对于行存储(相比列存储)的表和索引,启用数据压缩最直接效果是能够减小数据占用的存储空间的大小;除了节省空间之外,数据压缩还能提高 I/O 密集型查询的性能,因为数据存储在更少的数据页(Data Page)中,SQL Server需要从磁盘读取的数据页更少,数据从Disk加载到内存的速度更快,查询的性能更好。但是,压缩和解压缩的过程都需要消耗额外的CPU资源,开发者必须均衡CPU资源,数据存储和硬盘IO的开销。
SQL Server提供两种数据压缩方式:行(Row)压缩和页压缩(Page),用于压缩表或索引数据,数据压缩对应用程序是透明的。
一,行压缩(Row Compression)
行压缩是将固定长度类型存储为可变长度存储类型,行压缩是自动进行的,对应用程序不可见,应用程序不需要做任何修改。
1,对于字符型
Char(200),这是一个固定长度的数据类型,但是在实际存储的时候,可能不会存储200个字符。在物理存储数据时,SQL Server后补空格以达到200个字符。如果将其转换为varchar(200),不需要后补空格,节省存储空间。行压缩无法处理XML、BLOB和MAX数据类型
2,对于数值型
在SQL Server 2005 SP2之前,decimal类型总是以固定数据存储的。根据值的精确度,每个decimal值都需要5到17字节的空间。新引入的Vardecimal存储格式是把decimal值以一个可变长度的格式进行存储。这种格式把小数值前后的零都去除,可以减少存储所需的空间。
SOL Server 2008数据压缩扩展了这个功能,对所有固定长度的数据类型都进行了处理,包括integer、char和float。现在数据不是以固定大小的字节进行存储,而是用最小所需的字节。开发者不需要修改数据类型,只需要启用行压缩功能,SOL Server 2008及其之后的版本就会使用最小的可变数据类型来存储数据。
3,行压缩的实现
启用行压缩只会更改与数据类型相关联的数据的物理存储格式,将固定长度的类型修改为可变长度的类型进行存储,而不会更改其语法或语义。新的记录存储格式主要有以下更改:
- 减少了与记录相关联的元数据开销。此元数据为有关列、列长度和偏移量的信息。在某些情况下,元数据开销可能大于旧的存储格式;
- 它对于数值类型(例如,integer、decimal 和 float)和基于数值的类型(例如,datetime 和 money)使用可变长度存储格式。 例如将decimal 修改为vardecimal;
- 它通过使用不存储空字符的可变长度格式来存储定长字符串。例如,将char 修改为varchar;
实现的原理,通俗解释是通过修改物理存储格式,将定长类型转换为变长类型,达到压缩数据的目的,但是物理存储格式的修改不会影响该字段使用的语法,例如:
- 对于数值类型和基于数值的类型来说,数据类型的长度是一定的,如BIGINT占用8个字节,但对于值1来说,只需要一个字节便可以存放,启用行压缩便可以节省7个字节的空间;
- 对于定长字符串类型,如果存放的数据未达到指定长度,会补空字符来填满,如类型CHAR(200)用来存放字符串"1"会花费200个字节,但启用行压缩后,会将填充的空字符移除,只需要1个字节便可以存放。将char(200)修改为Varchar(200)来存储数据。
- 对于类型bit来说,除自身消耗的空间外,还需要额外的4个bit来存放元数据,因此也可以从行压缩中获益。
4,数据压缩存在额外的开销(每列占用4Bit)
对于行压缩,每个column占用4bits,用于存储Column的长度。对所有数据类型的 NULL 和 0 值进行优化,除了4bits之外,使它们不占用任何字节。
二,页压缩(Page Compression)
行压缩是对每个数据行进行压缩存储,页压缩是对位于同一个数据页上的多行数据进行优化存储,减少数据的冗余,节省存储空间。页压缩是在行压缩的基础上进行前缀压缩,然后再进行字典压缩。
- 对于叶级别的数据页,页压缩首先对数据进行行压缩,然后再依次进行前缀压缩和字典压缩;
- 对于非叶级别的数据页,页压缩只对数据进行行压缩;
1,前缀压缩(Prefix Compression)
前缀压缩是指:在每个数据页上的所有数据行(Rows)中,对于给定的列(Column),如果其前缀模式相同,那么将相同的前缀压缩存储,以节省存储空间;
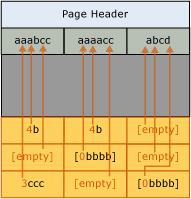
- 对于每一列,找出一个共用模式( Common Pattern),将列值替换为共用模式能够减少列的存储空间;共用模式存储在压缩信息CI(Compression Information)中,CI存储在每个Page中,靠近Page Header的下一个数据行中;
- 在Page Header之后,创建一个数据行,用于存储每列的共用模式;
- 对于每一列中的数据值,替换为共用,即引用短的前缀模式,以减少列的存储空间;
比如,有一个数据页,有三个数据行,每行有三个数据列:

对Page使用前缀压缩存储之后,SQL Server在Page Header之后,创建CI数据行,存储该数据页中每列数据的共用模式,数据页的存储结构如图:
2,字典压缩(Dictionary Compression)
字典压缩在前缀压缩之后执行,字典压缩是指:在每个数据页上的所有数据行(Rows)中,对所有列(Columns)查找重复的值,并将重复的值存储在压缩信息CI(Compression Information)中,将长的重复值替换为短的数据值,以节省数据空间。
Dictionary compression searches for repeated values anywhere on the page, and stores them in the CI area. Dictionary compression can replace repeated values that occur anywhere on a page.

页压缩比行压缩节省的存储空间更多。当表和索引使用页压缩后,对于一个新的页面,插入数据行时会对该行启用行压缩,直到该页已满无法存放新增加的行时,才会使用页压缩的算法计算启用页压缩是否能存放新增加的行,如果可以存放,则对该页进行页压缩并将新增加的行放到该页,如果不能存放,则不对该页启用页压缩,申请新页来存放新行。
三,表数据压缩
1,在表的Storage 选项卡查看表的存储属性
在压缩数据之前,通过 sys.partitions 的字段:data_compression 和data_compression_desc 查看table 或 index在每个Partition上的压缩状态;通过 sys.allocation_units 查看 total_Pages, Used_pages 等信息
select object_name(p.object_id) as table_name, p.partition_number, p.index_id, p.rows, p.data_compression_desc, au.Type_desc, au.total_pages, au.used_pages, au.data_pages from sys.partitions p inner join sys.allocation_units au on p.partition_id=au.container_id where p.object_id=object_id('table_name','U') order by p.partition_number ,p.index_id
2,在创建表时,指定数据压缩选项
create table dbo.Table_Name ( Column_Definition ) with( data_compression=page|row|none)
3,压缩存储现有表数据
alter table dbo.Table_Name rebuild with (data_compression=row|page)
4,在新建索引时,指定数据压缩选项
create index index_name on dbo.Table_Name ( index_key ) with (data_compression=row|page)
5,压缩存储现有索引的数据
alter index index_name on dbo.Table_Name rebuild with (data_compression=row|page)
四,估算数据压缩的效果(sp_estimate_data_compression_savings )
使用 sys.sp_estimate_data_compression_savings 估算对表或分区启用数据压缩(行或页),可能节省的存储空间
exec sys.sp_estimate_data_compression_savings @schema_name='dbo', @object_name='table_name', @index_id=NULL, @partition_number=NULL, @data_compression='page'
五,查看压缩成功的pages数量
通过函数 sys.dm_db_index_operational_stats 查看以Page类型压缩,节省的Page数量。该函数返回的结果集中有
- page_compression_attempt_count: Number of pages that were evaluated for PAGE level compression for specific partitions of a table, index, or indexed view.
- page_compression_success_count: Number of data pages that were compressed by using PAGE compression for specific partitions of a table, index, or indexed view.
SELECT ios.database_id, ios.object_id, ios.index_id, ios.page_compression_attempt_count, ios.page_compression_success_count, ios.page_compression_success_count/ios.page_compression_attempt_count as comression_rate FROM sys.dm_db_index_operational_stats(DB_ID(), OBJECT_ID('[dbo].[UserCDC]','U'), 1, NULL) AS ios
参考文档:
Data Compression: Strategy, Capacity Planning and Best Practices