视频版见B站:Python实现AdaBoost算法-从零开始写代码_哔哩哔哩_bilibili
源文件、训练数据、说明图片下载:https://files.cnblogs.com/files/ljy1227476113/AdaBoost%E5%88%86%E7%B1%BB%E7%AE%97%E6%B3%95.7z


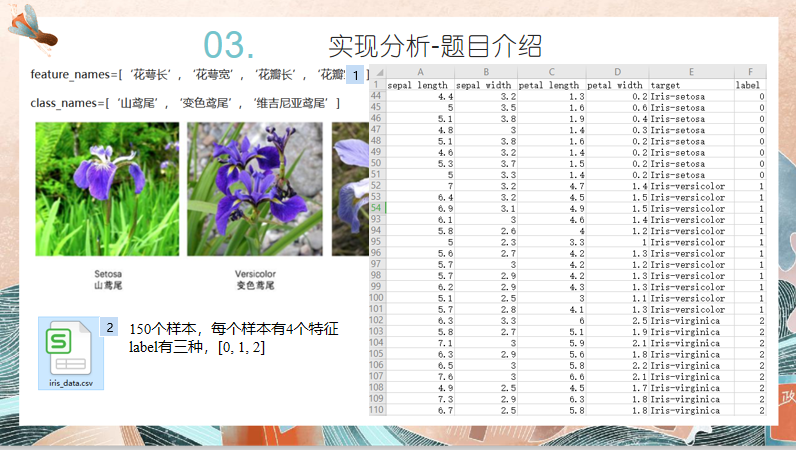
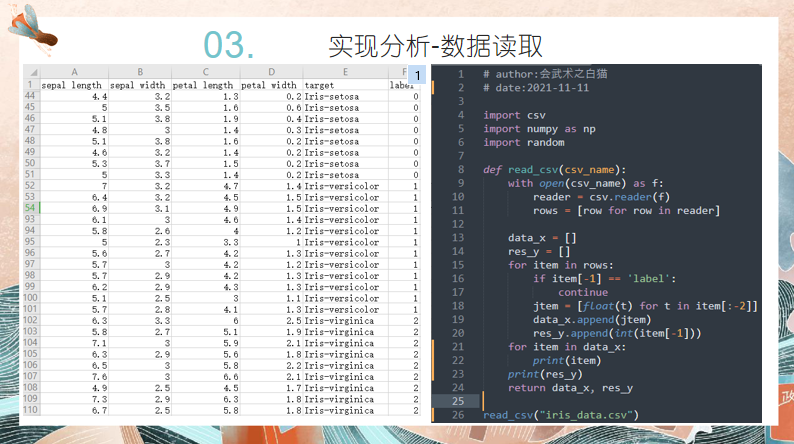
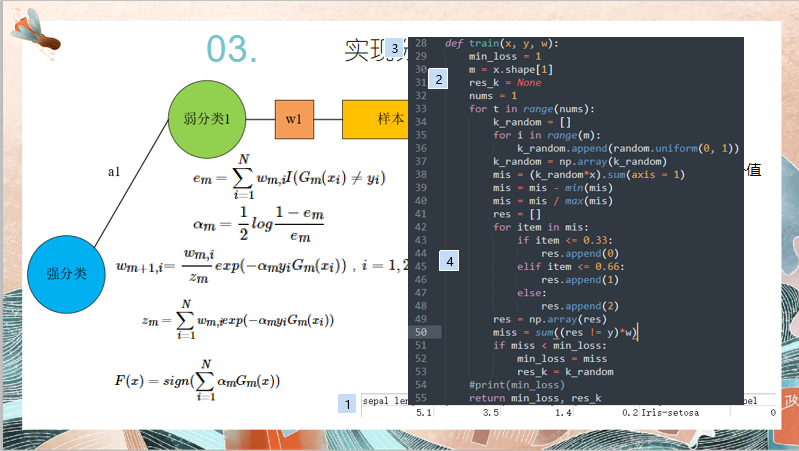
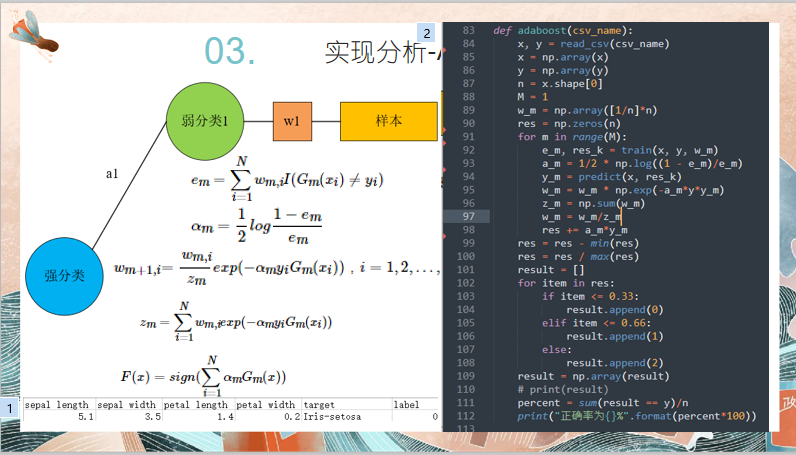

# author:会武术之白猫 # date:2021-11-11 import csv import numpy as np import random def read_csv(csv_name): with open(csv_name) as f: reader = csv.reader(f) rows = [row for row in reader] data_x = [] res_y = [] for item in rows: if item[-1] == 'label': continue jtem = [float(t) for t in item[:-2]] data_x.append(jtem) res_y.append(int(item[-1])) # for item in data_x: # print(item) # print(res_y) return data_x, res_y # read_csv("iris_data.csv") def train(x, y, w): min_loss = 1 m = x.shape[1] res_k = None nums = 10 for t in range(nums): k_random = [] for i in range(m): k_random.append(random.uniform(0, 1)) k_random = np.array(k_random) mis = (k_random*x).sum(axis = 1) mis = mis - min(mis) mis = mis / max(mis) res = [] for item in mis: if item <= 0.33: res.append(0) elif item <= 0.66: res.append(1) else: res.append(2) res = np.array(res) miss = sum((res != y)*w) if miss < min_loss: min_loss = miss res_k = k_random # percent = sum(res == y)/n # print("正确率为{}%".format(percent*100)) #print(min_loss) return min_loss, res_k # x, y = read_csv("iris_data.csv") # x = np.array(x) # y = np.array(y) # n = x.shape[0] # M = 1 # w_m = np.array([1/n]*n) # res = np.zeros(n) # train(x, y, w_m) def predict(x, res_k): mis = (res_k*x).sum(axis = 1) mis = mis - min(mis) mis = mis / max(mis) res = [] for item in mis: if item <= 0.33: res.append(0) elif item <= 0.66: res.append(1) else: res.append(2) res = np.array(res) return res def adaboost(csv_name): x, y = read_csv(csv_name) x = np.array(x) y = np.array(y) n = x.shape[0] M = 4 w_m = np.array([1/n]*n) res = np.zeros(n) for m in range(M): e_m, res_k = train(x, y, w_m) a_m = 1/2 * np.log((1 - e_m)/e_m) y_m = predict(x, res_k) w_m = w_m * np.exp(-a_m*y*y_m) z_m = np.sum(w_m) w_m = w_m/z_m res += a_m*y_m res = res - min(res) res = res / max(res) result = [] for item in res: if item <= 0.33: result.append(0) elif item <= 0.66: result.append(1) else: result.append(2) result = np.array(result) # print(result) percent = sum(result == y)/n print("正确率为{}%".format(percent*100)) csv_name = "iris_data.csv" adaboost(csv_name)