SQL Server优化器基于开销(Cost)评估执行计划,选择开销最小的作为“最优化”的执行计划。计算开销的根据是索引及其统计信息,因此,索引和统计数据是非常重要的。查询优化器(Query Optimizer)使用统计信息对查询的开销进行评估(Estimate),选择开销最小的查询计划,作为最终的、“最优的”的执行计划。SQL Server自动为索引列或查询的数据列创建统计信息,统计信息包括三部分:头部(Header),密度向量(Density Vector) 和 分布直方图(Distribution Histogram)。
统计信息是数据分布的反馈,SQL Server根据数据更新的数量和特定的规则自动更新统计信息,一般情况下,表的数据量越大,SQL Server更新统计信息需要的数据更新量越大,随着数据的更新,有些表的数据不会及时更新,以至于统计信息过时,不能真实反映数据的分布情况,用户可以通过命令手动更新统计信息,但是更新统计信息需要扫描数据表,这可能是一个非常耗时的IO密集型操作,用户需要权衡性能的提升和资源的消耗。
一,查看统计信息
统计信息不是实时更新的,如果统计信息过期,查询优化器(Query optimizer)可能不能生成高质量的查询计划,必须有必要的调度程序,自动更新统计数据。数据库管理员(DBA)可以使用DBCC SHOW_STATISTICS 能够查看表或索引视图(Indexed view)的统计信息,以及最后一次更新统计信息的日期,如果统计信息过期,可以使用UPDATE STATISTICS命令手动更新统计信息,以使查询优化器依据正确的统计信息生成高效的查询计划。但是,并不是统计信息更新的越频繁越好,更新统计信息是IO密集型的操作,还会导致现有的查询计划的重新编译,建议不要太频繁地更新统计信息,在改进查询计划和查询计划的重新编译之间权衡开销,找到一个平衡点。
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target ) WITH STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
target 参数是:索引的名称,统计对象的名称,或者列名。如果target是索引名称,或统计对象的名称,那么该命令返回关于target的统计信息。如果target是数据列,那么该命令会自动在该列上创建统计,返回关于该列的统计信息。
1,统计对象
在SSMS中打开Table的属性,展开“Statistics”,这就是跟该表有关的统计对象:
查看统计对象 [cix_dt_test_idcode]的统计信息:
dbcc show_statistics('dbo.dt_test',[cix_dt_test_idcode])
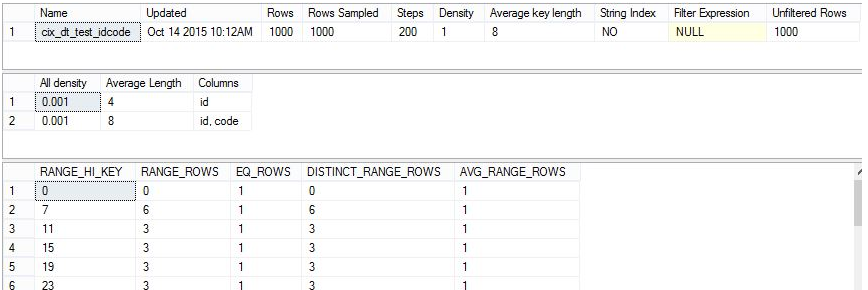
命令返回的统计信息包含三部分,分别是 头部信息,密度向量和分布直方图:
2,头部数据
第一个表是Header表,Name字段是统计对象的名称,

头部数据返回的字段说明:
- Updated字段:是统计信息最后一次更新的时间,通过该字段,可以判断统计信息是否过期。
- Rows字段:是统计信息更新时,表或索引视图(Indexed View)中的数据行数量,注意,该字段不会实时反应数据表的总行数。
- Rows Sampled字段:用于计算统计信息时的样本数据的总行数,如果 Rows Sampled < Rows,显示的直方图和密度结果是根据抽样数据进行估计的。
- Steps字段:是分布直方图中的梯级数。每个梯级都跨越一个列值范围,直方图梯级是根据统计信息中的第一个键列定义的,最大梯级数为 200。
3,密度向量
第二个表是密度向量(Density Vector),用于对键列(Key Column)执行密度分析,密度的计算公式非常简单:1和唯一值的比例,即 density= 1/(Distinct Value的个数)
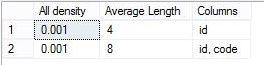
密度向量的总行数跟索引键的数量有关,每一行都是索引键的前缀组合,而唯一值是前缀组合列的无重复值。例如,如果统计对象包含索引键列(A,B,C),密度向量为3行,第一行是(A)的密度,唯一值是列A的无重复值;第二行是(A,B)的密度,唯一值是列A和B的无重复值;第三行是(A,B,C)的密度,唯一值是列A,B和C的无重复值。
示例中索引列是(id,code),索引列的密度是计算(id),(id,code)的密度,密度向量表中,All Density字段是统计对象计算的密度。
第一行的密度是0.001,由于列id的唯一值数量是1000,因此,1/1000=0.001
select count( distinct id) from dbo.dt_test
试想,如果列ID的重复值比较多,(ID,Code)组合的重复值比较少,那么(ID)的All Density的值大于(ID,Code)的密度,通过Density Vector可以看出数据重复率的趋势。
密度向量始终是从索引列的第一列开始统计,如果筛选子句(where,on)中没有包含索引的第一列,那么查询优化器不会使用索引,因此,索引列的顺序非常重要。
4,分布直方图
第三个表是分布直方图(Distribution Histogram),使用参数target的第一个索引键列(key column)来统计数据的分布,统计的数据是第一个索引列中非重复值的出现频率。如果统计的对象是复合索引,那么只统计索引列第一列的值的分布情况,忽略其他索引列。
本例的索引列是(ID,Code),那么统计的是ID 值的分布直方图:

分布直方图返回的数据列说明:
- RANGE_HI_KEY:直方图梯级的上限列值。列值也称为键值。
- RANGE_ROWS:其列值位于直方图梯级内(不包括上限)的行的估算数目。
- EQ_ROWS:其列值等于直方图梯级的上限的行的估算数目。
- DISTINCT_RANGE_ROWS:非重复列值位于直方图梯级内(不包括上限)的行的估算数目。
- AVG_RANGE_ROWS:重复列值位于直方图梯级内(不包括上限)的平均行数(如果 DISTINCT_RANGE_ROWS > 0,则为 RANGE_ROWS / DISTINCT_RANGE_ROWS)。
在分布直方图中,每一行都是一个范围(Range),
- 字段RANGE_HI_KEY是范围的最大值,范围的最小值大于上一条记录的最大值(RANGE_HI_KEY)。在直方图中,第一条记录是数据表的最小值,只有一条记录。
- 字段Range_Rows表示在当前范围中,不包括最大值(RANGE_HI_KEY)的总行数。
- EQ_Rows字段是当前范围中,等于最大值(RANGE_HI_KEY)的总行数。
- DISTINCT_RANGE_ROWS字段表示在当前范围中,除去RANGE_HI_KEY之外的所有数据行,其唯一值的数量。
- AVG_RANGE_ROWS字段是一个比例,当DISTINCT_RANGE_ROWS=0时,AVG_RANGE_ROWS=1;当DISTINCT_RANGE_ROWS>0时,AVG_RANGE_ROWS=Range_Rows/DISTINCT_RANGE_ROWS。
例如,当前范围中有(1),(2),(3),(1),(2)五个数据行,最大值是(3),且只有一个,因此,RANGE_HI_KEY=(3),EQ_Rows=1,除去最大值,共有4行数据,唯一值是2个,因此Range_Rows=4,DISTINCT_RANGE_ROWS=2,由于唯一值的数量不是0,因此,AVG_RANGE_ROWS=4/2。
二,验证分布直方图数据
下图是统计对象 cix_dt_test_idcode 的分布直方图:
第一条记录是数据表的最小值,也是该范围的最大值,数据只有一条:
直方图第一行:RANGE_HI_KEY=0, EQ_Rows=1 ,Range_Rows=0,DISTINCT_RANGE_ROWS=0,AVG_RANGE_ROWS=1
第二条记录,范围的最大值是7,范围的最小值是1,是大于第一条记录(0)的最小值;从1到7共有7条记录,除去最大值7之外,共有6行数据,所以,Range_Rows=6;这6行数据都不重复,因此DISTINCT_RANGE_ROWS=6;由于DISTINCT_RANGE_ROWS>0,因此 AVG_RANGE_ROWS=Range_Rows/DISTINCT_RANGE_ROWS=6/6=1。
直方图第二行:RANGE_HI_KEY=7,EQ_Rows=1,Range_Rows=6,DISTINCT_RANGE_ROWS=6,AVG_RANGE_ROWS=1
三,创建统计信息
对于大多数查询而言,查询优化器自动为索引列创建统计信息,对于非索引列,有时查询优化器为了产生高质量的查询计划自动为表创建必需的统计信息,系统自动创建的统计信息是单列的,统计对象的命名以_WA开头。用户也可以使用CREATE STATISTICS命令创建统计信息,一般是为多列的组合创建统计对象,以提高查询性能。
1,手动创建统计信息
通过CREATE STATISTICS 命令可以创建多列的统计对象:
CREATE STATISTICS statistics_name ON { table_or_indexed_view_name } ( column [ ,...n ] ) [ WHERE <filter_predicate> ] [ WITH [ FULLSCAN | SAMPLE number { PERCENT | ROWS } ] , [ NORECOMPUTE ] ]
参数注释:
- FULLSCAN:全表扫描以创建统计信息
- SAMPLE n {PERCENT | ROWS}:取样扫描,以创建统计信息, 如果设置 n=0,那么SQL Server创建一个空的统计信息,不包含任何统计数据。
- NORECOMPUTE:该选项用于禁用统计信息的自动更新,不建议使用
- WHERE 子句用于过滤表的子集,在子集上创建统计信息(过滤统计信息)
过滤统计信息对于特定的数据子集非常有用。
2,自动创建统计信息
数据库选项:AUTO_CREATE_STATISTICS 默认为ON,自动创建统计信息,仅应用于自动创建关系表的单列统计信息。
查询优化器根据查询谓词的使用情况,在表格上单独给某一列创建统计信息(这些单列暂时未创建直方图),协助查询计划的基数估计。通过该选项创建的统计信息,名称以 _WA 开头,查询语句如下所示:
SELECT OBJECT_NAME(s.object_id) AS object_name, COL_NAME(sc.object_id, sc.column_id) AS column_name, s.name AS statistics_name FROM sys.stats AS s INNER JOIN sys.stats_columns AS sc ON s.stats_id = sc.stats_id AND s.object_id = sc.object_id WHERE s.name like '_WA%' ORDER BY s.name;
四,更新统计信息
SQL Server 查询优化器使用这些统计信息来计算开销,选择最优的执行计划。查询优化器选择索引的一个标准是:索引列的选择性高,也就是说,该列的重复值少,重复率可以从直方图的Avg_Range_Rows和密度向量的All Desity字段中获取。
1,查看统计信息最后一次更新的时间
系统根据特定的规则更新统计信息,但是,随着数据的少量更新,数据表的统计信息不会实时更新,STATS_DATE 函数用于返回表或索引视图上统计信息的最后一次更新的日期:
STATS_DATE ( object_id , stats_id )
参数stats_id是统计对象的ID,可以通过sys.stats来查看统计对象及其ID,
2,统计对象和基础数据列之间的关系
系统视图:sys.stats_columns显式统计对象和基础表(或索引视图)的数据列之间的关系:
select object_name(s.object_id) object_name, s.name as statistics_name, sc.stats_column_id, col_name(sc.object_id, sc.column_id) as column_name, stats_date(s.object_id,s.stats_id) as stats_last_updated_date from sys.stats as s inner join sys.stats_columns as sc on s.stats_id = sc.stats_id and s.object_id = sc.object_id where s.object_id=object_id('table_name','U') order by s.name;
3,更新统计信息
用户有时需要手动更新统计信息,这可以通过UPDATE STATISTICS命令来实现:
update statistics dbo.dt_test [cix_dt_test_idcode]
在计算统计信息时,有多种扫描数据表的方式:
- FULLSCAN:扫描所有的数据行,开销最大,计算的统计信息最精确;
- SAMPLE number { PERCENT | ROWS }:取样本,只扫描样本数据;
- RESAMPLE:使用最新的样本数据计算统计信息,可能会导致全表扫描;
SQL Server查询优化器根据统计来评估开销,生成最优的执行计划。 选择适当的扫面方式,能够及时更新统计数据,使用最小的工作负载,实现性能的最大提升。
UPDATE STATISTICS schema_name . table_name { statistics_name | index_name } WITH FULLSCAN | SAMPLE number PERCENT| RESAMPLE
4,自动更新统计信息
数据库选项:AUTO_UPDATE_STATISTICS (自动更新统计信息)选项,默认值是ON,查询优化器自动确定统计信息何时可能过期,然后在查询使用这些统计信息时更新它们。通常情况下,从上次自动更新至今,如果期间积累了较大数量的数据变更,包括插入、删除及修改,或表结构变更等,均会造成统计信息过期。统计信息将在插入、更新、删除或合并操作更改表或索引视图中的数据分布后过期。 查询优化器通过计算自最后统计信息更新后数据修改的次数并且将这一修改次数与某一阈值进行比较,确定统计信息何时自动更新。
查询优化器在编译查询和执行缓存查询计划前,检查是否存在过期的统计信息。 在编译某一查询前,查询优化器使用查询谓词中的列、表和索引视图确定哪些统计信息可能过期。 在执行缓存查询计划前, 数据库引擎 确认该查询计划引用最新的统计信息。
数据库选项:AUTO_UPDATE_STATISTICS_ASYNC(异步自动更新统计信息) ,用于指定查询优化器是同步更新统计信息还是异步更新统计信息。默认为OFF,也就是说,在默认情况下,使用同步方式自动更新统计信息,查询计划始终使用最新的统计信息进行编译和执行,如果遇到统计信息过期,则会在查询编译前等待更新的统计信息。如果使用异步方式自动更新统计信息,查询计划使用现有的统计信息进行编译和执行,即使遇到统计信息过期,也会直接使用现有统计信息编译然后执行,即使可能由于统计信息过期造成编译不佳,执行计划非最优,但仍按照编译结果运行。