http://www.cnblogs.com/gujianhan/p/6030639.html
CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体? (图像语义分割)
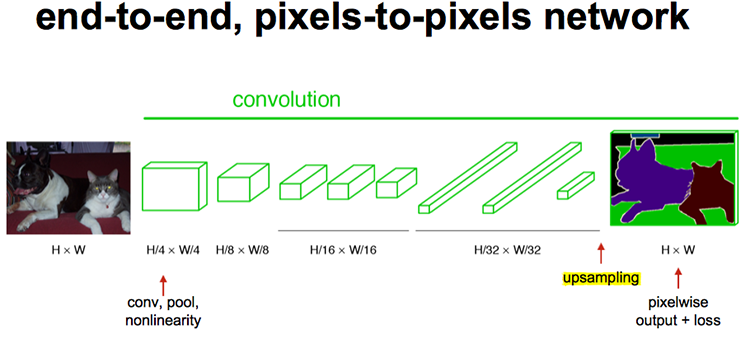
FCN(Fully Convolutional Networks)对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。
下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图:

全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
-
对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块,其余部分都是零。而在其中大部分块中,元素都是相等的。
-
相反,任何全连接层都可以被转化为卷积层。比如,一个 K=4096 的全连接层,输入数据体的尺寸是 7∗7∗512,这个全连接层可以被等效地看做一个 F=7,P=0,S=1,K=4096 的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成 1∗1∗4096,这个结果就和使用初始的那个全连接层一样了。
全连接层转化为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
如下图所示,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小 (通道数,宽,高) 分别为 (4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
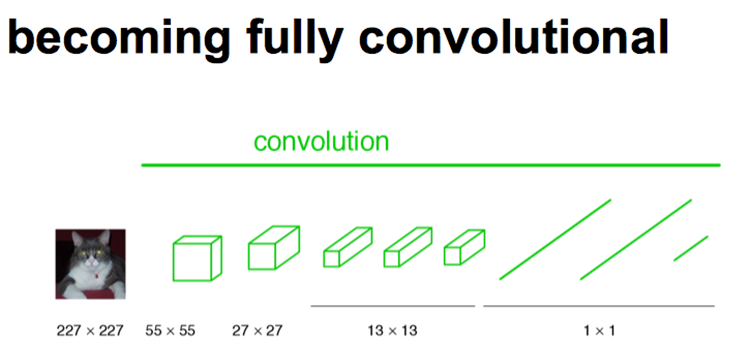
下图是一个全卷积层,与上图不一样的是图像对应的大小下标,CNN中输入的图像大小是同意固定resize成 227x227 大小的图像,第一层pooling后为55x55,第二层pooling后图像大小为27x27,第五层pooling后的图像大小为13*13。而FCN输入的图像是H*W大小,第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。
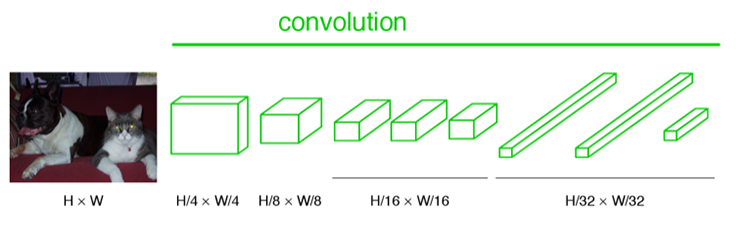
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特诊图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。
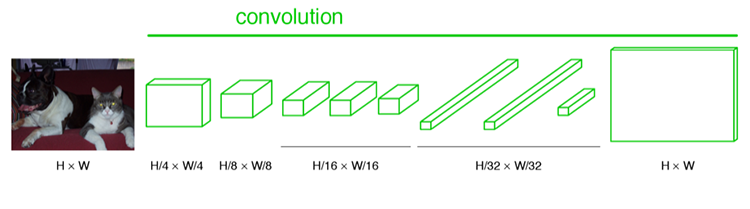
最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如下图右侧有狗狗和猫猫的图。
医疗图像分割框架
基于CNN的框架
对图像的每一个像素点进行分类,在每一个像素点上取一个patch,当做一幅图像,输入神经网络进行训练,参考论文:http://papers.nips.cc/paper/4741-deep-neural-networks-segment-neuronal-membranes-in-electron-microscopy-images
这种网络显然有两个缺点:
1. 冗余太大,由于每个像素点都需要取一个patch,那么相邻的两个像素点的patch相似度是非常高的,这就导致了非常多的冗余,导致网络训练很慢。
2. 感受野和定位精度不可兼得,当感受野选取比较大的时候,后面对应的pooling层的降维倍数就会增大,这样就会导致定位精度降低,但是如果感受野比较小,那么分类精度就会降低。
基于FCN框架
医学图像处理领域,有一个应用很广泛的网络结构—-U-net ,网络结构如下:
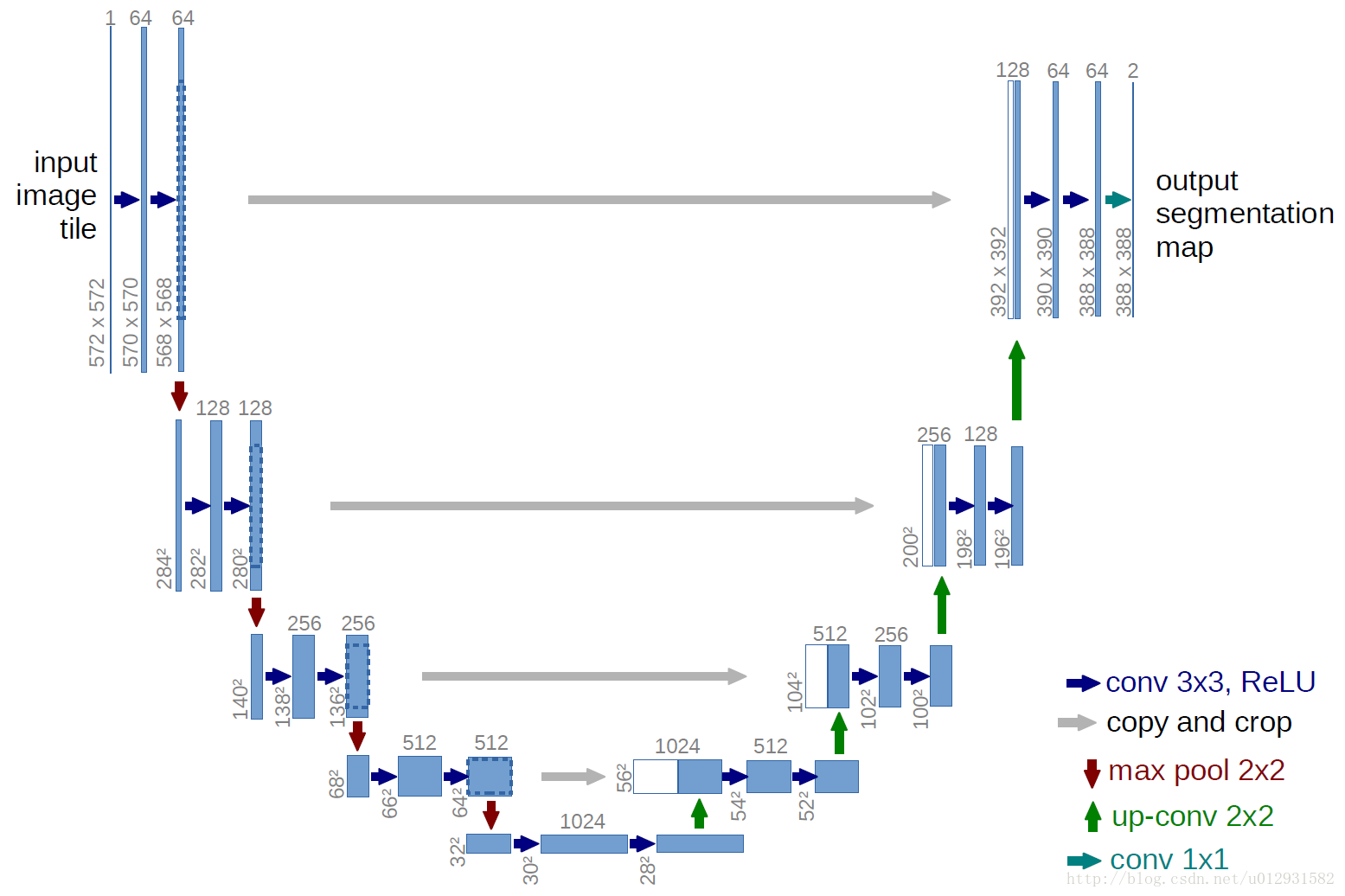
可以看出来,就是一个全卷积神经网络,输入和输出都是图像,没有全连接层。较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。