一、爬虫概述及正版密钥获取
爬取的页面: www.dell-lee.com/typescript/demo.html?secret=secretKey
密钥secretKey值获取(会不定期变更):https://git.imooc.com/coding-412/source-code
二、TypeScript基础环境搭建
①nodejs下载安装
②VSCode点击左下角齿轮状的图标,在弹出的菜单中选择【Settings】,打开设置窗口
quote引号 —— 选single
tab缩进 —— Tab Size选2
save保存格式化 —— 勾选Format On Save
③VSCode点击左边方块Extensions,搜索插件Prettier, install下载开启
④安装TypeScript
VSCode点击上方Terminal,New Terminal开启TERMINAL面板
npm install typescript@3.6.4 -g
⑤typescript compile使用typescript对demo.ts进行编译,生成demo.js文件
tsc demo.ts
运行demo.js
node demo.js
⑥简化上一步,安装ts-node工具
npm install -g ts-node@8.4.1
直接运行demo.ts
ts-node demo.ts
三、使用SuperAgent和类型定义文件获取页面内容
①生成package.json文件
npm init -y
②生成tsconfig.json文件
tsc --init
③卸载全局安装的ts-node,安装在项目中
npm uninstall ts-node npm install -D ts-node@8.4.1 (-D = --save-dev)
④项目中安装typescript
npm install typescript@3.6.4 -D
⑤新建src目录,创建crowller.ts文件;pagekage.json中修改命令
"scripts": {
"dev": "ts-node ./src/crowller.ts"
},
运行npm run dev
⑥安装superagent工具在node中发送ajax请求取得数据
npm install superagent@5.1.1 --save
superagent是js语法,在ts里运行js会飘红,不知道怎么引用
ts -> .d.ts(翻译文件、类型定义文件)-> js
npm install @types/superagent@4.1.4 -D
⑦获取页面内容
import superagent from 'superagent';
class Crowller {
private secret = 'secretKey';
private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
private rawHtml = '';
async getRawHtml() {
const result = await superagent.get(this.url);
this.rawHtml = result.text;
}
constructor() {
this.getRawHtml();
}
}
const crowller = new Crowller()

四、使用cheerio进行数据提取
①安装cheerio库通过jquery获取页面区块内容
npm install cheerio --save
②安装类型定义文件@types/cheerio
npm install @types/cheerio -D
③数据提取
import superagent from 'superagent';
import cheerio from 'cheerio';
interface Course {
title: string
}
class Crowller {
private secret = 'secretKey';
private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
getCourseInfo(html: string) {
const $ = cheerio.load(html);
const courseItems = $('.course-item');
const courseInfos: Course[] = [];
courseItems.map((index, element) => {
const descs = $(element).find('.course-desc');
const title = descs.eq(0).text();
courseInfos.push({
title
})
})
const result = {
time: new Date().getTime(),
data: courseInfos
}
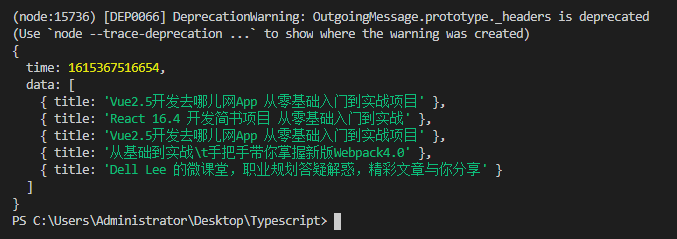
console.log(result);
}
async getRawHtml() {
const result = await superagent.get(this.url);
this.getCourseInfo(result.text);
}
constructor() {
this.getRawHtml();
}
}
const crowller = new Crowller()
五、爬取数据的结构设计和存储
//ts -> .d.ts(翻译文件)-> js
import fs from 'fs';
import path from 'path';
import superagent from 'superagent';
import cheerio from 'cheerio';
interface Course {
title: string
}
interface CourseResult {
time: number;
data: Course[];
}
interface Content {
[propName: number]: Course[];
}
class Crowller {
private secret = 'secretKey';
private url = `http://www.dell-lee.com/typescript/demo.html?secret=${this.secret}`;
getCourseInfo(html: string) {
const $ = cheerio.load(html);
const courseItems = $('.course-item');
const courseInfos: Course[] = [];
courseItems.map((index, element) => {
const descs = $(element).find('.course-desc');
const title = descs.eq(0).text();
courseInfos.push({
title
})
})
return {
time: new Date().getTime(),
data: courseInfos
}
}
async getRawHtml() {
const result = await superagent.get(this.url);
return result.text;
}
generateJsonContent(courseInfo: CourseResult) {
const filePath = path.resolve(__dirname, '../data/course.json')
let fileContent: Content = {};
//如果文件存在,读取以前的内容
if(fs.existsSync(filePath)){
fileContent = JSON.parse(fs.readFileSync(filePath, 'utf-8'));
}
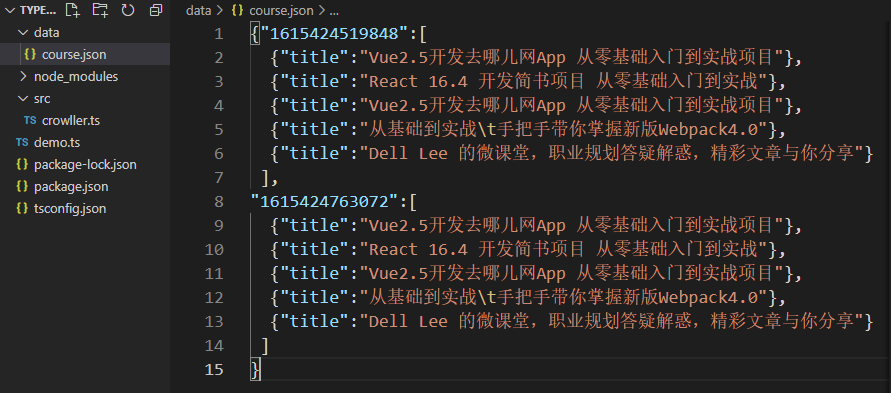
fileContent[courseInfo.time] = courseInfo.data;
return fileContent;
}
async initSpiderProcess() {
const filePath = path.resolve(__dirname, '../data/course.json')
const html = await this.getRawHtml();
const courseInfo = this.getCourseInfo(html);
const fileContent = this.generateJsonContent(courseInfo);
//存入现在的内容
fs.writeFileSync(filePath, JSON.stringify(fileContent));
}
constructor() {
this.initSpiderProcess();
}
}
const crowller = new Crowller()
六、使用组合设计模式优化代码
①爬虫通用类 - crowller.ts
//ts -> .d.ts(翻译文件)-> js
import fs from 'fs';
import path from 'path';
import superagent from 'superagent';
import DellAnalyzer from './dellAnaiyzer';
export interface Analyzer {
analyze: (html: string, filePath: string) => string
}
class Crowller {
private filePath = path.resolve(__dirname, '../data/course.json');
async getRawHtml() {
const result = await superagent.get(this.url);
return result.text;
}
writeFile(content: string){
fs.writeFileSync(this.filePath, content);
}
async initSpiderProcess() {
const html = await this.getRawHtml();
const fileContent = this.analyzer.analyze(html, this.filePath);
//存入现在的内容
this.writeFile(fileContent)
}
constructor(private url: string, private analyzer: Analyzer) {
this.initSpiderProcess();
}
}
const secret = 'secretKey';
const url = `http://www.dell-lee.com/typescript/demo.html?secret=${secret}`;
const analyzer = new DellAnalyzer();
new Crowller(url, analyzer)
②爬虫某一网页专向策略 - dellAnaiyzer.ts
import cheerio from 'cheerio';
import fs from 'fs';
import { Analyzer } from './crowller';
interface Course {
title: string
}
interface CourseResult {
time: number;
data: Course[];
}
interface Content {
[propName: number]: Course[];
}
//分析器
export default class DellAnalyzer implements Analyzer{
private getCourseInfo(html: string) {
const $ = cheerio.load(html);
const courseItems = $('.course-item');
const courseInfos: Course[] = [];
courseItems.map((index, element) => {
const descs = $(element).find('.course-desc');
const title = descs.eq(0).text();
courseInfos.push({
title
})
})
return {
time: new Date().getTime(),
data: courseInfos
}
}
generateJsonContent(courseInfo: CourseResult, filePath: string) {
let fileContent: Content = {};
//如果文件存在,读取以前的内容
if(fs.existsSync(filePath)){
fileContent = JSON.parse(fs.readFileSync(filePath, 'utf-8'));
}
fileContent[courseInfo.time] = courseInfo.data;
return fileContent;
}
public analyze(html: string, filePath: string) {
const courseInfo = this.getCourseInfo(html);
const fileContent = this.generateJsonContent(courseInfo, filePath);
return JSON.stringify(fileContent)
}
}
七、单例模式实战复习
①DellAnalyzer改为单例模式
private static instance: DellAnalyzer;
static getInstance() {
if(!DellAnalyzer.instance) {
DellAnalyzer.instance = new DellAnalyzer();
}
return DellAnalyzer.instance;
}
…… ……
private constructior(){}
②crowller.ts
const analyzer = DellAnalyzer.getInstance(); new Crowller(url, analyzer)
八、TypeScript的编译运转过程的进一步理解
①package.json增加命令
"build": "tsc -w" //对ts文件统一编译 -w当ts文件发生改变时自动检测编译
②tsconfig.json文件中控制编译生成的文件放入build目录
"ourDir": "./build"
③安装nodemon工具,通过监控项目文件的变化做一些事情
npm install nodemon -D
④package.json增加命令
"start": "nodemon node ./build/crowller.js"
⑤package.json配置nodemonConfig,忽略数据data发生变化时的编译
"nodemonConfig": {
"ignore": [
"data/*"
]
}
⑥安装concurrently工具,并行执行build和start命令
npm install concurrently -D
⑦package.json更改命令
“scripts": {
"dev:build": "tsc -w",
"dev:start": "nodemon node ./build/crowller.js",
"dev": "concurrently npm:dev:*"
}
注:项目源自慕课网