HTTP协议通信双方一定是客户端和服务器端,而且一定是由客户端发出请求,由服务器接受请求
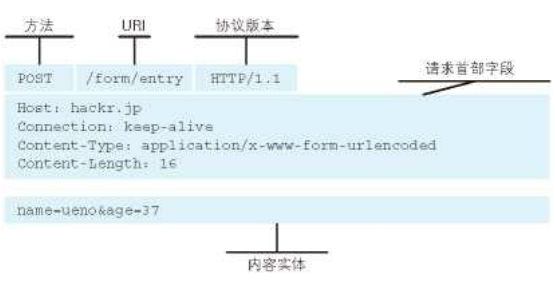
客户端发送的报文的构成:
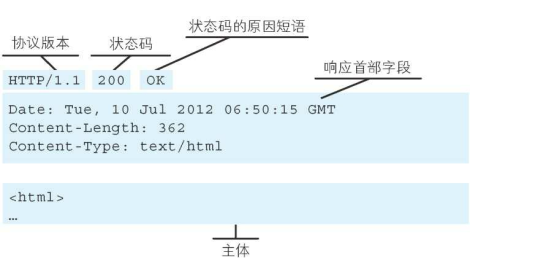
服务器端收到请求后响应的报文构成:
客户端向服务器端发送请求有多种方法:
get:获取资源,用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。如果请求的资源是文本,就保持原样返回;如果是像CGI(通用网关接口)那样的程序,则返回经过执行后的输出结果。
post:传输实体主体,get也可以传输,但一般不用get传输
put:传输文件,就想FTP协议的文件上传一样,要求在请求报的主体中 包含文件内容,然后保存到请求URI指定的位置,但因为不限身份,安全性太差,所以一般web网站不用该方法
head:获得报文首部,和get方法一样,只是不返回报文主体部分
delete:删除文件,同put
options:询问支持的方法,服务器端会返回:get,pust,options等内容
connect:要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信,主要使用SSL(安全套接层)和TLS(传输层安全)协议把通信内容加密后经网络隧道传输,服务器端返回200 OK后进入隧道
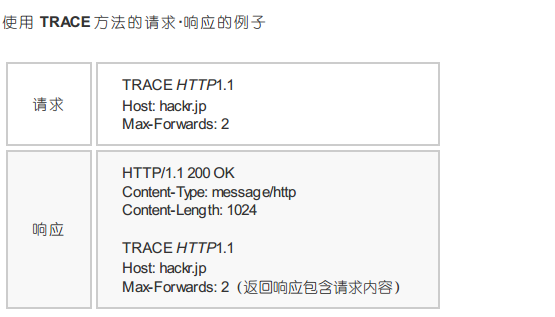
trace:追踪路径,让web服务器端将之前的请求通信环回给客户端的方法
针对HTTP某些不足之处的弥补和修正:
1.HTTP协议初始版本中每进行一次HTTP通信就要断开一次TCP连接,如果请求的页面中包含大量图片,每次请求都要连接,再断开,会造成通信量的开销,为了解决这个问题,HTTP/1.1用了持久连接的方法。
持久连接:只要任意一端没有明确提出断开连接,则保持TCP连接状态
持久连接使发送多个请求时不用一个接一个地等待响应,可以不等待响应,直接发送下一个请求,这就是 管线化
持久连接让请求变快,而管线化让请求更快
2.HTTP协议是一种无状态协议,即它不保存之前发生过的请求和响应的状态,无法根据之前的状态进行本次的请求处理。
优点:节省了服务器端的内存资源和cpu的消耗
弊端:在用户登录某个网站进行浏览时,每跳转新页面就要重新登陆
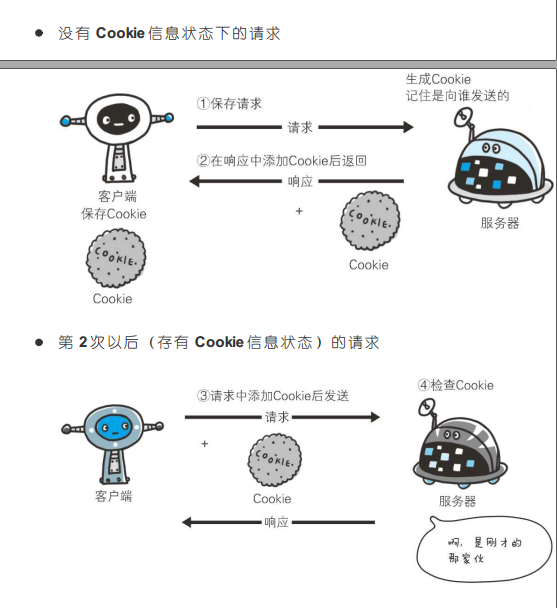
解决:Cookie技术:在请求和响应报文中写入Cookie信息来控制客户端的状态。Cookie会根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie,当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去,服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息