集合框架体系
总体的体系图:
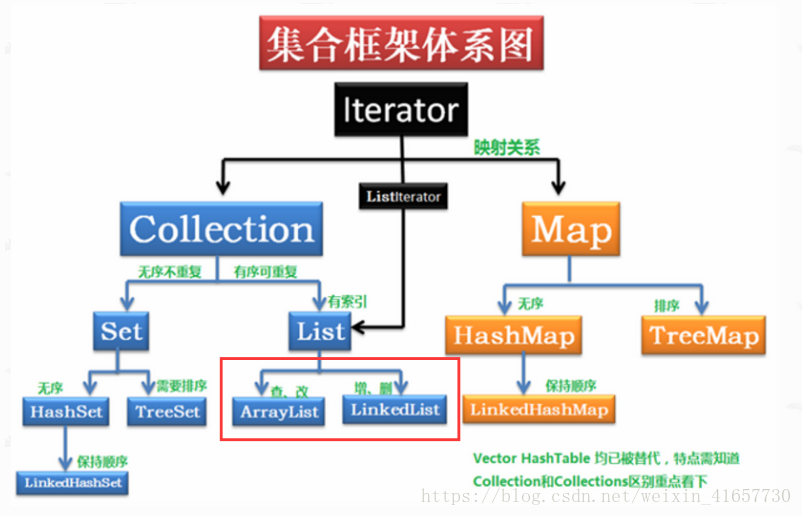
在学习体系之前先了解一下迭代器(Iterator):迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。对于集合的输出,有foreach和iterator,iterator更加的常用。
https://www.cnblogs.com/lxqiaoyixuan/p/7156944.html
其次再了解一下hash和hashcode:
hash函数特性:

调用hashcode()方法计算hash
hash表(散列表):https://www.jianshu.com/p/a89e9487a06c
hash和hashcode:https://blog.csdn.net/m0_37700275/article/details/82800590#commentBox
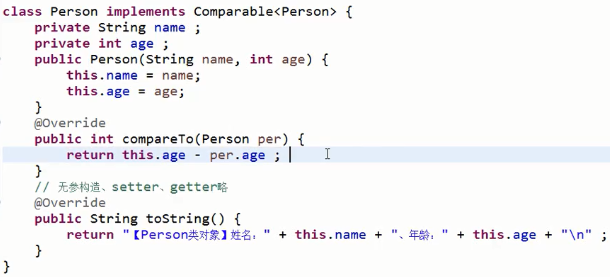
其次了解一下比较器(在涉及到比较的时候会用到比较器):在很多基本数据类型和引用数据类型中基本上都存在着排序的方法,但是对于自定义的类要实现排序,无法使用系统内部的类(比如Arrays.sort())实现数组排序或者比较需求,是因为没有提供比较规则,所以提供了一个comparable接口来定义比较规则
comparable:使用需要继承comparable接口并实现compareto方法,其中compareto方法中如果当前数据比传入的对象小则返回负数,如果大于那么返回正数,相等则返回0。下面实现一个最基本的比较:
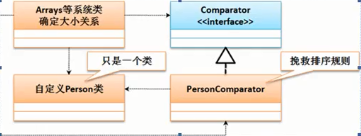
comparator:是一种补救措施,当系统开发完整又需要添加排序功能的时候,但是又不允许修改类的结构(无法实现comparable接口了),这个时候会使用comparator。在挽救中,想要排序的类(这里用Person类)和comparator没有任何直接关系,关系如图(PersonComparator是一个排序规则类):
下面来实现一个基本的comparator排序:
首先定义排序规则类:
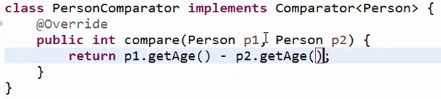
然后再利用arrays的sort方法传入排序规则类实现排序:
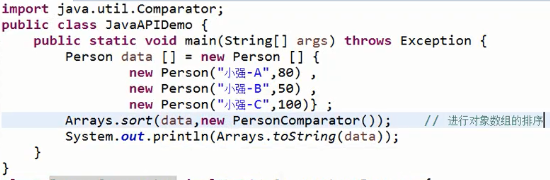
除非在万不得已的情况下使用comparator,正常情况下还是使用comparable。
comparable和comparator面试题:请解释comparator和comparable的区别?
comparable是在类定义的实现的父接口,主要用于定义排序规则,里面只有一个compareto方法。
comparator是挽救的操作,需要设置单独的比较器规则类实现排序,里面有compare()方法。
最后了解一下二叉树和红黑树:在这之前给出一个数据结构可视化的学习网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
各种树的结构:https://www.jianshu.com/p/3585745cc45b
二叉树的遍历:前,中,后只是指父节点遍历的顺序,前序就是 父节点->左子树->右子树,中序是 左子树->父节点->右子树,后序是 左子树 -> 右子树 ->父节点。

二叉树的存储:二叉树的存储有两种存储方式,顺序存储和链式存储。顺序存储是如图所示:

极度的浪费空间,如果说空间中的空节点很多的话,会造成空间的极度浪费。
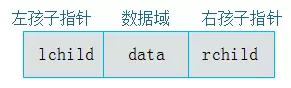
所以还有一种链式存储,又叫二叉链表:
二叉树节点的删除:分3种情况
https://blog.csdn.net/isea533/article/details/80345507
二叉树总体学习:https://www.cnblogs.com/skywang12345/p/3576452.html
红黑树:红黑树的本质就是在节点信息上追加了一个表示颜色的信息而已
特点(不允许红色节点和红色节点相连,但是没有说不允许黑色节点相连):

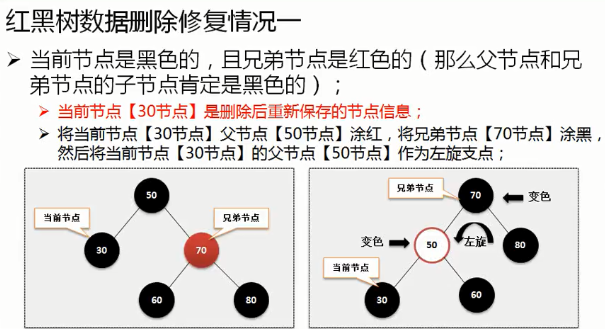
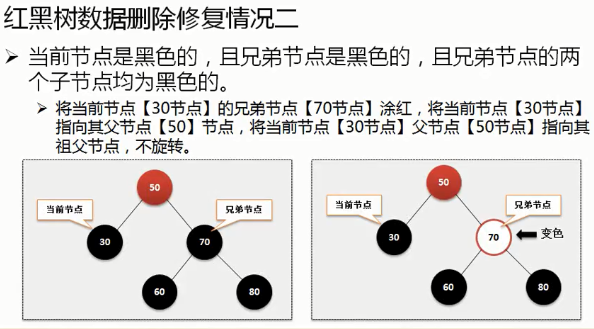
红黑树的自我修正(左旋,右旋,改变节点颜色),插入,删除操作:https://www.cnblogs.com/ysocean/p/8004211.html ,这篇文章中对于红黑树的删除操作并没有给出实际的分类情况,而是说删除太复杂,是通过对删除的节点做标记来完成删除操作的。实际上删除操作分为下面这几种情况:

需要旋转的4中情况的分析图(规则有的时候是联合使用):

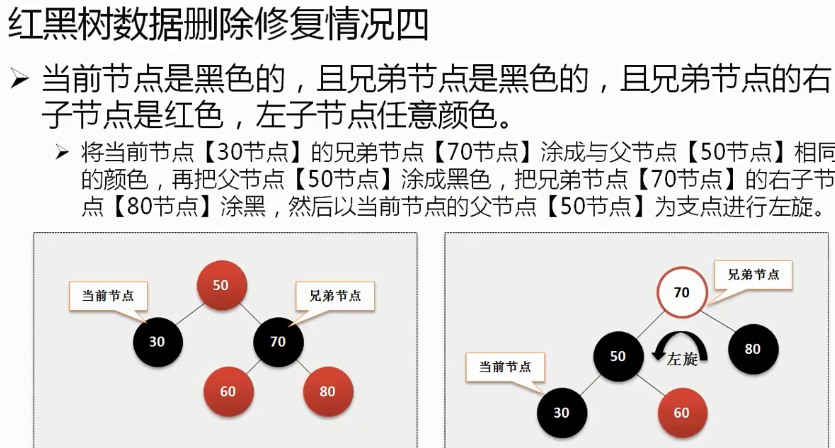
例子:

下面正式开始学习
Collecction(set,list):
Set(hashset,treeset):无序不重复,并不像list那样扩充了许多新方法,所以无法使用l像ist集合中提供的get方法,所以无法实现指定索引数据的获取。这是list和set的最大差别。
hashset:无序不重复,当添加重复的元素时,会无效。hashset判断重复和treeset判断重复不相同。利用的是object类中的方法进行比较。
![]()
首先会利用hashcode进行编码的匹配,如果编码不存在,说明不重复。如果编码存在,那么这个时候进行进一步比较,如果发现重复了,则此数据则不运行保存。在java程序中实现真正的重复元素判断用的是hashcode和equals两个方法共同完成的。而只有在排序要求的情况下才会利用comparable接口完成。
treeset:当利用treeset保存的数据的时候所有的数据都按照数据的升序进行自动排序处理。但进行排序的类必须要实现comparable接口,因为只有实现了这个接口才可以比较对象的大小关系。treeset实际上是利用treemap子类实现的集合数据存储,而treemap(树)则需要根据comparable来确认大小关系。
注意在使用自定义类进行比较的时候,在继承comparable后覆写的方法之中一定要将该类中的所有属性都依次比较,否则属性相同的时候会以为是重复数据,所以可以得到得到treeset实际上是通过comparable来确认重复数据的。覆写的方法如下:

但是如果类中的属性过多,那么这将是一个很复杂的过程,所以在实际的开发中首选hashset子类。
List:
list和ArrayList:https://www.cnblogs.com/zcscnn/p/7743507.html
基本用法比较:https://blog.csdn.net/ftell/article/details/80826235
深入ArrayList:https://www.cnblogs.com/qingchunshiguang/p/6103731.html
Linkedlist和ArrayList对比:https://blog.csdn.net/weixin_41657730/article/details/82462156
Map(子类有hashmap,treemap,hashtable,linkedhashmap):对于map集合的数据保存格式就是按照“key=value”的形式存储的,如果key重复,则会出现IllegalArgargumentException(如果是hashmap就会覆盖)。如果说key为null,那么就是空指针异常。
HashMap(最常见):最常见的map
a.主要特点是无序,tree是有序。
b.在设置了相同的key的内容的时候put方法会返回原始的数据内容,如果没有相同的key则返回null。
hashmap的原理:https://baijiahao.baidu.com/s?id=1618550070727689060&wfr=spider&for=pc
面试题1:hashmap进行put操作的时候是如何进行容量扩充的?
a.首先会在hashmap中提供一个常量,作为初始化的容量配置,默认大小是16。
b.当保存的容量达到了一个阈值(默认是0.75),这里就是当保存了(16*0.75=12)个元素之后,就会进行容量的扩充。
c.在进行扩充的时候hashmap采用的是成倍的容量扩充,即每一次都扩充2倍(通过对老的容量向左移一位)。
面试题2:请解释hashmap的工作原理(jdk1.8之后开始,hashmap在jdk1.8之后引入红黑树,因为大数据时代的来临导致数据的爆棚,使得hashmap对数据量的存储急剧增加,如果说还是使用原本的链表存储大量的数据,会导致效率低下)
a.hashmap中的存储依然是利用了node类完成,这种情况下的数据结构解释链表和二叉树(链表时间复杂度O(n),二叉树时复杂度O(logn))。
b.从jdk1.8开始,hashmap的实现发生了改变,因为要适应大数据时代的到来,所以其存储结构发生了变化,并且在hashmap的内部提供了重要的常量:
 ,在对hashmap进行数据保存的时候,如果保存的个数没有超过阈值8,那么会按照链表的方式进行存储,而如果超过了这个阈值,则会把链表转化成红黑树以实现树的平衡,并且利用左旋和右旋保证查找的性能。
,在对hashmap进行数据保存的时候,如果保存的个数没有超过阈值8,那么会按照链表的方式进行存储,而如果超过了这个阈值,则会把链表转化成红黑树以实现树的平衡,并且利用左旋和右旋保证查找的性能。
面试题3:hashmap的容量为什么是2的n次方?
其中一个主要的方面就是通过hashcode和数组长度通过与运算来计算索引值。详细见下
https://blog.csdn.net/j1231230/article/details/78072115
红黑树产生的问题:为什么使用了红黑树还说hashmap是无序的?
因为和treemap不同,treemap是直接将键值对中默认按照键的升序进行排序。而hashmap首先是按照键值转化成的hashcode存储在hashmap的数组中,当出现碰撞的时候才存储在下面的链表中,如果说这个时候链表过长(超过8个)就会优化为红黑树,方便查找的时候更快,所以实际上红黑树在hashmap中的作用是为了解决碰撞过多导致的检索慢的问题。实际在数组中还是无序的,数组查找时间复杂度是O(1)快于treemap,所以如果不用到排序的时候还是使用hashmap效率更高。
hashmap深入理解文章:https://blog.csdn.net/visant/article/details/80045154
Linkedhashmap(有序的hashmap,属于hashmap的子类,注意这里的有序指的是遍历顺序符合插入顺序):https://www.jianshu.com/p/8f4f58b4b8ab
Hashtable(最早的一批动态数组实现类,很少使用了):hashtable在进行数据存储的时候,如果key或者value为空都会出现空指针异常。
ConcurrentHashMap(hashtable的替代者,线程安全,分段):
jdk1.7下的concurrenthashmap:
在jdk1.7和1.8的实现不相同,jdk7中采用的是分段的数组加链表实现,1.7中的存储结构如下:
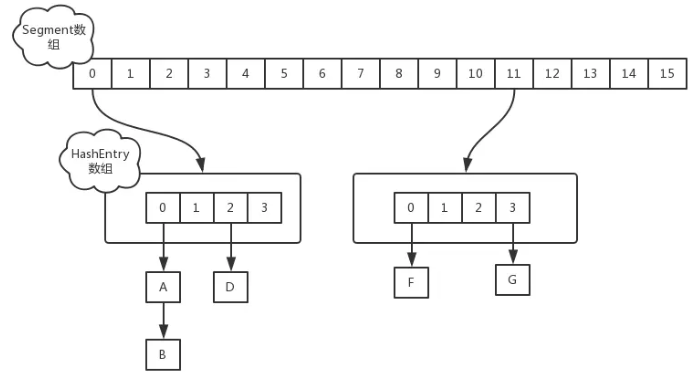
面试细节:https://www.cnblogs.com/heyonggang/p/9112731.html
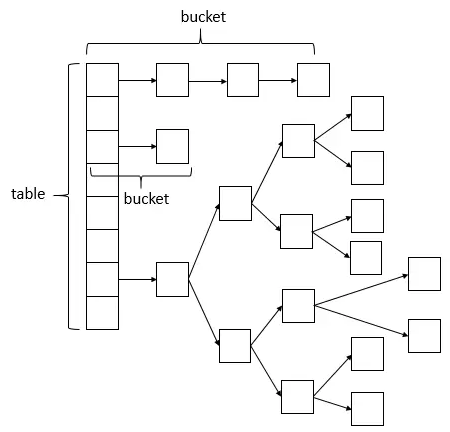
jdk8下的concurrenthashmap(采用CAS + synchronized):
a.将Segment抛弃掉了,直接采用Node(继承自Map.Entry)作为table元素。
b.修改时,不再采用ReentrantLock加锁,直接用内置synchronized加锁,java8的内置锁比之前版本优化了很多,相较ReentrantLock,性能不并差。
c.size方法优化,增加了CounterCell内部类,用于并行计算每个bucket的元素数量。
面试题:请解释hashmap的hashtable的区别?
hashmap中的方法属于异步操作,非线程安全,hashmap允许保存有空数据。
hashtable中的方法都属于同步方法,线程安全,hashtable不允许保存空数据,否则出现空指针异常。
TreeMap:底层通过红黑树实现
几种map的对比:
