麻雀虽小,五脏俱全!本文试图用最简单的示例覆盖最多的知识点。文中主要通过加减法器的设计来介绍基于Gold的解释器(关于解释器和编译器的区别联系见《儿子和女儿-解释器和编译器的区别与联系》)开发方法,不仅介绍了基于Gold的词法分析和语法分析,同时还介绍了如何在自动生成的基本骨架代码上来完成语义分析、解释执行和错误提示功能。
1.目标介绍:
首先说一下,我们开发的解释器究竟是面对什么语言呢?例子非常简单,只是整数的加减法而已,输入源语言如下所示:
1+2+3
1 +22+ 333+4+ 555
要求如下:
(1)输入为32位正整数的和或差的表达式,表达式中终结符的前后和中间可以有不可见字符。
(2)如果表达式正确,输出其结果,如下所示:
输入:1 + 2+ 3 - 4
输出:2
(3)识别词法错误和语法错误:
输入:1+ a+1+ 3+ 534
输出:0行3列位置的字符不应该为a
(4)识别语义错误。
输入:1+9999999123456789+123456789
输出:0行2列:数字太大,超过32位界限
输入:2123456789+123456789
输出:0行11列:和太大,超过32位界限
输入:1-2123456789-123456789
输出:0行2列:差太小,超过32位界限
2. 内容纲要:
结合GOLD的开发流程,我决定按如下提纲介绍:
Part 1:加减法器的词法分析和语法分析;
Part 2:文法表文件的生成与引擎的介绍;
Part 3:GOLD基本骨架源码的结构介绍;
Part 4:如何添加解释执行代码;
Part 5:实现错误提示功能(包括词法错误、语法错误、语义错误);
Part 6:平凡小结——由简而繁
3.加减法器的词法分析和语法分析:
在前面介绍的Gold的开发方法(《【翻译】语法分析工具Gold介绍(2)——基本开发方法 》)中,我们知道第一步需要做的事情是设计加减法器的设计文法,如下所示:
!大小写不敏感,开始符号位expression
"Case Sensitive" = True
"Start Symbol" = <expression>!终结符
Number = [123456789]{digit}*
!BNF产生式
<expression> ::= <expression>'+'Number
| <expression>'-'Number
| Number
这个产生式文法入门相当容易,够直观。我不多解释,只说一点:在Gold文法中,不可见字符是默认被识别为分隔符的(比如1 2被识别为两个终结符‘1’和‘2’),一般不做理睬。如果你真要睬它,后面的骨架源码中有所介绍。
大家是不是觉得这个文法太简单了。在这里我不得不声明几句:
- 本文不深入讨论复杂的文法。一只蜂鸟和一只老鹰在生理构造上不会有根本上的不同。
- Gold帮助用户屏蔽掉了文法规约的内部过程,大大方便了用户。如果不是这样,这多如繁星的语法分析工具要来何用?
- 本文不是去做一个C、C#、java的编译器或解释器,而是告诉你这样做的基本原理。若你真正明白了纸船浮在水上的原理,即便是钢铁巨轮也不仅仅是个梦想。
- 本文在小结中会提到一些深入的东东。
3.文法表文件的生成与引擎的介绍
什么是文法表文件?简单说来,文法表存储了语言产生式导出的所有移进规约表、字符表等等等信息。这里涉及到编译原理中的一些复杂理论。佛祖保佑,幸好我们有语法分析工具。
不同的文法表文件可以被一个通用的引擎来读取,以便解析不同的语言。 比如,引擎如果读取Java语言所产生的文法表文件,就能解析Java语言编写的所有源码;引擎读取C#语言产生的文法表文件,就能解析C#语言编写的所有程序。
引擎以类库的形式存在,可以被用户所引用。
将文法保存到grm文件中,用软件Gold Builder打开,在测试成功后,选择Project=>Save the table,保存文法表文件(cgt格式),以后会被调用。
4.GOLD基本骨架源码的结构介绍
如何生成骨架源码?文法编译成功后,选择菜单Project=>Create the skeleton program,选择输出语言C#-Calitha engine Event based,输出文件保存为MyParser.cs。
Gold生成的源码的可读性非常高,这是我喜欢它的一个重要原因。下面主要介绍源码的组成。
4.1 终结符和非终结符的枚举定义:
enum SymbolConstants : int
{
SYMBOL_EOF = 0, // (EOF)
SYMBOL_ERROR = 1, // (Error)
SYMBOL_WHITESPACE = 2, // (Whitespace)
SYMBOL_MINUS = 3, // '-'
SYMBOL_PLUS = 4, // '+'
SYMBOL_NUMBER = 5, // Number
SYMBOL_EXPRESSION = 6 // <expression>
};enum RuleConstants : int
{
RULE_EXPRESSION_PLUS_NUMBER = 0, // <expression> ::= <expression> '+' Number
RULE_EXPRESSION_MINUS_NUMBER = 1, // <expression> ::= <expression> '-' Number
RULE_EXPRESSION_NUMBER = 2 // <expression> ::= Number
};
简单明了,主要是为了后面的使用。
4.2 MyPasser类:
public class MyParser
{
private LALRParser parser;//解析引擎
public MyParser(string filename)//若干构造函数
public MyParser(string baseName, string resourceName)
public MyParser(Stream stream)
private void Init(Stream stream)//初始化,这是在代码骨架中最关键的函数。public void Parse(string source)//解析函数
//读取终结符,同时负责处理终结符在语义上的错误
private void TokenReadEvent(LALRParser parser, TokenReadEventArgs args)
//根据终结符创建对象,开发者主要修改的函数private Object CreateObject(TerminalToken token)
//产生式规约,同时负责处理规约是可能出现的异常private void ReduceEvent(LALRParser parser, ReduceEventArgs args)
//根据规约动作创建返回对象,此处添加解释执行代码或者用于生成目标代码的代码,开发者主要修改的函数public static Object CreateObject(NonterminalToken token)
//当语言被识别为正确时,该函数被调用,此处可添加返回结果代码
private void AcceptEvent(LALRParser parser, AcceptEventArgs args)//发生词法错误是被调用,此处添加词法错误提示代码
private void TokenErrorEvent(LALRParser parser, TokenErrorEventArgs args)//发生语法错误时被调用,此处添加语法错误提示代码
private void ParseErrorEvent(LALRParser parser, ParseErrorEventArgs args)
}
4.3 一个联系所有组件的函数——MyParser.init()
private void Init(Stream stream)
{//读取文法表文件
CGTReader reader = new CGTReader(stream);
parser = reader.CreateNewParser();
parser.TrimReductions = false;
parser.StoreTokens = LALRParser.StoreTokensMode.NoUserObject;//将解析引擎的文法规约事件绑定到MyParser类中的事件处理函数ReduceEvent
parser.OnReduce += new LALRParser.ReduceHandler(ReduceEvent);
//将解析引擎的终结符读取事件绑定到MyParser类中的事件处理函数TokenReadEvent
parser.OnTokenRead += new LALRParser.TokenReadHandler(TokenReadEvent);
//将解析引擎的正确解析源语言事件绑定到MyParser类中的事件处理函数AcceptEvent
parser.OnAccept += new LALRParser.AcceptHandler(AcceptEvent);//将解析引擎的发生词法错误事件绑定到MyParser类中的事件处理函数TokenErrorEvent
parser.OnTokenError += new LALRParser.TokenErrorHandler(TokenErrorEvent);//将发生语法错误事件绑定到MyParser类中的事件处理函数ParseErrorEvent
parser.OnParseError += new LALRParser.ParseErrorHandler(ParseErrorEvent);
}
这个函数起到了中央枢纽的作用,将文法表文件、源语言、解析引擎、各个事件处理函数紧紧的联系在一起。
4.4 骨架源码的使用
在不破坏骨架源码的骨架结构的前提下,源码可以被任意的修改。当然也包括了MyParser的构造函数。
可以在任意C#项目中调用生成的解析器MyParser,当然别忘了将文法表文件(本例中是cal1.cgt)、引擎(本例中是Calithalib.dll和GoldParserEngine.dll)加入到C#项目中,还有.net版本应不低于2.0。
我建立了一个wpf项目,在GUI中调用解析器。代码如下:
//读入文法表文件
//tb2是一个文本控件,将其传入MyParser类,用于输出解析过程中的相关信息,比如错误信息和结果等等
//MyParser的构造函数已被修改,为的是引入文本控件tb2
MyParser parser = new MyParser(new FileStream("./Cal.cgt",FileMode.Open),tb2);
//tb1是一个文本输入控件,tb1.Text表示输入源码
parser.Parse(tb1.Text);
5. 如何添加解释执行代码
5.1 自定义类型
对于源语言,通过语法分析和词法分析,在源语言被正确解析后,所有的工作就可以看成语法树规约的过程。在词法分析和语法规约的过程中,对于每一个树节点都可以构造一个对象。这就需要我们自己来构造相应的类。
对于加减法器的文法,需要构造的类有两个,分别针对产生式中的Expression、Numeric符号。
class Expression
{
public Location_ loc;
public int e_value;//存储产生式规约时所计算的表达式的值
public Expression(int e_value, int lineNr, int columnNr) {}
public Expression(int e_value, Location_ loc) {}
}
class Numeric
{
public Location_ loc;
public int n_value;//存储产生式规约时的数字的值
public Numeric(int n_value, int lineNr, int columnNr {}
public Numeric(int n_value, Location_ loc){}
}
5.2 添加词法分析时的对象构造代码:
词法分析中,主要修改MyParser类中的函数为:public static Object CreateObject(NonterminalToken token)
该函数终结符识别对应的事件处理函数TokenReadEvent所调用。从CreateObject函数的定义可以看出,我们只需要对相应的终结符返回对象就可以了,加法器文法中只需要针对数字串返回Numeric对象。在CreateObject中添加如下代码:
private Object CreateObject(TerminalToken token)
{
switch (token.Symbol.Id)
{
……case (int)SymbolConstants.SYMBOL_NUMBER :
//Number
//todo: Create a new object that corresponds to the symbol
//return null;
return new Numeric( Convert.ToInt32(token.Text),token.Location.LineNr,token.Location.ColumnNr);……
}
throw new SymbolException("Unknown symbol");
}
5.3 添加语法分析时的对象构造代码:
词法分析中,主要修改MyParser类中的函数为:public static Object CreateObject(TerminalToken token)
该函数被语法规约所对应的事件处理函数ReduceEvent所调用。从CreateObject函数的定义可以看出,我们只需要对相应的产生式返回对象就可以了。在CreateObject中添加如下代码:
public static Object CreateObject(NonterminalToken token)
{
switch (token.Rule.Id)
{
case (int)RuleConstants.RULE_EXPRESSION_PLUS_NUMBER:
{
Expression a_plus = token.Tokens[0].UserObject as Expression;
Numeric b_plus = token.Tokens[2].UserObject as Numeric;
return new Expression(a_plus.e_value + b_plus.n_value, a_plus.loc);
}
case (int)RuleConstants.RULE_EXPRESSION_MINUS_NUMBER :
{
Expression a_minus = token.Tokens[0].UserObject as Expression;
Numeric b_minus = token.Tokens[2].UserObject as Numeric;
return new Expression(a_minus.e_value - b_minus.n_value, a_minus.loc);
}
case (int)RuleConstants.RULE_EXPRESSION_NUMBER :
return new Expression(((Numeric)(token.Tokens[0].UserObject)).n_value,
(token.Tokens[0].UserObject as Numeric).loc);
}
throw new RuleException("Unknown rule");
}
5.4 解析完成事件——执行结果
在以上代码添加完成后,这时,语法解释器就已经基本完成了,它可以读入正确加法器语言,输出结果。结果在哪能看到呢?
加法器语言被正确解析后,事件处理函数AcceptEvent被调用,在该函数中可以添加输出结果代码
private void AcceptEvent(LALRParser parser, AcceptEventArgs args)
{//ouputTB是传入到MyParser的文本控件
//args.Token.UserObject是产生式起始符号的所对应的用户对象。
outputTB.Text = (args.Token.UserObject as Expression).e_value.ToString();
}
看看输出结果截图:)
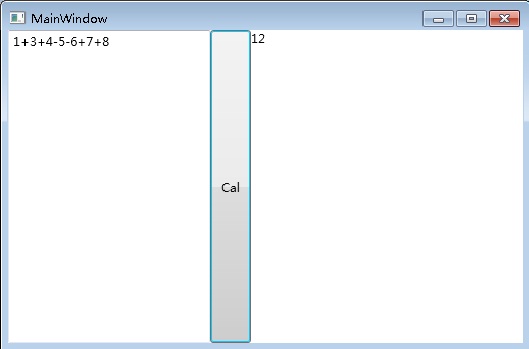
6. 错误提示功能实现:
6.1 词法错误提示:
在自动生成的词法错误处理函数TokenErrorEvent中添加错误提示代码:
private void TokenErrorEvent(LALRParser parser, TokenErrorEventArgs args)
{
//string message = "Token error with input: '"+args.Token.ToString()+"'";
string position = "Location Line:"+args.Token.Location.LineNr+" Column:" + args.Token.Location.ColumnNr+" ";
string message = "Token error with input: '" + args.Token.ToString() + "'";
//输出到GUI
outputTB.Text = position + message;
}
6.2 语法错误提示:
在自动生成的语法错误处理函数ParseErrorEvent中添加错误提示代码:
private void ParseErrorEvent(LALRParser parser, ParseErrorEventArgs args)
{
string position = "Location Line:" + args.UnexpectedToken.Location.LineNr + " Column:" + args.UnexpectedToken.Location.ColumnNr + " ";
string message = "Parse error caused by token: '"+args.UnexpectedToken.ToString()+"'";
//输出到GUI
outputTB.Text = position+message;
}
6.3 一个小扩展——语义错误提示:
关于语义分析,在自动生成的骨架代码中是没有的。恐怕任何一个语法分析工具都不可能替用户实现这种功能。语言符号终究只是符号,它的实际含义需要用户去定义。比如3”+“0,常识上说应该没有任何语义问题,然而”+“号在另一种语言中的实际含义也许就相当于四则运算中的除法,这是就出现问题了,分母为0。同一种文法表示的语言在不同的人眼中意义是不一样的,就像今天的骨感美女在唐朝也许就是绝对的丑女一样。因此语义错误只能由用户定义,无法由工具代劳。
在加减法器中,有几个语义上的规则需要满足:
- 数字不能超过32位整数的范围
- 数字之和不能大于32位整数的最大值
- 数字之差不能小于32位整数的最小值
为了确认错误的地址,需要保存错误的地址,于是创建Location_类,并为Numeric和Express类添加Location_属性。
为了检测计算是否超过32位整数范围,添加检测函数
//检查加法运算是否会超出范围
private static Boolean CheckSUM(int a, int b){}
//检查减法运算是否会超出范围
private static Boolean CheckDIFF(int a, int b){}
修改CreateObject(NonterminalToken token)函数中的规约代码,添加语义分析代码:
case (int)RuleConstants.RULE_EXPRESSION_PLUS_NUMBER:
//<expression> ::= <expression> '+' Number
{
Expression a_plus = token.Tokens[0].UserObject as Expression;
Numeric b_plus = token.Tokens[2].UserObject as Numeric;
if (CheckSUM(a_plus.e_value, b_plus.n_value))
return new Expression(a_plus.e_value + b_plus.n_value, a_plus.loc);
else
throw new Exception("the sum is too large or too small!");
}
case (int)RuleConstants.RULE_EXPRESSION_MINUS_NUMBER :
//<expression> ::= <expression> '-' Number
{
Expression a_minus = token.Tokens[0].UserObject as Expression;
Numeric b_minus = token.Tokens[2].UserObject as Numeric;
if (CheckDIFF(a_minus.e_value, b_minus.n_value))
return new Expression(a_minus.e_value - b_minus.n_value, a_minus.loc);
else
throw new Exception("the difference is too large or too small!");
}
现在一切ok了。能查出语义错误了。
7. 平凡小节
本文实现一个正整数的加减法器,实现了解释执行、词法错误提示、语法错误提示、语义错误提示等功能。
本例用C#实现,然而其意义应不止于此。如果是解释器,用C#开发可能执行慢一点,然而相比C#平台丰富的支持来说,应该值得;如果是编译器,由于任何一种语言可以用来开发编译器的前端,C#当然也在其中,所影响的只是编译的速度而已,对于编译出来的最终目标程序来说,执行速度没有差别。
本文几乎覆盖了编译器前端的所有基本概念。
到这里有人可能要说了,这样一个简单的加减法器,很多概念都没有提到,比如分支语言、循环语句号,比如符号表,比如函数嵌套。首先,分支语句、循环语句等过程语句只是控制语句中的一部分,跟加法器语句没有本质上不同。所不同的是,各种过程语句有它自己的特点,有着各自的解决技巧,比如分支语句就可以用栈来存储条件判断语句的值,这里就不细究了。
其次,函数嵌套,涉及到参数传递,用堆栈传值等等可以解决。
再次,符号表也涉及到不少编译的知识,比如作用域嵌套等等。
但是,总的来说,我认为上面那几点都只是单纯的技巧,拿本编译课本翻翻就好了。
还有,本文的目的还是介绍语法分析工具Gold的运用,语法分析生成工具没有提供自动语义分析的义务,也提供不了。本文中已经介绍了一种语义错误提示功能。所有复杂的语义,归根结底,都只是华丽的技巧,并不是高不可攀。只要了解了语义分析的实质,在课本的帮助下,一切复杂语义都是纸老虎,尽管这纸老虎还很不好折。
就简单的编译器和解释器来说,本文介绍的知识和方法应该够用了。如果要做一个复杂的编译器或解释器,比如C语言的编译器,那你还是去翻课本吧。
最后还是向大家推荐一下语法分析工具Gold,自动生成的代码的可读性太好了。其实我写这篇文章甚至比我学习Gold的时间还长……