from keras.preprocessing.image import load_img, img_to_array
a = load_img('1.jpg')
b = img_to_array(a)
print (type(a),type(b))
输出:
a type:<class 'PIL.JpegImagePlugin.JpegImageFile'>,b type:<class 'numpy.ndarray'>
optimizer:
Adam :
算法思想 [1]:
Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。
数学表达式:
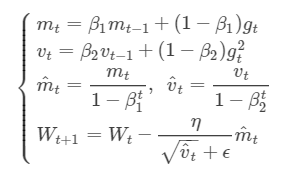
mt和vt分别为一阶动量项和二阶动量项;m^t,v^t为各自的修正值。
beta_1, beta_2为动力值大小通常分别取0.9和0.999。
Wt表示t时刻即第t次迭代模型的参数,gt=ΔJ(Wt)表示t次迭代代价函数关于W的梯度大小
ϵ是一个取值很小的数(一般为1e-8)为了避免分母为0,tensorflow作为backend时,ϵ=1e-7
评价:Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
lr: float >= 0. Learning rate.
beta_1: float, 0 < beta < 1. Generally close to 1.default 0.9,通常保持不变
beta_2: float, 0 < beta < 1. Generally close to 1.default 0.999,通常保持不变
epsilon: float >= 0. Fuzz factor. If None, defaults to K.epsilon(). decay: float >= 0. Learning rate decay over each update. amsgrad: boolean. Whether to apply the AMSGrad variant of this algorithm
from the paper "On the Convergence of Adam and Beyond".
SGD :
AdaGrad:
Reference:
https://blog.csdn.net/weixin_40170902/article/details/80092628
model.fit()
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1,
callbacks=None, validation_split=0.0, validation_data=None,
shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0,
steps_per_epoch=None, validation_steps=None, validation_freq=1)
model.fit_generator()
使用数据data_generator 传输数据,用于大型数据集,直接读取大型数据集会导致内存占用过高。
fit_generator(generator, steps_per_epoch=None, epochs=1, verbose=1,
callbacks=None, validation_data=None, validation_steps=None,
validation_freq=1, class_weight=None, max_queue_size=10, workers=1,
use_multiprocessing=False, shuffle=True, initial_epoch=0)
callbacks
list()值,当call中条件不满足时停止更新权重,
keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False)
monitor:需要监视的值,[acc,loss],如果fit种有validation_data,还可使用val_acc, val_loss等
min_delta: 改变的值如果小于min_delta, 将不视为有提高。
patience: 从最好的开始,经过patience个epoch仍未提高,则停止training
_obtain_input_shape()
keras 2.2.2中,keras.applications.imagenet_utils模块不再有_obtain_input_shape, _obtain_input_shape的根模块改为了keras_applications.imagenet_utils
形式改为了
_obtain_input_shape(input_shape,
default_size = 224,
min_size = 32,
data_format = K.image_data_format(),
require_flatten = True,
weights=None):_obtain_input_shape(input_shape,
default_size=224,
min_size=32,
data_format=K.image_data_format(),
include_top=include_top or weights)