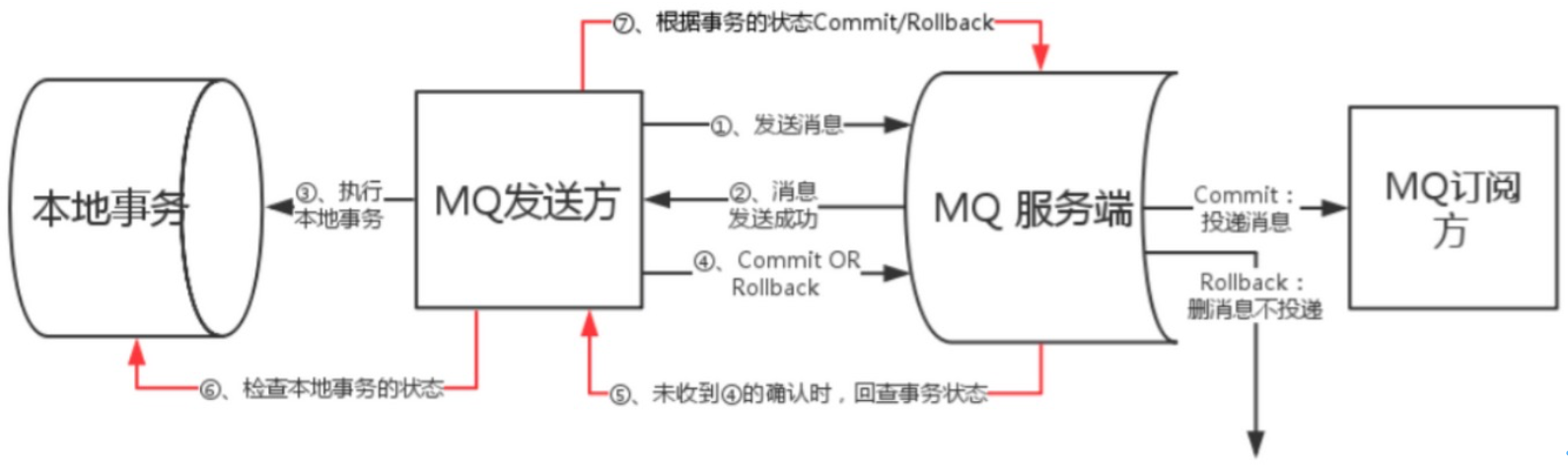
上图说明了事务消息的大致方案,分为两个逻辑:正常事务消息的发送及提交、事务消息的补偿流程
事务消息发送及提交:
- 发送消息(half消息)
- 服务端响应消息写入结果
- 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
- 根据本地事务状态执行Commit或者Rollback(Commit操作生成消息索引,消息对消费者可见)
补偿流程:
- 对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”
- Producer收到回查消息,检查回查消息对应的本地事务的状态
- 根据本地事务状态,重新Commit或者Rollback
- 补偿阶段用于解决消息Commit或者Rollback发生超时或者失败的情况。
10.延时消息
业务场景:支付曾经提过延时消费需求(对应消费失败后,延时多久再推送)
开源版本RocketMQ仅支持定时Level(几个梯度的延时,5s、10s、1min等) 阿里云的ONS支持定时level,以及制定毫秒级别延时时间
11.消息失败重试
- Producer端:
Producer 的 send 方法本身支持内部重试,重试逻辑如下:
(1) 至多重试 3 次
(2) 如果发送失败,则轮转到下一个 Broker
(3) 这个方法的总耗时时间不超过 sendMsgTimeout设置的值,默认 10s所以,如果本身向 broker 发送消息产生超时异常,就不会再做重试。 再发送失败由应用层自己做。
- Consumer端:
广播模式:发送失败的消息丢弃, 广播模式对于失败重试代价过高,对整个集群性能会有较大影响,失败重试功能交由应用处理 集群模式:将消费失败的消息一条条的发送到broker的重试队列中去,如果此时依然有发送到重试队列还是失败的消息,那就在cosumer的本地线 程
定时5秒钟以后重试重新消费消息,再走一次上面的消费流程。
12.Broker HA机制
- 同步双写:HA 采用同步双写方式,主备都写成功,向应用返回成功。
- 异步复制:slave启动一个线程,不断从master拉取commitlog中的数据,然后异步build出ConsumeQueue数据结构。
13.死信队列
由于某些原因消息无法被正确的投递,为了确保消息不会被无故的丢弃,一般将其置于一个特殊角色的队列,这个队列一般称之为死信队列。与此对应的还有一个“回退队列”的概念,试想如果消费者在消费时发生了异常,那么就不会对这一次消费进行确认(Ack), 进而发生回滚消息的操作之后消息始终会放在队列的顶部,然后不断被处理和回滚,导致队列陷入死循环。为了解决这个问题,可以为每个队列设置一个回退队列,它和死信队列都是为异常的处理提供的一种机制保障。实际情况下,回退队列的角色可以由死信队列和重试队列来扮演。
14.重试队列
重试队列其实可以看成是一种回退队列,具体指消费端消费消息失败时,为防止消息无故丢失而重新将消息回滚到 Broker 中。与回退队列不同的是重试队列一般分成多个重试等级,每个重试等级一般也会设置重新投递延时,重试次数越多投递延时就越大。举个例子:消息第一次消费失败入重试队列 Q1,Q1 的重新投递延迟为 5s,在 5s 过后重新投递该消息;如果消息再次消费失败则入重试队列 Q2,Q2 的重新投递延迟为 10s,在 10s 过后再次投递该消息。以此类推,重试越多次重新投递的时间就越久,为此需要设置一个上限,超过投递次数就入死信队列。重试队列与延迟队列有相同的地方,都是需要设置延迟级别,它们彼此的区别是:延迟队列动作由内部触发,重试队列动作由外部消费端触发;延迟队列作用一次,而重试队列的作用范围会向后传递。
四、不足之处
RocketMQ不管系统架构,还是底层存储都有居多亮点,以此来支撑的众多强大特性,不可否认也有居多不足之处:
- 没有实现自动感知分配的读写分离策略,只有当master消费性能过低时(由RocketMQ决定)才会将读请求分摊到slave上
- 不支持Master/Slave自动切换。RocketMQ开源版本目前还不支持把Slave自动转成Master,如果机器资源不足,需要把Slave转成Master,则要手动停止Slave角色的Broker,更改配置文件,用新的配置文件启动Broker。商业版本支持自动master/slave主从切换
- 不支持数据迁移,对服务扩容不太友好,也不灵活。如果服务需要扩容,只能增加服务器节点数了,然后新增queue分配到新节点上。如果新老机器负载不均衡,要么多增加queue到新机器上,要么替换性能较弱的老旧机器
- 不支持多挂载点。当今硬件发展日新月异,pc服务器性能越来越强大,一个物理机器会挂载很块多磁盘,但一个RocketMQ实例却只能读写操作一个挂载点数据,想榨干机器资源,操作多挂载点需要部署多实例或依靠docker容器等来实现