EDADS系统包含了众多的时序模型和异常检测模型,这些模型的处理会输入很多参数,若仅使用默认的参数,那么时序模型预测的准确率将无法提高,异常检测模型的误报率也无法降低,甚至针对某些时间序列这些模型将无法使用。
若想有效地使用EGADS系统,那么必须了解EGADS系统的核心算法思想,并据此调优模型参数,来提高异常检测的准确率、降低误报率。
笔者通过阅读EDADS系统的TimeSeries模型和AnomalyDetection模型的源码,整理了模型的处理流程和常用算法的核心思想。如本文有理解错误之处,欢迎大家随时拍砖指正。
1. TSM时序模型
1.1 时序模型处理流程
时序模型接口主要包含的方法:train()、predict(),其类结构如下图所示。时序模型的主要处理流程:
- 先调用train方法训练出模型
- 在调用predict方法,得到时间序列的预测值
时序模型的实现类都遵循以上的处理流程。

1.2 时序模型列表

1.3 OlympicModel算法核心思想
OlympicModel 是时序数据的季节性模型,该算法的核心思想:某个数据点的预测值是历史n个同期数据的平滑平均值。特别适用于预测有周期的,甚至是嵌套周期的曲线。这里举例说明下什么是嵌套周期,例如:某个数据集每周的波动曲线相似,并且周一至周五是一类波动曲线,周六和周日是一类波动曲线。面对嵌套周期的波动曲线,仅以固定间隔作为周期的预测算法的效果不太理想。
OlympicModel模型的数据结构:
-
data存储观察值,底层的数据结构是
ArrayList -
model存储期望值,底层的数据结构是
ArrayList
OlympicModel模型训练的核心思想:
- 将data的第一个最小周期的数据作为期望值存入model
- 对于data剩余的数据点,计算出期望值后存入model
- 整个处理流程:针对每层嵌套周期(共w层),每个偏移量(共j个),计算出当前时间点、漂移到下一个时间点、漂移到上一个时间点的期望值,在这些期望值(
w*j*3)中选择一个与真实值偏差最小的,作为该时间点的期望值。- 期望值计算:找出历史同期的所有数据点,去掉可能的异常点(最大值和最小值),剩余数据点的平均值就是该时间点的期望值。
- 整个处理流程:针对每层嵌套周期(共w层),每个偏移量(共j个),计算出当前时间点、漂移到下一个时间点、漂移到上一个时间点的期望值,在这些期望值(
- 计算出预测值model与真实值data的所有误差指标(误差指标用于
AutoForecastModel筛选出哪个模型更优)
2. ADM异常检测模型
2.1 异常检测模型处理流程
异常检测模型的接口主要包含的方法:tune()、detect(),其类结构如下图所示。异常检测模型的主要处理流程:
- 先调用tune方法,根据训练数据调教出异常检测模型的阈值参数
- 在调用detect方法,检测出异常值
异常检测模型的实现类都遵循以上的处理流程。

2.2 异常检测模型列表

2.3 ExtremeLowDensityModel 算法核心思想
ExtremeLowDensityModel是基于密度的异常检测模型,其算法思想类似于聚类算法。输入的数据序列为预测值与真实值的差值的绝对值,然后把数据序列按照从大到小排序,在使用聚类算法把数据序列划分为两类:异常点簇和正常点簇,其临界值为异常点簇的最小值。这里聚类算法使用的距离公式为:3*正常点集合的标准差。
ExtremeLowDensityModel模型输入的数据结构:
- 观察值序列,长度为
n, 底层的数据结构是ArrayList - 预测值序列,长度为
n, 底层的数据结构是ArrayList
ExtremeLowDensityModel模型自适应阈值算法的核心思想:
- 计算出观测值和预测值的全部误差指标
- 对于每个时间点
t,计算出对应观察值和预测值的所有误差指标,误差指标有5个:mae(绝对误差)、smape、mape、mase、mapee. - 将误差指标组合成一个map,其中key表示误差指标,value表示误差指标对应的
n个误差值
- 对于每个时间点
- 对于每项误差指标,使用基于密度分布的方式计算出灵敏度,将灵敏度作为该项误差指标的阈值
- 从误差指标map中获取指定的误差指标对应的
n个误差值 - 根据
n个误差值,使用基于密度分布的方式计算出灵敏度(核心算法)- 把n个误差值,按照从大到小进行排序
- 初始化一个簇,把第一个数据点移入初始化簇
- 计算出剩余n-1个点的
标准差*3作为簇间最大距离的阈值 - 判断下个数据点与初始化簇的中心点距离是否小于
簇间最大距离的阈值 - 若小于,则从剩余数据点中移除下个数据点,加入到初始簇中,并重新计算初始化簇的中心点,重新计算剩余数据点的簇间最大阈值,并返回到步骤4
- 若大于,则停止迭代,此时会把全部数据点划分为两个簇
- 如果初始化簇的数据点个数占比其他簇的数据点个数,超过某个比例(0.05),那么认为不能做异常检测,返回正无穷大;否则把
初始化簇和其他簇分割开的临界点的值,作为灵敏度并返回
- 将误差指标和灵敏度保存到map,该map则保存了各个误差指标的阈值
- 从误差指标map中获取指定的误差指标对应的
ExtremeLowDensityModel模型检测异常算法的核心思想:
- 将各项误差指标(5个)的阈值存入数组
- 计算出每个时间点
t对应的真实值与期望值的各项误差指标值(5个) - 若待检测点处于检测窗口,且待检测点的任一误差指标值超过了对应的阈值,则待检测点为异常点
2.3 KSigmaModel 算法核心思想
Ksigma算法是一种常用的异常检测算法,如果整体数据服从正态分布,若一个点偏离均值K倍标准差,则该点被视为异常点。可以根据对业务的理解和时序曲线,找到合适的K值用来作为不同级别的异常报警。
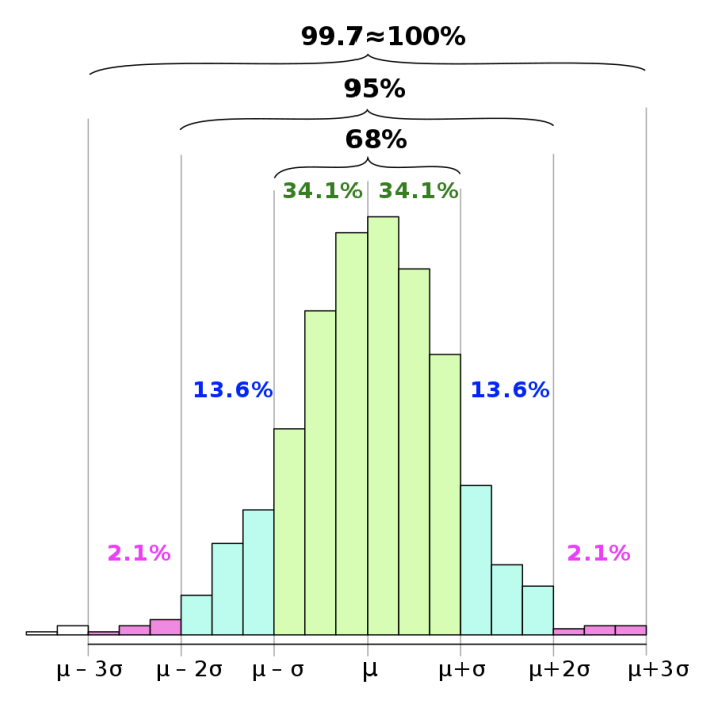
假设预测值与真实值的误差值序列符合正态分布,那么可以使用KSigmaModel模型做异常检测,其阈值计算规则为:均值 + 3*标准差。若某时刻t的数据点超过该阈值,则认为该时刻对应的数据点异常。
KSigmaModel模型输入的数据结构:
- 观察值序列,长度为
n, 底层的数据结构是ArrayList - 预测值序列,长度为
n, 底层的数据结构是ArrayList
KSigmaModel模型调教阈值算法的核心思想:
- 计算观测值相比预测值全部的误差指标
- 对于每个时间点
t,计算出对应观察值和预测值的所有误差指标,误差指标有5个:mae(绝对误差)、smape、mape、mase、mapee. - 将误差指标组合成一个map,其中key表示误差指标,value表示误差指标对应的
n个误差值
- 对于每个时间点
- 对于每项误差指标(共5项),使用简单的KSigma规则计算出异常灵敏度,将灵敏度作为该项误差指标的阈值
- 假设每项误差指标值序列均符合正态分布,计算出每项误差指标值序列的平均值和标准差
- 对于每项误差指标,其灵敏度(即阈值)为:
均值 + 3*标准差
- 将误差指标和灵敏度保存到map,该map则保存了各个误差指标的阈值
KSigmaModel模型检测异常的核心思想:
- 将各项误差指标(5个)的阈值存入数组
- 计算出每个时间点
t对应的真实值与期望值的各项误差指标值(5个) - 若待检测点处于检测窗口,且待检测点的任一误差指标值超过了对应的阈值,则待检测点为异常点
3. 总结
本文介绍了EGADS的TimeSeries模型和AnomalyDetection模型的处理流程和常用算法的核心思想。其中TimeSeries模型主要包含:训练和预测方法,AnomalyDetection模型主要包含:计算阈值参数和检测异常的方法。
关于TimeSeries模型介绍了可以预测嵌套周期的OlympicModel的核心思想,关于AnomalyDetection模型介绍了基于聚类思想计算出阈值的ExtremeLowDensityModel和基于正态分布数据的3Sigma法则计算出阈值的KSigmaModel的核心思想。