Hibernate---待完成

Hibernate 是一款免费开源的持久层框架,它对 JDBC 进行了轻量级的对象封装,将对象与数据库表建立了映射关系,使 Java 编程人员可以随心所欲地使用面向对象的编程思想操作数据库。
使用传统的 JDBC 开发小型应用系统,并不会有什么麻烦,但是对于大型应用系统的开发,使用 JDBC 就会显得力不从心。
例如对几十、几百张包含几十个字段的表进行插入操作时,编写的 SQL 语句不但很长,而且繁琐,容易出错;在读取数据时,需要编写多条语句从结果集中取出各个字段的信息,工作量非常大。
为了提高数据访问层的编程效率,Gavin King 开发了一个当今最流行的 ORM(即 Object-Relational Mapping 对象关系映射)框架—— Hibernate 框架。
重点:
ORM 就是利用描述对象和关系型数据库之间的映射信息,自动将 Java 应用程序中的对象持久化到关系型数据库的表中。通过操作 Java 对象,就可以完成对数据库表的操作。可以把 ORM 理解为关系型数据和对象之间的一个纽带,开发人员只需要关注纽带一端映射的对象即可。
Hibernate目录结构和基础JAR包介绍
目前企业主流使用的 Hibernate 版本以 Hibernate 3.x 版本为主,这里以 Hibernate 3.6.10 版本为例。从官方网址 http://sourceforge.net/projects/hibernate/files/hibernate3/ 中下载对应的版本。Hibernate 3.6.10 版本的下载过程,如图 1 所示。
在图 2 中有两个压缩包链接,其中 hibernate-distribution-3.6.10.Final-dist.zip 是 Windows 下的版本,Final 表示版本号为正式版。hibernate-distribution-3.6.10.Final-dist.tar.gz 是 Linux 下的版本,读者可以根据自己的环境需求下载指定版本的 Hibernate,本教程下载的是 Windows 版本的 ZIP 压缩包。


从表 2 中可以看出,Hibernate 3 所依赖的 JAR 包共有 10 个。其中 hibernate-jpa-2.0-api-1.0.1.Final.jar 是 JPA 接口的开发包,它位于 Hibernate 的 lib 子目录的 jpa 文件夹中。由于 Hibernate 并没有提供对日志的实现,所以需要 slf4j 和 log4j 开发包整合 Hibernate 的日志系统到 log4j。
Hibernate 的环境搭建非常简单,将表 2 中的所有 JAR 包复制到项目的 WEB-INF/lib 目录下即可。需要注意的是,Hibernate 框架要想与数据库建立连接,使用时还需要导入相关数据库的驱动 JAR 包。
====官网下载很慢。
===========================================================================
==================================================================================
1)创建项目并导入 JAR 包
在 MyEclipse 中创建一个名称为 hibernateDemo01 的 Web 项目,将 Hibernate 所需 JAR 包和 MySQL 的驱动包(mysql-connector-java-5.0.8-bin.jar)复制到项目的 WEB-INF/lib 目录中,并将所有 JAR 添加到类路径下。添加 JAR 包后的项目结构如图 1 所示。
2)创建数据库
在 MySQL 中创建一个名称为 hibernate 的数据库,然后在该数据库中创建一个 user 表,创建数据库和表的 SQL 语句如下所示:
CREATE DATABASE hibernate;
USE hibernate;
create table user(
id int(32) primary key auto_increment,
name varchar(20),
age int(4),
gender varchar(4)
);
3)编写实体类(持久化类)
持久化类是应用程序中的业务实体类,符合基本的 JavaBean 编码规范。Hibernate 操作的持久化类基本上都是普通的 Java 对象(Plain Ordinary Java Object,POJO),这些普通 Java 对象中包含的是与数据库表相对应的各个属性,并且这些属性可以通过 getter 和 setter 方法访问。
- public class User {
- private Integer id; // 唯一标识id
- private String name; // 姓名
- private Integer age; // 年龄
- private String gender; // 性别
- public Integer getId() {
- return id;.....}
- 通常持久化类的编写应该遵循一些规则,具体如下。
- 提供一个无参数的 public 访问控制符的构造器。
- 持久化类中所有属性使用 private 修饰。
- 所有属性提供 public 修饰的 setter 和 getter 方法。
- 提供一个标识属性 OID,映射数据表主键字段,例如 User 表的 id 属性。
- 标识属性应尽量使用基本数据类型的包装类型,目的是为了与数据库表的字段默认值 null 一致。
- 不要用 final 修饰持久化类,否则无法生成代理对象。
4)编写映射文件
实体类 User 目前还不具备持久化操作的能力,为了使该类具备这种能力,需要通知 Hibernate 框架将 User 实体类映射到数据库的某一张表中,以及类中的哪个属性对应数据表的哪个字段,这些都需要在映射文件中配置。
在 com.mengma.domain 包中,创建一个名称为 User.hbm.xml 的映射文件,编辑后如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- name代表的是类名,table代表的是表名 -->
<class name="com.mengma.domain.User" table="user">
<!-- name代表的是User类中的id属性,column代表的是user表中的主键id -->
<id name="id" column="id">
<!-- 主键生成策略 -->
<generator class="native" />
</id>
<!-- 其他属性使用property标签映射 -->
<property name="name" column="name" type="java.lang.String" />
<property name="age" type="integer" column="age" />
<property name="gender" type="java.lang.String" column="gender" />
</class>
</hibernate-mapping>
5)编写核心配置文件 hibernate.cfg.xml
在 src 目录下创建一个名称为 hibernate.cfg.xml 的文件,如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 指定方言 -->
<property name="dialect">
org.hibernate.dialect.MySQL5Dialect
</property>
<!-- 链接数据库url -->
<property name="connection.url">
<![CDATA[jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=utf-8]]>
</property>
<!-- 连接数据库的用户名 -->
<property name="connection.username">
root
</property>
<!-- 数据库的密码 -->
<property name="connection.password">
123456
</property>
<!-- 数据库驱动 -->
<property name="connection.driver_class">
com.mysql.jdbc.Driver
</property>
<!-- 显示sql语句 -->
<property name="show_sql">
true
</property>
<!-- 格式化sql语句 -->
<property name="format_sql">true</property>
<!-- 映射文件配置 -->
<mapping resource="com/mengma/domain/User.hbm.xml" />
</session-factory>
</hibernate-configuration>
上述代码中,设置了数据库连接的相关配置和其他的一些常用属性,其中 <mapping> 元素用于将对象的映射信息加入到 Hibernate 的核心配置文件中。
=============================================
========================================
Hibernate实现增删改查功能
添加数据
在项目的 src 目录下创建一个名称为 com.mengma.test 的包,在该包下创建一个名称为UserTest的测试类。
// 添加操作
@Test
public void testInsert() {
// 1.创建Configuration对象并加载hibernate.cfg.xml配置文件
Configuration config = new Configuration().configure();
// 2.获取SessionFactory
SessionFactory sessionFactory = config.buildSessionFactory();
// 3.得到一个Session
Session session = sessionFactory.openSession();
// 4.开启事务
Transaction transaction = session.beginTransaction();
// 5.执行持久化操作
User user = new User();
user.setName("zhangsan");
user.setAge(21);
user.setGender("男");
// 将对象保存到表中
session.save(user);
// 6.提交事务
transaction.commit();
// 7.关闭资源
session.close();
sessionFactory.close();
}
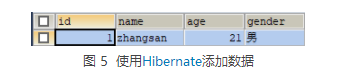
修改数据
// 修改操作
@Test
public void testUpdate() {
// 1.创建Configuration对象并加载hibernate.cfg.xml配置文件
Configuration config = new Configuration().configure();
// 2.获取SessionFactory
SessionFactory sessionFactory = config.buildSessionFactory();
// 3.得到一个Session
Session session = sessionFactory.openSession();
// 4.开启事务
Transaction transaction = session.beginTransaction();
// 5.执行持久化操作
User user = new User();
user.setId(1);
user.setName("zhangsan");
user.setAge(19);
user.setGender("男");
// 更新数据
session.update(user);
// 6.提交事务
transaction.commit();
// 7.关闭资源
session.close();
sessionFactory.close();
}

查询数据
// 查询操作
@Test
public void findByIdTest() {
// 1.创建Configuration对象并加载hibernate.cfg.xml配置文件
Configuration config = new Configuration().configure();
// 2.获取SessionFactory
SessionFactory sessionFactory = config.buildSessionFactory();
// 3.得到一个Session
Session session = sessionFactory.openSession();
// 4.开启事务
Transaction transaction = session.beginTransaction();
// 5.执行持久化操作
User user = (User) session.get(User.class, 1);
System.out.println(user.getId() + "" + user.getName() + ""
+ user.getAge() + "" + user.getGender());
// 6.提交事务
transaction.commit();
// 7.关闭资源
session.close();
sessionFactory.close();
}

删除数据
// 删除操作
@Test
public void deleteByIdTest() {
// 1.创建Configuration对象并加载hibernate.cfg.xml配置文件
Configuration config = new Configuration().configure();
// 2.获取SessionFactory
SessionFactory sessionFactory = config.buildSessionFactory();
// 3.得到一个Session
Session session = sessionFactory.openSession();
// 4.开启事务
Transaction transaction = session.beginTransaction();
// 5.执行持久化操作
User user = (User) session.get(User.class, 1);
session.delete(user);
// 6.提交事务
transaction.commit();
// 7.关闭资源
session.close();
sessionFactory.close();
}
======================================================
============================================================
Hibernate的运行流程详解
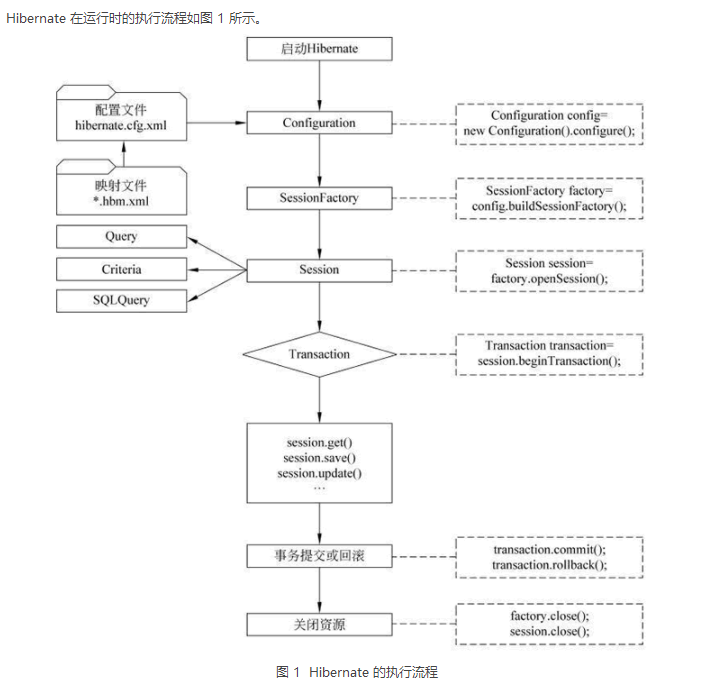
1)创建 Configuration 实例,加载 Hibernate 核心配置文件和映射文件信息到 Configuration 对象中。
2)创建 SessionFactory 实例。通过 Configuration 对象读取到的配置文件信息创建 SessionFactory 对象,该对象中保存了当前数据库的配置信息和所有映射关系等信息。
3)创建 Session 实例,建立数据库连接。Session 主要负责执行持久化对象的增、删、改、查操作,创建一个 Session 就相当于创建一个新的数据库连接。
4)创建 Transaction 实例,开启一个事务。Transaction 用于事务管理,一个 Transaction 对象对应的事务可以包含多个操作。在使用 Hibernate 进行增、删、改操作时,必须先创建 Transaction 对象。需要注意的是,Hibernate 的事务默认是关闭的,需要手动开启事务和关闭事务。
5)利用 Session 接口通过的各种方法进行持久化操作。
6)提交事务,对实体对象持久化操作后,必须提交事务。
7)关闭 Session 与 SessionFactory,断开与数据库的连接
Hibernate映射文件*.hbm.xml的元素及属性详解
- <?xml version="1.0" encoding="UTF-8"?>
- <!--映射文件的dtd约束信息-->
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <!-- name代表的是完整类名(包含的类名),table代表的是表名 -->
- <class name="className" table="tableName">
- <!-- name代表的是className类中的唯一标识属性,column代表的是tableName表中的主键id -->
- <id name="id" column="id">
- <!-- 主键生成策略 -->
- <generator class="native" />
- </id>
- <!-- name表示className的普通属性 column表示tableName表的普通字段 type 表示字段类型-->
- <property name="attrName" column="fieIdName" type="string" />
- </class>
- </hibernate-mapping>



Hibernate 的主键生成策略之前,需要先了解两个概念:自然主键和代理主键。
把具有业务含义的字段作为主键,称为自然主键-----如主键
把不具备业务含义的字段作为主键,称为代理主键。该字段一般取名为 ID


Hibernate hibernate.cfg.xml文件和C3P0连接池的配置
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-configuration PUBLIC
- "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
- <hibernate-configuration>
- <session-factory>
- <!-- 指定方言 -->
- <property name="dialect">
- org.hibernate.dialect.MySQL5Dialect
- </property>
- <!-- 链接数据库url -->
- <property name="connection.url">
- <![CDATA[jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=utf-8]]>
- </property>
- <!-- 连接数据库的用户名 -->
- <property name="connection.username">
- root
- </property>
- <!-- 数据库的密码 -->
- <property name="connection.password">
- 1128
- </property>
- <!-- 数据库驱动 -->
- <property name="connection.driver_class">
- com.mysql.jdbc.Driver
- </property>
- <!-- 其他配置 -->
- <!-- 显示sql语句 -->
- <property name="show_sql">
- true
- </property>
- <!-- 格式化sql语句 -->
- <property name="format_sql">true</property>
- <!-- 映射文件配置 -->
- <mapping resource="com/mengma/domain/User.hbm.xml" />
- </session-factory>
- </hibernate-configuration>

首先,导入 C3P0 的 JAR 包(c3p0-0.9.1.jar)。此 JAR 包可以在已经下载的 hibernate 包的 lib 文件夹下的子目录 optional 中找到。
然后,在 hibernate.cfg.xml 中添加 C3P0 的配置信息,其添加代码如下所示。
- <!-- C3P0连接池设定 -->
- <!-- 使用 C3P0连接池配置连接池提供的供应商 -->
- <property name="connection.provider_class">
- org.hibernate.connection.c3p0ConnectionProvider
- </property>
- <!--在连接池中可用的数据库连接的最少数目 -->
- <property name="c3p0.min_size">5 </property>
- <!--在连接池中所有数据库连接的最大数目 -->
- <property name="c3p0.max_sizen">20 </property>
- <!--设定数据库连接的过期时间,以ms为单位,如果连接池中的某个数据库连接空闲状态的时间 超过timeout时间,则会从连接池中清除 -->
- <property name="c3p0.timeout">120 </property>
- <!--每3000s检查所有连接池中的空闲连接以s为单位 -->
- <property name="c3p0.idle_test_period">3000 </property>
Configuration、SessionFactory、Session、Transaction、Query和Criteria:Hibernate核心接口
Configuration:主要用于启动、加载和管理 Hibernate 的配置文件信息
Configuration config = new Configuration().configure("文件的位置");//不加值默认在src下
SessionFactory:负责读取并解析映射文件,以及建立 Session 对象
SessionFactory sessionFactory = config.buildSessionFactory();
Session session = sessionFactory.openSession();
SessionFactory 具有以下特点。
- 它是线程安全的,它的同一个实例能够供多个线程共享。
- 它是重量级的,不能随意创建和销毁它的实例。
由于 SessionFactory 是一个重量级的对象,占用的内存空间较大,所以通常情况下,一个应用程序只需要一个 SessionFactory 实例,只有应用中存在多个数据源时,才为每个数据源建立一个 SessionFactory 实例。为此,在实际开发时,通常会抽取出一个工具类提供 Session 对象。下面就介绍一个简单的抽取方式,如下所示。
- public class HibernateUtils {
- // 声明一个私有的静态final类型的Configuration对象
- private static final Configuration config;
- // 声明一个私有的静态的final类型的SessionFactory对象
- private static final SessionFactory factory;
- // 通过静态代码块构建SessionFactory
- static {
- config = new Configuration().configure();
- factory = config.buildSessionFactory();
- }
- // 提供一个公有的静态方法供外部获取,并返回一个session对象
- public static Session getSession() {
- return factory.openSession();
- }
Session:是 Java 应用程序和 Hibernate 进行交互时所使用的主要接口,是持久化操作的核心 API
- //采用openSession方法创建Session//需要调用 close() 方法进行手动关闭
- Session session = sessionFactory.openSession();
- //采用getCurrentSession()方法创建Session// Session 实例会被绑定到当前线程中,它在提交或回滚操作时会自动关闭。
- Session session = sessionFactory.getCurrentSession();

需要注意的是,Session 是线程不安全的,当多个并发线程同时操作一个 Session 实例时,就可能导致 Session 数据存取的混乱(当方法内部定义和使用 Session 时,不会出现线程问题)。因此设计软件架构时,应避免多个线程共享一个 Session 实例。
Transaction
Transaction 接口主要是用于管理事务,它是 Hibernate 的数据库事务接口,且对底层的事务接口进行了封装。
Transaction 接口的实例对象是通过 Session 对象开启的,其开启方式如下所示:
Transaction transaction = session.beginTransaction();
在 Transaction 接口中,提供了事务管理的常用方法,具体如下。
- commit() 方法:提交相关联的 session 实例。
- rollback() 方法:撤销事务操作。
- wasCommitted() 方法:检查事务是否提交。
- try{
- transaction = session.beginTransaction(); //开启事务
- session.save(user); //执行操作
- transaction.commit(); //提交事务
- }catch(Exception e) {
- transaction.rollback(); //回滚事务
- }finally{
- session.close(); //关闭资源
- }
Query接口:是 Hibernate 的查询接口,主要用于执行 Hibernate 的查询操作。Query 中包装了一个 HQL
- 获得 Hibernate Session 对象。
- 编写 HQL 语句。
- 调用 session.createQuery 创建查询对象。
- 如果 HQL 语句包含参数,则调用 Query 的 setXxx 设置参数。
- 调用 Query 对象的 list() 或 uniqueResult() 方法执行查询。
例:1)向 user 表中插入 4 条数据,插入数据的 SQL 语句如下所示:
- public class QueryTest {
- @Test
- public void testFindAll() {
- Configuration config = new Configuration().configure();
- SessionFactory sessionFactory = config.buildSessionFactory();
- // 1.得到一个Session
- Session session = sessionFactory.openSession();
- Transaction transaction = session.beginTransaction();
- // 2.编写 HQL,其中的User代表的是类
- String hql = "from User";
- // 3.创建Query查询对象
- Query query = session.createQuery(hql);
- // 4.使用query.list()方法查询数据,并放入list集合
- List<User> list = query.list();
- for (User u : list) {
- System.out.println(u);
- }
- transaction.commit();
- session.close();
- sessionFactory.close();
- }
- }


Criteria
是 Hibernate 提供的一个面向对象的查询条件接口,通过它完全不需要考虑数据库底层如何实现,以及 SQL 语句如何编写。Criteria 查询又称为 QBC 查询(Query By Criteria),是 Hibernate 的另一种对象检索方式。
在 Hibernate 中 Criterion 对象的创建通常是通过 Restrictions 工厂类完成的

1)获得 Hibernate 的 Session 对象。
2)通过 Session 获得 Criteria 对象。
3)使用 Restrictions 的静态方法创建 Criterion 条件对象。Restrictions 类中提供了一系列用于设定查询条件的静态方法,这些静态方法都返回 Criterion 实例,每个 Criterion 实例代表一个查询条件。
4)向 Criteria 对象中添加 Criterion 查询条件。Criteria 的 add() 方法用于加入查询条件。
5)执行 Criteria 的 list() 或 uniqueResult() 获得结果。
- public class CriteriaTest {
- @Test
- public void testQBC() {
- Configuration config = new Configuration().configure();
- SessionFactory sessionFactory = config.buildSessionFactory();
- // 1.得到一个Session
- Session session = sessionFactory.openSession();
- Transaction transaction = session.beginTransaction();
- // 2.通过session获得Criteria对象
- Criteria criteria = session.createCriteria(User.class);
- // 3.使用Restrictions的eq方法设定查询条件为name="zhangsan"
- // 4.向Criteria对象中添加查询条件
- criteria.add(Restrictions.eq("name", "zhangsan"));
- // 5.执行Criterita的list()方法获得结果
- List<User> list = criteria.list();
- for (User u : list) {
- System.out.println(u);
- }
- transaction.commit();
- session.close();
- sessionFactory.close();
- }
- }
Hibernate持久化对象的状态及状态转换
1)瞬时态(transient)
2)持久态(persistent)
3)脱管态(detached)
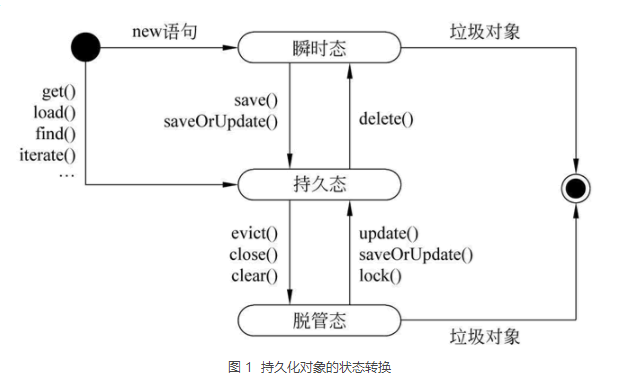
从图 1 中可以看出,当一个对象通过 new 关键字创建后,该对象处于瞬时态;当对瞬时态对象执行 Session 的 save() 或 saveOrUpdate() 方法后,该对象将被放入 Session 的一级缓存中,此时该对象处于持久态。
当对持久态对象执行 evict()、close() 或 clear() 操作后,对象会进入脱管态。
当直接执行 Session 的 get()、load()、find() 或 iterate() 等方法从数据库中查询出对象时,查询到的对象也会处于持久态。
当对数据库中的纪录进行 update()、saveOrUpdate() 以及 lock() 等操作后,此时脱管态的对象就过渡到持久态;由于瞬时态和脱管态的对象不在 session 的管理范围内,所以会在一段时间后被 JVM 回收。
Hibernate持久化对象的状态转换实例
1. 创建项目并导入 JAR 包
2. 创建实体类
- public class Goods {
- private Integer id; // 标识id
- private String name; // 商品名称
- private Double price; // 商品价格
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public Double getPrice() {
- return price;
- }
- public void setPrice(Double price) {
- this.price = price;
- }
- // 重写toString()方法
- public String toString() {
- return "Goods[id=" + id + ",name=" + name + ",price=" + price + "]";
- }
- }
上述代码中,定义了三个属性,分别为 id、name 和 price,并提供了各属性的 getter 和 setter 方法以及 toString() 方法
3. 创建映射文件
在 com.mengma.domain 包下创建一个名为 Goods.hbm.xml 的映射文件,编辑后如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.domain.Goods" table="goods">
- <id name="id" column="id" type="integer">
- <generator class="native" />
- </id>
- <property name="name" column="name" />
- <property name="price" column="price" />
- </class>
- </hibernate-mapping>
4. 创建配置文件
在 src 目录下创建 Hibernate 的核心配置文件 hibernate.cfg.xml,编辑后如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-configuration PUBLIC
- "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
- <hibernate-configuration>
- <session-factory>
- <!-- 指定方言 -->
- <property name="dialect">
- org.hibernate.dialect.MySQL5Dialect
- </property>
- <!-- 链接数据库url -->
- <property name="connection.url">
- <![CDATA[jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=utf-8]]>
- </property>
- <!-- 连接数据库的用户名 -->
- <property name="connection.username">
- root
- </property>
- <!-- 数据库的密码 -->
- <property name="connection.password">
- 1128
- </property>
- <!-- 数据库驱动 -->
- <property name="connection.driver_class">
- com.mysql.jdbc.Driver
- </property>
- <!-- 显示sql语句 -->
- <property name="show_sql">
- true
- </property>
- <!-- 格式化sql语句 -->
- <property name="format_sql">true</property>
- <!-- 自动建表 -->
- <property name="hbm2ddl.auto">update</property>
- <!-- 映射文件配置 -->
- <mapping resource="com/mengma/domain/Goods.hbm.xml" />
- </session-factory>
- </hibernate-configuration>
上述代码中,除了配置数据库的基本信息、显示 SQL 语句、格式化 SQL 语句以及导入关联映射文件信息以外,还增加了一个自动建表的配置信息,该配置会自动检测数据库中是否存在对应的表,如果不存在,则会自动在数据库中创建数据表,反之则不创建。
5. 创建工具类
HibernateUtils 的类,该类用于获取 Session 实例对象,其实现代码请参见Hibernate核心接口
6. 创建测试类
- public class GoodsTest {
- // 演示持久化对象的三种状态
- @Test
- public void test1() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- Goods goods = new Goods();
- goods.setName("铅笔");
- goods.setPrice(0.5);
- session.save(goods);
- session.getTransaction().commit();
- session.close();
- System.out.println(goods);
- }
执行 save() 方法后,Goods 对象已经处于 Session 的管理范围了,并且有了自己的 OID,此时的 Goods 对象已转换为持久态。当执行 commit() 方法并关闭 Session 后,Goods 对象就已不在 Session 的管理范围,此时 Goods 对象从持久态转换为托管态。

从图 3 中可以看出,执行完 save() 方法后,Good 对象的 id 属性已被赋值,该值就是 Goods 对象的持久化标识 OID,这说明持久化对象在事务提交前就已经变成了持久态,也说明了瞬时态对象和持久态对象的区别就是,持久态对象与 Session 进行了关联并且 OID 有值。
当执行完 close() 方法后,Goods 对象与 Session 不再存在关联关系,此时的 Goods 对象会由持久态对象转换为脱管态,但通过控制台的输出内容可以发现 Goods 对象的 OID 属性依然是存在的,这说明脱管态对象与持久态对象的区别就是脱管状态对象没有了 Session 关联。
==================================================
========================================
Hibernate一级缓存详解
Hibernate 中的缓存分为一级缓存和二级缓存,这两个级别的缓存都位于持久化层,并且存储的都是数据库数据的备份。
一级缓存其实就是 Session 缓存。Session 缓存是一块内存空间,用于存储与管理 Java 对象。
Hibernate 的一级缓存具有如下特点。
1)当应用程序调用 Session 接口的 save()、update()、saveOrUpdate() 时,如果 Session 缓存中没有相应的对象,则 Hibernate 就会自动把从数据库中查询到的相应对象信息加入到一级缓存中。
2)当调用 Session 接口的 load()、get() 方法,以及 Query 接口的 list()、iterator() 方法时,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果缓存中没有要查询的对象,则再去数据库中查询对应对象,并添加到一级缓存中。
3)当调用 Session 的 close() 方法时,Session 缓存会被清空。
4)Session 能够在某些情况下,按照缓存中对象的变化,执行相关的 SQL 语句同步更新数据库,这一过程被称为刷出缓存(flush)。
在默认情况下,Session 在如下几种情况中会刷出缓存。
1)当应用程序调用 Transaction 的 commit() 方法时,该方法先刷出缓存(调用 session.flush() 方法),然后再向数据库提交事务(调用 commit() 方法)。
2)当应用程序执行一些查询操作时,如果缓存中持久化对象的属性已经发生了变化,会先刷出缓存,以保证查询结果能够反映持久化对象的最新状态。
3)调用 Session 的 flush() 方法。
以上就是 Hibernate 一级缓存的刷出情况。对于刚接触 Hibernate 框架的读者来说并不是很容易理解,为了帮助读者更好地理解 Session 的一级缓存,下面通过具体案例演示一级缓存的使用。

- // 证明一级缓存的存在
- @Test
- public void test2() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- // 获取goods1对象时,由于一级缓存中没有数据,所以会发送SQL语句,查询数据库中的内容
- Goods goods1 = (Goods) session.get(Goods.class, 1);
- System.out.println(goods1);
- // 获取goods2对象时,不会发出SQL语句,会从Session缓存中获取数据
- Goods goods2 = (Goods) session.get(Goods.class, 1);
- System.out.println(goods2);
- session.getTransaction().commit();
- session.close();
- }
为了验证上面的描述,接下来在 7 行设置断点,

Hibernate快照技术详解
Hibernate 向一级缓存中存入数据的同时,还会复制一份数据存入 Hibernate 快照中。当调用 commit() 方法时,会清理一级缓存中的数据操作),同时会检测一级缓存中的数据和快照区的数据是否相同。如果不同,则会执行 update() 方法,将一级缓存的数据同步到数据库中,并更新快照区;反之,则不会执行 update() 方法。
- // hibernate快照
- @Test
- public void test3() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- Goods goods = new Goods();
- goods.setName("钢笔");
- goods.setPrice(5.0);
- session.save(goods); // 向一级缓存中存入session对象
- goods.setPrice(4.5); // 提交价格
- session.getTransaction().commit(); //提交事务
- session.close(); //关闭资源
- }

Hibernate一级缓存常用操作:刷出、清除和刷新
在 Hibernate 中,一级缓存有三个常见的操作,分别为刷出、清除和刷新操作,下面结合本章前面的案例演示这三种常见的操作。
1. 刷出(flush)
- // 刷出
- @Test
- public void test4() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- Goods goods = (Goods) session.get(Goods.class, 2);
- goods.setPrice(5.5);
- session.flush(); // 执行刷出操作,此时会发送update语句
- session.getTransaction().commit();
- session.close();
- }
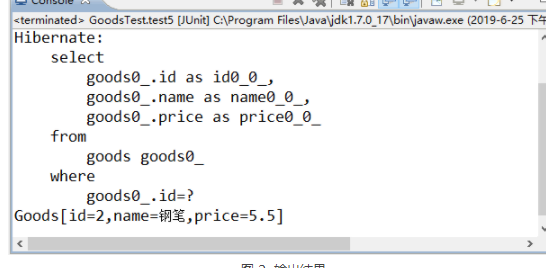
在 flush() 方法处设置断点,利用 Debug 模式运行程序。当程序停止在断点处时,控制台中会显示查询 Goods 对象时所发出的 select 语句。当程序向下执行完 session.flush() 语句时,控制台会输出 update 语句,如图 1 所示。

2. 清除(clear)
程序在调用 Session 的 clear() 方法时,可以执行清除缓存数据的操作。
- // 清除
- @Test
- public void test5() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- Goods goods = (Goods) session.get(Goods.class, 2);
- System.out.println(goods);
- goods.setPrice(6.5);
- session.clear(); // 清空一级缓存
- session.getTransaction().commit();
- session.close();
- }
只输出了 select 语句,而没有输出 update 语句。同时,查看数据库时,会发现数据库中的数据也没有发生变化。这是因为在执行 clear() 方法时,清空了一级缓存中的数据,所以 Goods 对象的修改操作并没有生效。
需要注意的是,如果将上述方法中的 session.clear() 方法更改为 session.evict(goods)方法,也可以实现同样的效果。这两个方法的区别是:clear() 方法是清空一级缓存中所有的数据,而 evict() 方法是清除一级缓存中的某一个对象。
3. 刷新(refresh)
程序在调用 Session 的 refresh() 方法时,会重新查询数据库,并更新 Hibernate 快照区和一级缓存中的数据。
- // 刷新
- @Test
- public void test6() {
- Session session = HibernateUtils.getSession(); // 得到session对象
- session.beginTransaction();
- Goods goods = (Goods) session.get(Goods.class, 2);
- goods.setPrice(7.5);
- session.refresh(goods); // 查询数据库,恢复快照和一级缓存中的数据
- session.getTransaction().commit();
- session.close();
- }
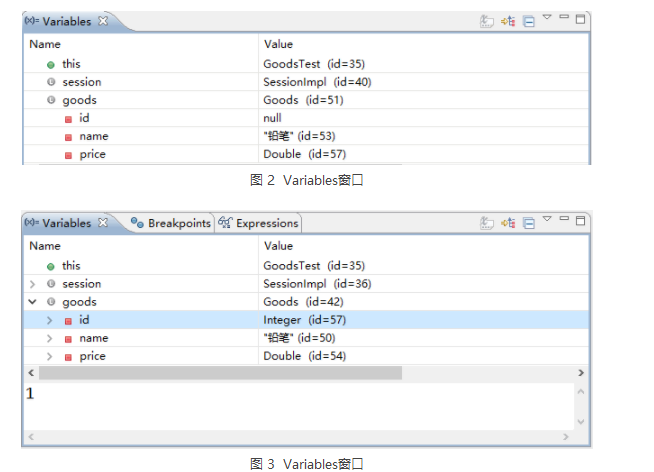
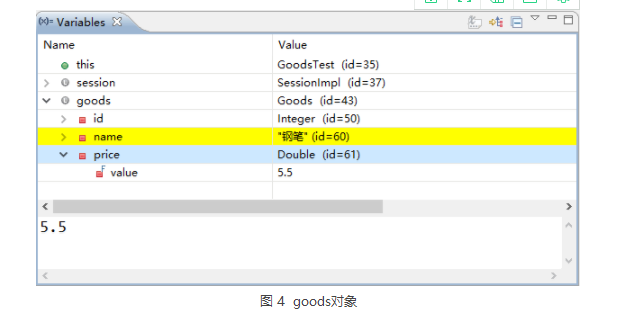
在 refresh() 方法处设置断点,利用 Debug 模式调试程序,观察 Variables 窗口中 goods 对象的 price 属性值,如图 3 所示

从图 3 的显示结果中可以看出,此时的 price 属性值为 7.5,按 F6 键继续向下执行,当执行完 refresh() 方法后,Variables 窗口中 goods 对象的 price 属性值如图 4 所示。
Hibernate映射关系:一对一、一对多和多对多
将对象的关联关系与数据库表的外键关联进行映射。
这三种关联关系的具体说明如下。
- 一对一:在任意一方引入对方主键作为外键。
- 一对多:在“多”的一方,添加“一”的一方的主键作为外键。
- 多对多:产生中间关系表,引入两张表的主键作为外键,两个主键成为联合主键。
,这里用 Set 集合的目的是避免数据的重复。

Hibernate一对多映射关系详解(附带实例)

1. 创建项目导入 JAR 包
在 MyEclipse 中创建一个名为 hibernateDemo03 的 Web 项目,并将 Hibernate 所必需的 JAR 包添加到 WEB-INF/lib 目录中,并发布到类路径下。
2. 创建实体类
1)创建班级实体类。
在项目的 src 目录下创建一个名为 com.mengma.onetomany 的包,在该包下创建一个 Grade 类,编辑后如下所示。
- public class Grade {
- private Integer id;
- private String name; // 班级名称
- private Set<Student> students = new HashSet<Student>();
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public Set<Student> getStudents() {
- return students;
- }
- public void setStudents(Set<Student> students) {
- this.students = students;
- }
- }
以上代码中,定义了三个属性,分别是 id、name 和 students,并提供了各属性的 getter 和 setter 方法。其中是 students 是一个集合类型对象,用于存储一个班级的学生。
2)创建学生实体类。
在 com.mengma.onetomany 包下创建一个名为 Student 的类,编辑后如下所示。
- package com.mengma.onetomany;
- public class Student {
- private Integer id;
- private String name; // 学生名称
- private Grade grade; // 学生从属于某个班级
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public Grade getGrade() {
- return grade;
- }
- public void setGrade(Grade grade) {
- this.grade = grade;
- }
- }
以上代码中,同样也定义了三个属性,分别是 id、name 和 grade,并提供了各属性的 getter 和 setter 方法。其中 grade 是一个 Grade 类型的对象,用于表示该学生从属于某一个班级。
3. 创建映射文件
1)创建班级类的映射文件。
在 com.mengma.onetomany 包下创建一个名为 Grade.hbm.xml 的映射文件,如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.onetomany.Grade" table="grade">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <property name="name" column="name" length="40" />
- <!-- 一对多的关系使用set集合映射 -->
- <set name="students">
- <!-- 确定关联的外键列 -->
- <key column="gid" />
- <!-- 映射到关联类属性 -->
- <one-to-many class="com.mengma.onetomany.Student" />
- </set>
- </class>
- </hibernate-mapping>
- 上述代码中,使用 <set> 标签描述被映射类中的 Set 集合,其中 <key> 标签的 column 属性用于确定关联的外键列,<one-to-many> 标签用于描述持久化类的一对多关联,其中 class 属性表示映射的关联类。
-
2)创建学生类的映射文件。
在 com.mengma.onetomany 包下创建一个名为 Student.hbm.xml 的映射文件,如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.onetomany.Student" table="student">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <property name="name" column="name" length="40" />
- <!-- 多对一关系映射 -->
- <many-to-one name="grade" class="com.mengma.onetomany.Grade"></many-to-one>
- </class>
- </hibernate-mapping>
上述代码中,<many-to-one> 标签定义了三个属性,分别是 name、class 和 column 属性。其中,name 属性表示 Student 类中的 grade 属性名称,class 属性表示指定映射的类,column 属性表示表中的外键类名。需要注意的是,该 column 属性与 Grade.hbm.xml 映射文件的 <key> 标签的 column 属性要保持一致。
4. 创建配置文件和工具类
在 src 目录下创建一个名为 hibernate.cfg.xml 的配置文件,在该文件行中配置数据库基本信息和其他配置信息后,将 Grade.hbm.xml 和 Student.hbm.xml 映射文件添加到配置文件中,具体如下所示:
<mapping resource="com/mengma/onetomany/Grade.hbm.xml" />
<mapping resource="com/mengma/onetomany/Student.hbm.xml" />
在 src 目录下创建一个名为 com.mengma.utils 的包,在包中创建工具类文件 HibernateUtils.java(可参见本书第23章中的文件23-5)。
5. 创建测试类
在 com.mengma.onetomany 包下创建一个名为 OneToManyTest 的类,编辑后如下所示。
- // 添加数据
- @Test
- public void test1() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- // 创建一个班级
- Grade g = new Grade();
- // 创建两个学生对象
- g.setName("一班");
- Student s1 = new Student();
- s1.setName("张三");
- Student s2 = new Student();
- s2.setName("李四");
- // 描述关系---学生属于某个班级
- s1.setGrade(g);
- s1.setGrade(g);
- // 描述关系---班级里有多个学生
- g.getStudents().add(s1);
- g.getStudents().add(s2);
- // 先存班级再存学生
- session.save(g);
- session.save(s1);
- session.save(s2);
- session.getTransaction().commit();
- session.close();
- }
上述代码中,首先创建了一个班级对象和两个学生对象,然后分别描述了两个学生与班级之间的关系,又描述了一个班级与两个学生之间的关系,这就是一对多的双向关联关系。
6. 运行项目并查看结果
在 Hibernate 配置文件中添加自动建表信息后,在运行程序时,程序会自动创建两张表,并且插入数据。使用 JUnit 测试运行 test1() 方法后,控制台显示结果如图 2 所示。


从图 3 查询结果中可以看出,grade 表和 student 表都已经成功创建,并插入了相应的数据。
在 Hibernate 中,像班级和学生这种关联关系,使用双向关联会执行两次 SQL 语句,这样会导致程序执行效率降低。
如果将 OneToManyTest 中的第 23 行和第 24 行代码删除,并将 grade 表和 student 表中的数据从数据库中删除,那么重新运行 test1() 方法后,控制台的输出结果如图 4 所示。

从图 4 的显示结果中可以看出,控制台只显示出了三条 insert 语句,而没有显示 update 语句。
此时再次查询数据表中的数据,其查询结果将与图 3 中的显示结果相同。由于删除了两行描述班级有多个学生的代码,实现了班级对学生的一对多单向关联,所以程序只执行了一次 SQL 语句,但达到了同样的效果。在实际开发中,像班级和学生这种关联关系,使用单向关联描述即可。
Hibernate多对多映射关系详解

在图 1 中,各个表的字段意思如下:
- students 表为学生表,id 为学生表的主键,sname 表示学生名称。
- course 表为课程表,id 为课程表的主键,cname 表示课程名称。
- s_c 表为中间表,cid 和 sid 表示外键。
1. 创建实体类
1)创建学生实体类。
在 src 目录下创建一个名为 com.mengma.manytomany 的包,在该包下创建一个 Students 类,编辑后如下所示。
- public class Students {
- private Integer id; // 学生id
- private String sname; // 学生姓名
- // 一门课程都可以被多个学生学习
- private Set<Course> courses = new HashSet<Course>();
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getSname() {
- return sname;
- }
- public void setSname(String sname) {
- this.sname = sname;
- }
- public Set<Course> getCourses() {
- return courses;
- }
- public void setCourses(Set<Course> courses) {
- this.courses = courses;
- }
- }
上述代码中,courses 是一个集合类型,用于表示一个学生可以学习多门课程。
2)创建课程实体类。
在 com.mengma.manytomany 包下创建一个名为 Course 的类,编辑后如下所示。
- public class Course {
- private Integer id; // 课程id
- private String cname; // 课程名称
- // 一个学生可以学习多门课程
- private Set<Students> students = new HashSet<Students>();
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getCname() {
- return cname;
- }
- public void setCname(String cname) {
- this.cname = cname;
- }
- public Set<Students> getStudents() {
- return students;
- }
- public void setStudents(Set<Students> students) {
- this.students = students;
- }
- }
上述代码中,students 是一个集合类型,用于表示一门课程可以被多个学生学习。
2. 创建映射文件
1)创建学生实体类映射文件。
在 com.mengma.manytomany 包下创建一个名为 Students.hbm.xml 的映射文件,编辑后如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.onetomany.Students" table="students">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <property name="sname" column="sname" length="40" />
- <set name="courses" table="s_c">
- <key column="sid" />
- <many-to-many class="com.mengma.manytomany.Course"
- column="cid" />
- </set>
- </class>
- </hibernate-mapping>
上述代码中,使用 <set> 标签描述被映射类中的 Set 集合对象,与一对多配置方式不同的是,在 <set> 标签中多了一个 table 属性,该属性表示中间表的名称。
在 <set> 标签内,<key> 标签的 column 属性用于描述 students 表在中间表中的外键名称,<many-to-many> 标签用于表示两个持久化类多对多的关联关系,其中 column 属性用于描述 course 表在中间表中的外键名称。
2)创建课程实体类映射文件。
在 com.mengma.manytomany 包下创建一个名为 Course.hbm.xml 的映射文件,如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.onetomany.Course" table="sourse">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <property name="cname" column="cname" length="40" />
- <set name="students" table="s_c">
- <key column="cid" />
- <many-to-many class="com.mengma.manytomany.Students"
- column="sid" />
- </set>
- </class>
- </hibernate-mapping>
上述代码中可以看出,Course.hbm.xml 与 Students.hbm.xml 的配置以及属性所表示的含义相同,可参考理解。
3. 添加映射信息
在 hibernate.cfg.xml 配置文件中添加 Students.hbm.xml 和 Course.hbm.xml 映射文件信息,具体如下所示:
<mapping resource="com/mengma/manytomany/Students.hbm.xml" />
<mapping resource="com/mengma/manytomany/Course.hbm.xml" />
4. 创建测试类
在 com.mengma.manytomany 包下创建一个名为 ManyToManyTest 的类,编辑后如下所示。
- public class ManyToManyTest {
- // 添加数据
- @Test
- public void test1() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- // 创建两个学生
- Students s1 = new Students();
- s1.setSname("张三");
- Students s2 = new Students();
- s2.setSname("李四");
- // 创建两门科目
- Course c1 = new Course();
- c1.setCname("Java基础入门");
- Course c2 = new Course();
- c2.setCname("MySQL基础入门");
- // 学生关联科目
- s1.getCourses().add(c1);
- s2.getCourses().add(c1);
- s1.getCourses().add(c2);
- s2.getCourses().add(c2);
- // 存储
- session.save(c1);
- session.save(c2);
- session.save(s1);
- session.save(s2);
- session.getTransaction().commit();
- session.close();
- }
- }
上述代码中,首先创建两个学生对象和两门课程对象,然后用学生对课程进行关联,这就是多对多的单向关联。对于多对多的双向关联教程后面会结合反转的知识进行讲解,这里不再过多赘述。
5. 运行程序并查看结果
使用 JUnit 测试运行 test1() 方法,运行成功后,分别查询 students 表、course 表和 s_c 表,查询结果如图 2 所示。

图 2 查询结果
从图 2 的查询结果中可以看出,students 表和 course 表的主键分别作为了中间表的外键。由于是两个学生分别学习两门课程,所以可以看到 s_c 表总共有四条记录。
Hibernate级联(cascade)与反转(inverse)详解
在 Hibernate 的关联关系中,可以使用单向关联关系,也可以使用双向关联关系,在双向关联关系中,Hibernate 会同时控制双方的关系,这样在程序操作时,很容易出现重复操作的问题。
反转操作
在映射文件的 <set> 标签中,有一个 inverse(反转)属性,它的作用是控制关联的双方由哪一方管理关联关系。
inverse 属性值是 boolean 类型的:
- 当取值为 false(默认值)时,表示由当前这一方管理双方的关联关系,如果双方 inverse 属性都为 false 时,双方将同时管理关联关系。
- 取值为 true 时,表示当前一方放弃控制权,由对方管理双方的关联关系。
- 通常情况下,在一对多关联关系中,会将“一”的一方的 inverse 属性取值为 true,即由“多”的一方维护关联关系,否则会产生多余的 SQL 语句;而在多对多的关联关系中,任意设置一方的 inverse 属性为 true 即可。
通过《Hibernate多对多映射关系详解》教程的学习,读者已经了解了多对多关联的单向关联,接下来结合反转操作演示多对多双向关联的情况。
1. 修改 ManyToManyTest 类
在《Hibernate多对多映射关系详解》教程的 ManyToManyTest 的第 29~30 行代码之间添加课程对学生的关联,具体代码如下所示:
- //课堂关联学生
- c1.getStudents().add(s1);
- c1.getStudents().add(s2);
- c2.getStudents().add(s1);
- c2.getStudents().add(s2);
使用 JUnit 测试运行 test1() 方法,其进度条显示为红色,表明运行结果没有通过,此时 JUnit 控制台中的报错信息如图 1 所示。

从图 1 的报错信息中可以看出,相同的主键值出现了重复写入,这是因为在双向关联中会产生一张中间表,由于关联双方都向中间表插入了数据,因此出现了重复写入的情况。
通常情况下,这种问题有两种解决方案:第一种是进行单向关联,第二种是在一方的映射文件中,将 <set> 标签的 inverse 属性设置为 true。
2. 修改映射文件 Course.hbm.xml
在 Course.hbm.xml 映射文件的 <set> 标签中,添加 inverse 属性,并将其属性值设置为 true,代码如下所示:
- <set name="students" table="s_c" inverse="true">
- <key column="cid" />
- <many-to-many class="com.mengma.manytomany.Students"
- column="sid" />
- </set>
3. 运行程序并查看结果
使用 JUnit 再次运行 test1() 方法,执行成功后,分别查看 students 表、course 表和 s_c 表,查询结果如图 2 所示。
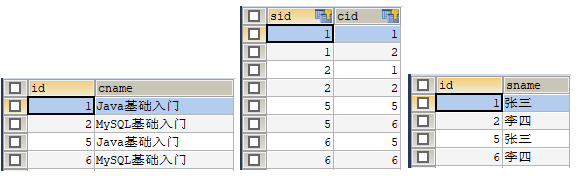
图 2 查询结果
从图 2 的查询结果中可以看出,数据已经成功添加到三张表中。
需要注意的是,inverse 只对 <set>、<one-to-many> 和 <many-to-many> 标签有效,对 <many-to-one> 和 <one-to-one> 标签无效。
级联操作
级联操作是指当主控方执行任意操作时,其关联对象也执行相同的操作,保持同步。在映射文件的 <set> 标签中有个 cascade 属性,该属性用于设置是否对关联对象采用级联操作,其常用属性如表 1 所示。

1. 一对多的级联添加操作
在《Hibernate一对多映射关系详解》教程中,通过班级和学生的关系讲解了一对多的关联关系映射,其案例代码实现了添加班级和学生的操作,下面演示一下仅添加班级的情况。
1)在 OneToManyTest 类中添加一个名为 test2() 的方法,其代码如下所示:
- // 一对多级联添加操作
- @Test
- public void test2() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- // 创建一个班级
- Grade g = new Grade();
- g.setName("二班");
- // 创建一个学生
- Student student = new Student();
- student.setName("王五");
- // 班级关联学生
- session.save(g);
- session.getTransaction().commit();
- session.close();
- }
2)在映射文件 Grade.hbm.xml 中,将 <many-to-one> 标签的 cascade 的属性值设置为 save-update,具体如下所示:
- <set name="students" cascade="save-update">
- <key column="gid" />
- <one-to-many class="com.mengma.onetomany.Student" />
- </set>
在上述配置代码中,cascade="save-update" 的含义是在添加 grade 表数据的同时,也向 student 表中添加数据。
3)使用 JUnit 测试运行 test2() 方法,执行成功后,分别查询 grade 表和 student 表,查询结果如图 3 所示。
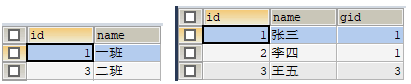
2. 一对多的级联删除操作
在班级和学生的关联关系中,如果使用级联删除了班级,那么该班级对应的学生也会被删除。接下来演示在不使用级联删除操作的情况下,删除班级信息时学生信息的变化情况。在 OneToMany 类中添加一个名为 test3() 的方法,其代码如下所示:- // 不使用级联的删除操作
- @Test
- public void test3() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Grade grade = (Grade) session.get(Grade.class, 1); // 查询id=1的班级对象
- session.delete(grade); // 删除班级
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,首先查询了 id 为 1 的班级对象,然后调用 delete() 方法删除了该班级对象。
使用 JUnit 测试运行 test3() 方法,执行成功后,分别查询 grade 表和 student 表,查询结果如图 4 所示。
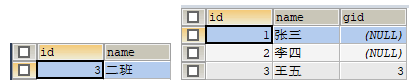
图 4 查询结果
从图 4 的查询结果中可以看出,id 为 1 的班级已经成功被删除了,但是该班级的学生依然存在于 student 表中,只是 student 表中对应的外键被设为了 null 值。
这是因为班级被删除后,与其关联的 student 表中的外键值没有了。在删除 grade 表中数据之前,student 表先执行了 update 操作,将其表中的班级外键值设为了 null,然后才删除 grade 表中的班级。
如果希望在删除 grade 表中数据的同时,也删除与其关联的 student 表中的数据,那么就可以使用级联删除操作。设置级联删除操作非常简单,只需要在 Grade.hbm.xml 映射文件的 <set> 标签中,将 cascade 属性值设置为 delete 即可。具体配置如下所示:
- <set name="students" cascade="delete">
- <key column="gid" />
- <one-to-many class="com.mengma.onetomany.Student" />
- </set>
在 OneToMany 类中添加一个名为 test4() 的方法,其代码如下所示:
- // 一对多级联的删除操作
- @Test
- public void test4() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Grade grade = (Grade) session.get(Grade.class, 3); // 查询id=3的班级对象
- session.delete(grade); //删除班级
- session.getTransaction().commit();
- session.close();
- }
使用 JUnit 测试运行 test4() 方法,运行成功后,分别查询 grade 表和 student 表,查询结果如图 5 所示。

图 5 查询结果
从图 5 的查询结果中可以看出,grade 表中 id 为 3 的班级和关联的一个学生都已经被成功删除了。
3. 孤儿删除操作
在班级和学生的关系中,如果没有设置级联删除,则删除班级后,该班级所关联学生的外键会被设为 null,这时可以将这些学生比喻为孤儿,孤儿删除就是删除与某个班级解除关系的学生。
下面通过示例演示孤儿删除操作。首先执行一次 OneToManyTest 类中的 test1() 方法,向 grade 表和 student 表插入数据,运行成功后,分别查询 grade 表和 student 表,查询结果如图 6 所示。
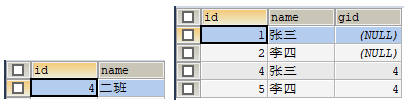
图 6 查询结果
从图 6 的查询结果中可以看出,grade 表和 student 表中的数据已经成功插入。下面在 OneToManyTest 方法中添加一个名为 test5() 的方法,具体代码如下所示:
- // 孤儿删除
- @Test
- public void test5() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Grade grade = (Grade) session.get(Grade.class, 4); // 查询id=4的班级对象
- Student student = (Student) session.get(Student.class, 5); // 查询id=5的学生对象
- grade.getStudents().remove(student); // 解除关系
- session.delete(grade);
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,先查询了 id 为 4 的班级对象和 id 为 5 的学生对象,然后解除了它们之间的关系。
在 Grade.hbm.xml 映射文件中,将 cascade 属性设置为 delete-orphan,具体配置如下所示:
- <set name="students" cascade="delete-orphan">
- <key column="gid" />
- <one-to-many class="com.mengma.onetomany.Student" />
- </set>
使用 JUnit 测试运行 test5() 方法,运行成功后,分别查询 grade 表和 student 表,查询结果如图 7 所示。

图 7 查询结果
从图 7 的查询结果中可以看出,id 为 4 的班级和关联的 id 为 4 的学生数据还在,但 id 为 5 的学生数据已经被成功删除了,这表明孤儿删除的功能已经成功实现。
4. 多对多的级联添加操作
在前面小节中,我们已经学习了一对多的级联添加操作,下面通过具体示例演示多对多的级联添加操作。
1)在 ManyToManyTest 类中添加一个名为 test2() 的方法,其具体代码如下所示:
- // 多对多级联添加操作
- @Test
- public void test2() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- // 创建课程对象
- Course c = new Course();
- c.setCname("JavaWeb程序开发");
- // 创建学生对象
- Students s = new Students();
- s.setSname("王五");
- // 学生关联课程
- s.getCourses().add(c);
- // 存储
- session.save(s);
- session.getTransaction().commit();
- session.close();
2)在 Students.hbm.xml 映射文件中,将 cascade 属性设置为 save-update,具体配置如下所示:
- set name="courses" table="s_c" cascade="save-update">
- <key column="sid" />
- <many-to-many class="com.mengma.manytomany.Course"
- column="cid" />
- </set>
3)使用 JUnit 测试运行 test2() 方法,运行成功后,分别查询 student 表、course 表和 s_c 表,查询结果如图 8 所示。
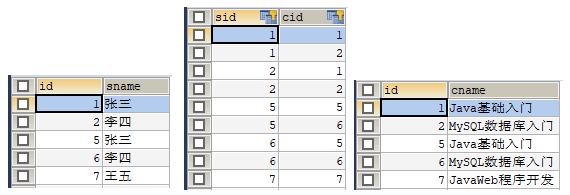
图 8 查询结果
从图 8 的查询结果中可以看出,多对多级联添加操作已经成功实现。
Hibernate的5种检索方式
Hibernate 的检索方式主要有五种,包括导航对象图检索方式、OID 检索方式、HQL 检索方式、QBC 检索方式和本地 SQL 检索方式,接下来针对 Hibernate 五种检索方式进行详细讲解。
导航对象图检索方式
导航对象图检索方式是根据已经加载的对象,导航到其他对象。它利用类与类之间的关系检索对象。
例如,对于已经加载的学生对象,就可以利用学生对象自动导航找到该学生所对应的班级对象,但前提是需要在对象关系映射文件上配置两者多对一的关系。其检索示例代码如下所示:
Student student = (Student)session.get(Student.class,1);
Grade grade = student.getGrade();
OlD检索方式
OID 检索方式是指按照对象的 OID 检索对象。它使用 Session 对象的 get() 和 load() 方法加载某一条记录所对应的对象,其使用的前提是需要事先知道 OID 的值。该检索方式的示例代码如下所示:
Grade grade1 = (Grade)session.get(Grade.class,1);
Grade grade2 = (Grade)session.get(Grade.class,1);
HQL检索方式
HQL(Hibernate Query Language)是 Hibernate 查询语言的简称,它是一种面向对象的查询语言,与 SQL 查询语言有些类似,但它使用的是类、对象和属性的概念,而没有表和字段的概念。
HQL 查询与 SQL 查询相比,具有以下优点。
- 直接针对实体类和属性进行查询,不用再编写繁琐的 SQL 语句。
- 查询结果直接保存在 List 集合中,不用再次封装。
- 针对不同的数据库会自动生成不同的 SQL 语句。
在 Hibernate 提供的几种检索方式中,HQL 是官方推荐的查询语言,也是使用最频繁的一种检索方式,其具有以下主要功能。
- 在查询语句中设定各种查询条件。
- 支持投影查询,即仅检索出对象的部分属性。
- 提供内置聚集函数,如 sum()、min() 和 max()。
- 支持分组查询,允许使用 group by 和 having 关键字。
- 支持分页查询。
- 支持子查询,即嵌套查询。
- 支持动态绑定参数。
HQL 的语法格式与 SQL 非常相似,并且在 Hibernate 中专门为 HQL 提供了一个 Query 查询接口执行各种复杂的查询语句。HQL 的完整语法格式如下所示:
[select/update/delete...]from...[where...][group by...][having...][order by...][asc/desc]
从上述语法格式中可以看出,HQL 查询与 SQL 查询非常类似。通常情况下,当检索表中的所有数据时,查询语句中可以省略 select 关键字,其示例如下所示:
String hql="from User";
需要注意的是,上述语句中 User 表示类名,而不是表名,因此需要区分大小写,而 from 关键字不区分大小写。
QBC检索方式
QBC(Query By Criteria)是 Hibernate 提供的另一种检索对象的方式,它主要由 Criteria 接口、Criterion 接口和 Expression 类组成,并且支持在运行时动态生成查询语句。
QBC 查询主要由 Criteria 接口完成,该接口由 Session 对象创建,Criterion 是 Criteria 的查询条件,在 Criteria 中提供了 add(Criterion criterion)方法添加查询条件。
以查询 id 为 1 的 User 对象为例,使用 QBC 检索对象的示例代码如下所示:
- // 创建 criteria 对象
- Criteriacriteria =session.createCriteria(User.class);
- // 设定查询条件
- Criterioncriterion = Restrictions.eq("id",1);
- // 添加查询条件
- criteria.add(criterion);
- // 执行查询,返回查询结果
- List<User>gs = criteria.list ();
本地SQL检索方式
本地 SQL 检索方式就是使用本地数据库的 SQL 查询语句进行查询。在 Hibernate 中,SQL 查询是通过 SQLQuery 接口表示的,该接口是 Query 接口的子接口,因此可以调用 Query 接口的方法。
使用本地 SQL 检索方式检索对象的示例代码,代码如下所示:
SQLQuery sqlQuery = session.createSQLQuery("select * from user");
HQL检索方式
HQL(Hibernate Query Language)是 Hibernate 查询语言的简称,它是一种面向对象的查询语言,与 SQL 查询语言有些类似,但它使用的是类、对象和属性的概念,而没有表和字段的概念。
HQL 查询与 SQL 查询相比,具有以下优点。
- 直接针对实体类和属性进行查询,不用再编写繁琐的 SQL 语句。
- 查询结果直接保存在 List 集合中,不用再次封装。
- 针对不同的数据库会自动生成不同的 SQL 语句。
在 Hibernate 提供的几种检索方式中,HQL 是官方推荐的查询语言,也是使用最频繁的一种检索方式,其具有以下主要功能。
- 在查询语句中设定各种查询条件。
- 支持投影查询,即仅检索出对象的部分属性。
- 提供内置聚集函数,如 sum()、min() 和 max()。
- 支持分组查询,允许使用 group by 和 having 关键字。
- 支持分页查询。
- 支持子查询,即嵌套查询。
- 支持动态绑定参数。
HQL 的语法格式与 SQL 非常相似,并且在 Hibernate 中专门为 HQL 提供了一个 Query 查询接口执行各种复杂的查询语句。HQL 的完整语法格式如下所示:
[select/update/delete...]from...[where...][group by...][having...][order by...][asc/desc]
从上述语法格式中可以看出,HQL 查询与 SQL 查询非常类似。通常情况下,当检索表中的所有数据时,查询语句中可以省略 select 关键字,其示例如下所示:
String hql="from User";
需要注意的是,上述语句中 User 表示类名,而不是表名,因此需要区分大小写,而 from 关键字不区分大小写。
QBC检索方式
QBC(Query By Criteria)是 Hibernate 提供的另一种检索对象的方式,它主要由 Criteria 接口、Criterion 接口和 Expression 类组成,并且支持在运行时动态生成查询语句。
QBC 查询主要由 Criteria 接口完成,该接口由 Session 对象创建,Criterion 是 Criteria 的查询条件,在 Criteria 中提供了 add(Criterion criterion)方法添加查询条件。
以查询 id 为 1 的 User 对象为例,使用 QBC 检索对象的示例代码如下所示:
- // 创建 criteria 对象
- Criteria criteria =session.createCriteria(User.class);
- // 设定查询条件
- Criterion criterion = Restrictions.eq("id",1);
- // 添加查询条件
- criteria.add(criterion);
- // 执行查询,返回查询结果
- List<User> gs = criteria.list ();
本地SQL检索方式
本地 SQL 检索方式就是使用本地数据库的 SQL 查询语句进行查询。在 Hibernate 中,SQL 查询是通过 SQLQuery 接口表示的,该接口是 Query 接口的子接口,因此可以调用 Query 接口的方法。
使用本地 SQL 检索方式检索对象的示例代码,代码如下所示:
SQLQuery sqlQuery = session.createSQLQuery("select * from user");
Hibernate HQL的5种常见检索方式详解
在 Hibernate 核心 API 中,Query 接口是专门用于 HQL 查询的接口。教程《Hibernate核心接口》已经讲解过该接口,并通过案例演示了该接口中 list() 方法的使用。本节将针对 HQL 中其他几种常见的检索方式进行详细讲解。
指定别名
HQL 语句与 SQL 语句类似,也可以使用 as 关键字指定别名。在使用别名时,as 关键字可以省略。下面通过案例演示如何在 HQL 语句中使用别名。
1)在 MyEclipse 中创建一个名为 hibernateDemo04 的 Web 项目,将 Hibernate 所必需的 JAR 包添加到项目的 lib 目录中,并发布到类路径下。
2)参见《第一个Hibernate程序》,分别编写实体类、映射文件和配置文件。参见《Hibernate核心接口》教程,编写 Hibernate 工具类。
3)在 src 目录下创建包 com.mengma.test,在该包下创建一个名为 HQLTest 的类,并在类中添加一个 test1() 方法,如下所示。
- public class HQLTest {
- // 指定别名
- @Test
- public void test1() {
- Session session = HibernateUtils.getSession(); // 得到一个 Session
- session.beginTransaction();
- String hql = "from User as u where u.name='zhangsan '"; // 编写 HQL
- Query query = session.createQuery(hql); // 创建 Query对象
- List<User> list = query.list(); // 执行查询,获得结果
- for (User u : list) {
- System.out.println(u);
- }
- session.getTransaction().commit();
- session.close();
- }
- }
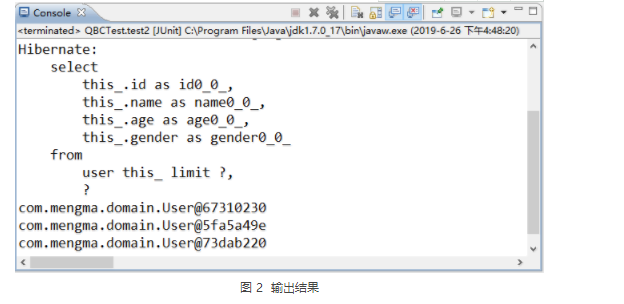
上述代码中,字母 u 表示 User 对象的别名,在 where 条件后面,使用了别名指定查询条件。运行代码之前,首先查询 user 表中的数据,查询结果如图 1 所示。
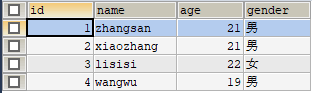
图 1 查询结果
使用 JUnit 测试运行 test1() 方法,运行成功后,控制台的输出结果如图 2 所示。
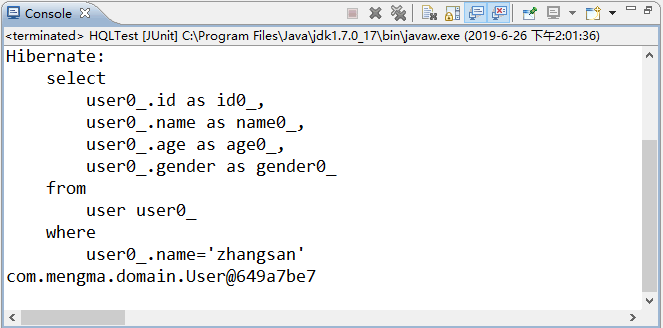
图 2 输出结果
投影查询
本节《指定别名》案例查询出了对象的所有属性,但在实际需求中,可能只需要查询对象的部分属性。此时,可以采用 Hibernate 的投影查询方式查询对象的部分属性。
使用投影查询时的语法结构如下所示:
select 需要查询的属性 from 实体类名
下面通过具体示例演示投影查询。在 HQLTest 类中添加一个名为 test2() 的方法,该方法用于查询用户姓名和年龄,具体代码如下所示:
- // 投影查询
- @Test
- public void test2() {
- Session session = HibernateUtils.getSession(); // 得到一个 Session
- session.beginTransaction();
- String hql = "select u.name, u.age from User as u"; // 编写 HQL
- Query query = session.createQuery(hql); // 创建Query对象
- List<Object[]> list = query.list(); // 执行查询,获得结果
- Iterator<Object[]> iter = list.iterator();
- while (iter.hasNext()) {
- Object[] objs = iter.next();
- System.out.println(objs[0] + " " + objs[1]);
- }
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,使用 select 关键字加上属性 name 和 age 查询数据表中的姓名和年龄信息。当检索对象的部分属性时,Hibernate 返回的 List 中的每一个元素都是一个 Object 数组,而不再是 User 对象。
在 Object 数组中,各个属性是有顺序的。如上述代码中,objs[0] 所对应的就是 name 属性的值,objs[1] 所对应的就是 age 属性的值,这与查询语句中的各个属性的顺序相对应。为了使输出数据整齐明了,在输出语句中使用了水平制表符“ ”。
使用 JUnit 测试运行 test2() 方法,运行成功后,控制台的输出结果如图 3 所示。
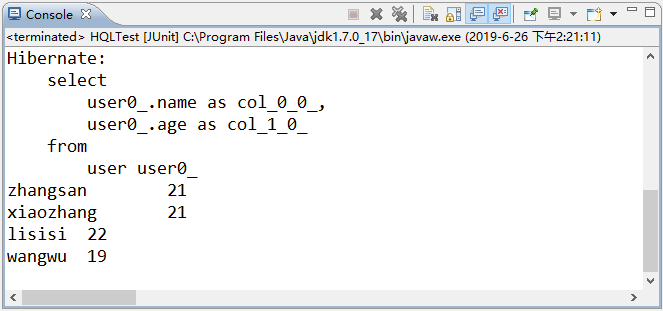
图 3 输出结果
动态实例查询
使用投影查询时,返回的查询结果是一个对象数组。由于在输出数据时还需要处理顺序,因此操作十分不便。为了方便操作,提高检索效率,可将检索出来的数据重新封装到一个实体的实例中,这种方式就是动态实例查询。
下面通过具体示例演示动态实例查询。在 HQLTest 类中添加一个名为 test3() 的方法,同样用于查询用户的姓名和年龄。具体代码如下所示:
- // 动态实例查询
- @Test
- public void test3() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- String hql = "select new User (u.name, u.age) from User as u";
- Query query = session.createQuery(hql);
- List<User> list = query.list();
- for (User u : list) {
- System.out.println(u.getName() + " " + u.getAge());
- }
- session.getTransaction().commit();
- session.close();
- }
从上述代码中可以看出,select 语句后面已经不再是属性,而是一个实体类对象,查询语句会将查询后的结果封装到 User 对象中。需要注意的是,使用此种查询方式,需要在 User 实体类中添加一个有参的构造方法和一个无参的构造方法,具体代码如下所示:
- public User() {
- }
- public User(String name, Integer age) {
- this.name = name;
- this.age = age;
- }
由于需要查询的是 name 和 age,所以需要添加带有 name 和 age 参数的构造方法。又由于在添加此构造方法后,虚拟机将不再默认提供无参的构造方法,所以需要再添加一个无参的构造方法。
使用 JUnit 测试运行 test3() 方法,运行成功后,控制台的输出结果如图 4 所示。
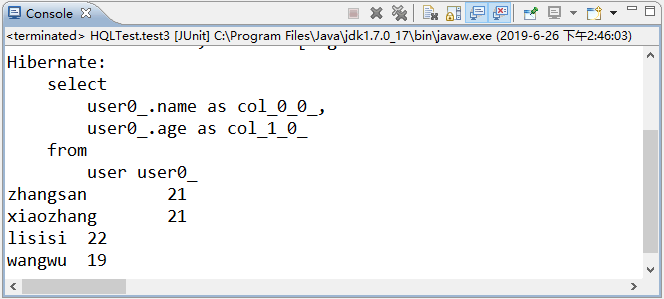
图 4 输出结果
从图 4 的显示结果中可以看出,使用动态实例查询时,查询结果被封装到了 User 对象中,通过 User 对象就可以方便地获取对象的属性了。
条件查询
在程序开发中,通常需要指定条件进行查询。此时,可以使用 HQL 语句提供的 where 子句进行查询,或者使用 like 关键字进行模糊查询。根据提供的参数形式,条件查询分为按参数位置查询和按参数名称查询。下面将对这两种条件查询方式进行详细讲解。
1. 按参数位置查询
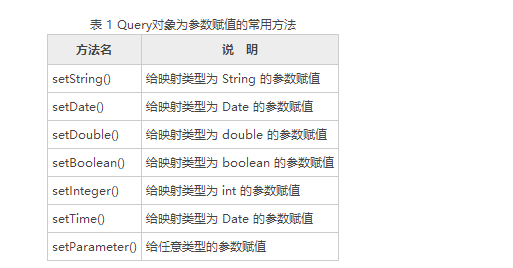
按参数位置查询时,需要在 HQL 语句中使用“?”定义参数的位置,然后通过 Query 对象的 setXxx() 方法为其赋值,这类似于 JDBC 的 PreparedStatement 对象的参数绑定方式。在 Query 对象中,为参数赋值的常用方法如表 1 所示。
表 1 Query对象为参数赋值的常用方法方法名说 明setString()给映射类型为 String 的参数赋值setDate()给映射类型为 Date 的参数赋值setDouble()给映射类型为 double 的参数赋值setBoolean()给映射类型为 boolean 的参数赋值setInteger()给映射类型为 int 的参数赋值setTime()给映射类型为 Date 的参数赋值setParameter()给任意类型的参数赋值
下面通过具体示例演示按参数位置的查询方式。在 HQLTest 类中添加一个名为 test4() 的方法,该方法用于模糊查询姓名中包含“ang”的用户信息,具体代码如下所示:
- // 按参数位置的条件查询
- @Test
- public void test4() {
- Sessionsession = HibernateUtils.getSession(); // 得到一个Session
- session.beginTransaction();
- Stringhql = "from User where name like ?"; // 编写 HQL,使用参数查询
- Queryquery = session.createQuery(hql); // 创建 Query对象
- query.setString(0, "%ang%"); // 为 HQL中的”?”代表的参数设置值
- List<User>list = query.list(); // 执行查询,获得结果
- for (Useru : list) {
- System.out.println(u);
- }
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,首先使用“:id”定义了名称参数,然后使用 Query 对象的 setParameter() 方法为其赋值。最后执行查询获得结果,并输出结果。
使用 JUnit 测试运行 test5() 方法,运行成功后,控制台的输出结果如图 6 所示。
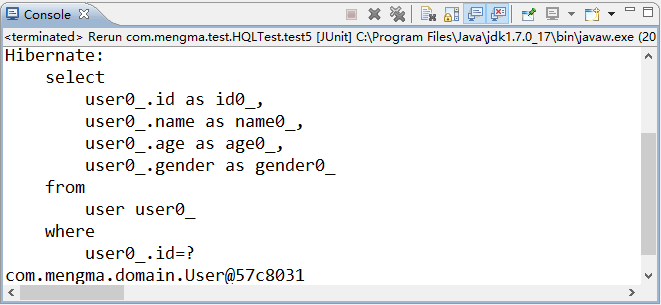
图 6 输出结果
从图 6 的显示结果中可以看出,已经成功输出了 id 为 4 的用户信息。
在 HQL 语句中设定查询条件时,还可以在 where 子句中设定查询运算符。HQL 支持的常用运算符如表 2 所示。

分页查询
在批量查询数据时,在单个页面上会显示所有的查询结果,这在实际开发中是不合理的。通常情况下,开发人员会对查询结果进行分页显示。在 Hibernate 的 Query 接口中,提供了两个用于分页显示查询结果的方法,具体如下。
- setFirstResult(int firstResult):设定从哪个对象开始查询,参数 firstResult 表示这个对象在查询结果中的索引(索引的起始值为 0)。
- setMaxResult(int maxResult):设定一次返回多少个对象。通常与 setFirstResult(int firstResult)方法结合使用,从而限制结果集的范围。默认情况下,返回查询结果中的所有对象。
下面通过具体示例演示如何实现分页查询。在 HQLTest 类中添加一个名为 test6() 的方法,该方法用于实现从查询结果的第 2 条记录开始返回 3 个 User 对象。具体代码如下所示:
- // 分页查询
- @Test
- public void test6() {
- Sessionsession = HibernateUtils.getSession(); // 得到——个 Session
- session.beginTransaction();
- Stringhql = "from User"; // 编写 HQL
- Queryquery = session.createQuery(hql); //创建 Query对象
- query.setFirstResult(1); // 从第 2 条开始查询
- query.setMaxResults(3); // 查询 3 条数据
- List<User>list = query.list();
- for (Useru : list) {
- System.out.println(u);
- }
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,由于 setFirstResult(int firstResult) 方法中的索引初始值为 0,所以从第 2 条开始查询时,参数 firstResult 的值为 1。
使用 JUnit 测试运行 test6() 方法,运行成功后,控制台的输出结果如图 7 所示。
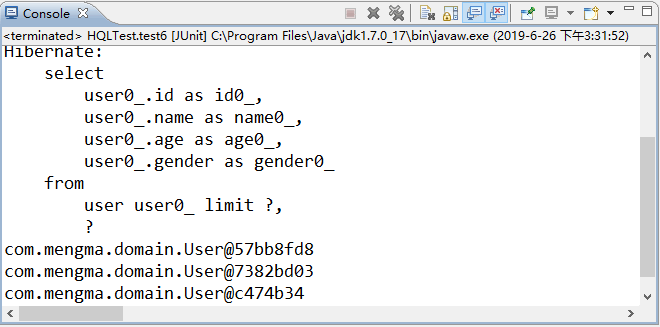
图 7 输出结果
从图 7 的显示结果中可以看出,使用分页查询已经成功输出了 user 表中第 2 条到第 4 条的用户信息。
Hibernate QBC的检索方式:组合查询和分页查询
前面我们已经详细介绍过 Criteria 接口的功能及使用步骤,并通过示例演示了条件查询,接下来将对 QBC 中的其他两种常用的检索方式进行讲解。
组合查询
组合查询是指通过 Restrictions 工具类的相应方法动态地构造查询条件,并将查询条件加入 Criteria 对象,从而实现查询功能。
下面通过具体案例演示如何实现 QBC 检索中的组合查询。在 com.mengma.test 包下,创建一个名为 QBCTest 的类,在该类下添加一个 test1() 方法,该方法用于查询 id 为 3 或者 name 为 wangwu 的用户信息,如下所示。
- package com.mengma.test;
- import java.util.List;
- import org.hibernate.Criteria;
- import org.hibernate.Session;
- import org.hibernate.criterion.Criterion;
- import org.hibernate.criterion.Restrictions;
- import org.junit.Test;
- import com.mengma.domain.HibernateUtils;
- import com.mengma.domain.User;
- public classQBCTest {
- // 组合查询
- @Test
- public void testl() {
- Sessionsession = HibernateUtils.getSession();
- session.beginTransaction();
- Criteriacriteria = session.createCriteria(User.class);
- Criterioncriterion = Restrictions.or(Restrictions.eq("id", 3),
- Restrictions.eq("name", "wangwu")); // 设定查询条件
- criteria.add(criterion); // 添加查询条件
- List<User>list = criteria.list(); // 执行查询,返回查询结果
- for (Useru : list) {
- System.out.println(u);
- }
- session.getTransaction().commit();
- session.close();
- }
- }
上述代码中,使用了 Restrictions 对象编写查询条件,并将查询条件加入到了 Criteria 对象中。使用 JUnit 测试运行 test1() 方法,运行成功后,控制台的输出结果如图 1 所示。
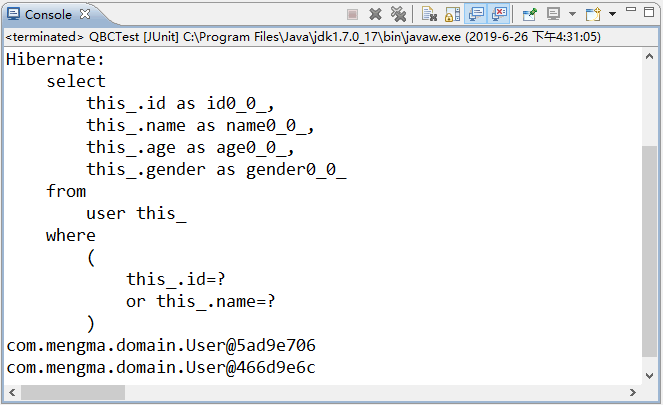
图 1 输出结果
从图 1 的显示结果中可以看出,符合查询条件的记录共有两条。
需要注意的是,QBC 检索是使用 Restrictions 对象编写查询条件的,上述代码中的 Restrictions.or 方法类似于 SQL 语句中的 or 关键字,Restrictions.eq 方法类似于 SQL 语句中的等于。除了这两个方法以外,在 Restrictions 类中还提供了大量的静态方法创建查询条件,如表 1 所示。

分页查询
除了使用 HQL 可以实现分页功能以外,还可以通过 QBC 实现分页。在 Criteria 对象中,通过 setFirstResult(int firstResult) 和 setMaxResult(int maxResult) 两个方法就可以实现分页查询。
下面通过一个具体示例演示如何使用 QBC 检索实现分页。在 QBCTest 类中添加一个名为 test2() 的方法,具体代码如下所示:
- // 分页查询
- @Test
- public void test2() {
- Sessionsession = HibernateUtils.getSession(); // 得到一个Session
- session.beginTransaction();
- Criteriacriteria = session.createCriteria(User.class); // 创建criteria对象
- criteria.setFirstResult(1); // 从第 2 条开始查询
- criteria.setMaxResults(3); // 查询 3 条数据
- List<User>list = criteria.list(); // 执行查询,返回查询结果
- for (Useru : list) {
- System.out.println(u);
- }
- session.getTransaction().commit();
- session.close();
- }
在上述代码中,使用 setFirstResult(int firstResult) 方法指定从哪个对象开始检索,这里是从第 2 条开始的,所以索引值为 1。使用 setMaxResult(int maxResult) 方法指定一次最多检索对象的数量为 3,所以会查询出 3 条数据。
使用 JUnit 测试运行 test2() 方法,运行成功后,控制台的输出结果如图 2 所示。
数据库事务(Transaction)的四大特性和隔离级别
Hibernate 是对 JDBC 的轻量级封装,其主要功能是操作数据库。在操作数据库的过程中,经常会遇到事务处理的问题,而对事务的管理,主要是在 Hibernate 的一级缓存中进行的。
在学习 Hibernate 的事务处理之前,先来学习一下什么是事务。
在数据库操作中,一项事务(Transaction)是由一条或多条操作数据库的 SQL 语句组成的一个不可分割的工作单元,这些操作要么都完成,要么都取消。接下来将围绕事务的特性、并发问题以及隔离级别进行讲解。
事务的特性
事务的定义很严格,它必须同时满足四个特性,即原子性、一致性、隔离性和持久性,也就是人们俗称的 ACID 特性,具体如下。
1)原子性(Atomic)
表示将事务中所进行的操作捆绑成一个不可分割的单元,即对事务所进行的数据修改等操作,要么全部执行,要么全都不执行。
2)一致性(Consistency)
表示事务完成时,必须使所有的数据都保持一致状态。
3)隔离性(Isolation)
指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
4)持久性(Durability)
持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。提交后的其他操作或故障不会对其有任何影响。
事务的隔离级别
在实际应用中,数据库中的数据是要被多个用户共同访问的,在多个用户同时操作相同的数据时,可能就会出现一些事务的并发问题,具体如下。
1)脏读
指一个事务读取到另一个事务未提交的数据。
2)不可重复读
指一个事务对同一行数据重复读取两次,但得到的结果不同。
3)虚读/幻读
指一个事务执行两次查询,但第二次查询的结果包含了第一次查询中未出现的数据。
4)丢失更新
指两个事务同时更新一行数据,后提交(或撤销)的事务将之前事务提交的数据覆盖了。
丢失更新可分为两类,分别是第一类丢失更新和第二类丢失更新。
- 第一类丢失更新是指两个事务同时操作同一个数据时,当第一个事务撤销时,把已经提交的第二个事务的更新数据覆盖了,第二个事务就造成了数据丢失。
- 第二类丢失更新是指当两个事务同时操作同一个数据时,第一个事务将修改结果成功提交后,对第二个事务已经提交的修改结果进行了覆盖,对第二个事务造成了数据丢失。
为了避免上述事务并发问题的出现,在标准的 SQL 规范中定义了四种事务隔离级别,不同的隔离级别对事务的处理有所不同。这四种事务的隔离级别如下。
1)Read Uncommitted(读未提交)
一个事务在执行过程中,既可以访问其他事务未提交的新插入的数据,又可以访问未提交的修改数据。如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,但允许其他事务读此行数据。此隔离级别可防止丢失更新。
2)Read Committed(读已提交)
一个事务在执行过程中,既可以访问其他事务成功提交的新插入的数据,又可以访问成功修改的数据。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。此隔离级别可有效防止脏读。
3)Repeatable Read(可重复读取)
一个事务在执行过程中,可以访问其他事务成功提交的新插入的数据,但不可以访问成功修改的数据。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。此隔离级别可有效防止不可重复读和脏读。
4)Serializable(可串行化)
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,不能并发执行。此隔离级别可有效防止脏读、不可重复读和幻读。但这个级别可能导致大量的超时现象和锁竞争,在实际应用中很少使用。
一般来说,事务的隔离级别越高,越能保证数据库的完整性和一致性,但相对来说,隔离级别越高,对并发性能的影响也越大。因此,通常将数据库的隔离级别设置为 Read Committed,即读已提交数据,它既能防止脏读,又能有较好的并发性能。虽然这种隔离级别会导致不可重复读、幻读和第二类丢失更新这些并发问题,但可通过在应用程序中采用悲观锁和乐观锁加以控制。
Hibernate事务的配置
在 Hibernate 中,可以通过代码操作管理事务,例如 Transaction tx=session.beginTransaction();表示开启一个事务;进行持久化操作后,执行 tx.commit();操作提交事务;如果在操作的过程中出现了异常的情况,则执行 tx.rollback();操作回滚事务。
除了使用代码对事务的开启、提交和回滚进行操作以外,还可以在 Hibernate 的配置文件中对事务进行配置。在配置文件中,可以选择使用本地事务或者全局事务,还可以设置事务的隔离级别。其具体的配置方式如下所示:
<!--使用本地事务-->
<property name= "hibernate.current_session_context_class"> thread</property>
<!--使用全局事务-->
<property name= "hibernate.current_session_context_class">jta</property>
<!--设置事务隔离级别-->
<property name= "hibernate.connection.isolation">2</property>
在上述配置代码中,使用 hibernate.current_session_context_class 参数配置本地事务和全局事务。其中,本地事务是指对一个数据库进行的操作,即只针对一个事务性资源进行操作;而全局事务是指由应用服务器管理的事务,它需要使用 JTA(Java Transaction API),可以用于多个事务性资源(跨多个数据库)。
由于 JTA 的 API 非常笨重,一般只在应用服务器的环境中使用,并且全局事务的使用限制了应用代码的重用性,所以 Hibernate 的事务管理通常会选择使用本地事务。
在上述配置中,还使用了 hibernate.connection.isolation 参数配置事务的隔离级别,并将事务的隔离级别设置为 2,表示读已提交。在 Hibernate 中,使用数字表示不同的隔离级别,它与数据库中的隔离级别相同,具体对应关系如下。
- 1—Read uncommitted 读未提交。
- 2—Read committed 读已提交。
- 4—Repeatable read 可重复读。
- 8—Serializable 串行化。
Hibernate悲观锁(pessimistic lock)实例详解
悲观锁(pessimistic lock)是指在每次操作数据时,总是悲观地认为会有其他事务操作同一数据,因此,在整个数据处理过程中,会把数据处于锁定状态。
悲观锁具有排他性,一般由数据库实现。在锁定时间内,其他事务不能对数据进行存取等操作,这可能导致长时间的等待问题。
1)LockMode.UPGRADE
该模式不管缓存中是否存在对象,总是通过 select 语句到数据库中加载该对象,如果映射文件中设置了版本元素,则执行版本检查,比较缓存中的对象是否与数据库中对象的版本一致,如果数据库系统支持悲观锁(如 MySQL),则执行 select...for update 语句,如果不支持(如 Sybase),则执行普通 select 语句。
2)LockMode.UPGRADE_NOWAIT
该模式与 LockMode.UPGRADE 具有同样的功能,是 Oracle 数据库特有的锁模式,会执行 select...for update nowait 语句。
nowait 表示如果执行 select 语句的事务不成立则获得悲观锁,它不会等待其他事务释放锁,而是立刻抛出锁定异常。
下面通过丢失更新的案例演示悲观锁的使用。
1. 创建项目并引入JAR包
在 MyEclipse 中创建一个名称为 hibernateDemo05 的 Web 项目,将 Hibernate 所必需的 JAR 包添加到 lib 目录中,并发布到类路径下。
2. 创建实体类
在 src 目录下创建一个名为 com.mengma.domain 的包,在该包下创建一个 Person 类,定义 id、name 和 age 三个属性,并实现各属性的 getter 和
setter 方法以及 toString() 方法,如下所示。
- public class Person {
- private Integer id;
- private String name; // 姓名
- private Integer age; // 年龄
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public Integer getAge() {
- return age;
- }
- public void setAge(Integer age) {
- this.age = age;
- }
- }
3. 创建映射文件
在 com.mengma.domain 包中创建一个名为 Person.hbm.xml 的映射文件,将实体类 Person 映射到数据表中,如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.domain.Person" table="person">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <property name="name" column="name" type="string" />
- <property name="age" column="age" type="integer" />
- </class>
- </hibernate-mapping>
4. 创建配置文件
在 src 目录下创建一个名为 hibernate.cfg.xml 的配置文件,该文件中包含数据库的连接信息,以及关联的映射文件信息等,如下所示。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-configuration PUBLIC
- "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
- <hibernate-configuration>
- <session-factory>
- <!-- 指定方言 -->
- <property name="dialect">
- org.hibernate.dialect.MySQL5Dialect
- </property>
- <!-- 链接数据库url -->
- <property name="connection.url">
- <![CDATA[jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=utf-8]]>
- </property>
- <!-- 连接数据库的用户名 -->
- <property name="connection.username">
- root
- </property>
- <!-- 数据库的密码 -->
- <property name="connection.password">
- 1128
- </property>
- <!-- 数据库驱动 -->
- <property name="connection.driver_class">
- com.mysql.jdbc.Driver
- </property>
- <!-- 显示sql语句 -->
- <property name="show_sql">
- true
- </property>
- <!-- 格式化sql语句 -->
- <property name="format_sql">true</property>
- <!-- 映射文件配置 -->
- <mapping resource="com/mengma/domain/Person.hbm.xml" />
- </session-factory>
- </hibernate-configuration>
5. 创建工具类
在 src 目录下创建一个名为 com.mengma.utils 的包,并在该包下创建一个名为 HibernateUtils 的工具类,该工具类的实现代码如下所示。
- public class HibernateUtils {
- // 声明一个私有的静态final类型的Configuration对象
- private static final Configuration config;
- // 声明一个私有的静态的final类型的SessionFactory对象
- private static final SessionFactory factory;
- // 通过静态代码块构建SessionFactory
- static {
- config = new Configuration().configure();
- factory = config.buildSessionFactory();
- }
- // 提供一个公有的静态方法供外部获取,并返回一个session对象
- public static Session getSession() {
- return factory.openSession();
- }
- }
6. 创建测试类
在 src 目录下创建一个名为 com.mengma.test 的包,在该包下创建一个名为 PersonTest 的类。在类中编写一个test1()方法,用于添加一条记录,并检查项目是否可以正常运行。然后再分别编写一个 test2() 方法和 test3() 方法,其中 test2() 方法用于修改 name 属性,test3() 方法用于修改 age 属性。其具体实现代码如下所示。
- public class PersonTest {
- // 添加数据
- @Test
- public void test1() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Person person = new Person();
- person.setName("zhangsan");
- person.setAge(20);
- session.save(person);
- session.getTransaction().commit();
- session.close();
- }
- // 修改name屈性
- @Test
- public void test2() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Person person = (Person) session.get(Person.class, 1);
- person.setName("lisi");
- session.save(person);
- session.getTransaction().commit();
- session.close();
- }
- // 修改age属性
- @Test
- public void test3() {
- Session session = HibernateUtils.getSession();
- session.beginTransaction();
- Person person = (Person) session.get(Person.class, 1);
- person.setAge(25);
- session.save(person);
- session.getTransaction().commit();
- }
- }
7. 运行程序并查看结果
使用 JUnit 测试运行 test1() 方法,运行成功后,控制台的显示结果如图 1 所示。
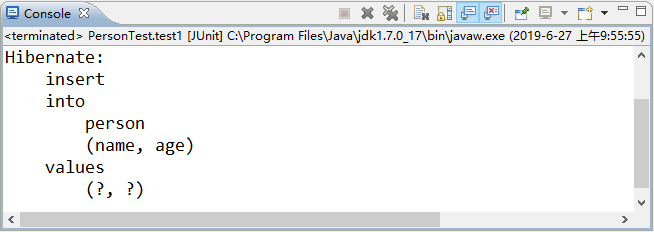
图 1 输出结果
从图 1 中可以看出,使用 Hibernate 已经成功向 person 表中添加数据,说明项目可以正常运行。接下来在 PersonTest 的第 29 行和第 41 行分别设置一个断点,然后采用 Debug 模式运行 test2() 方法,MyEclipse 的显示如图 2 所示。
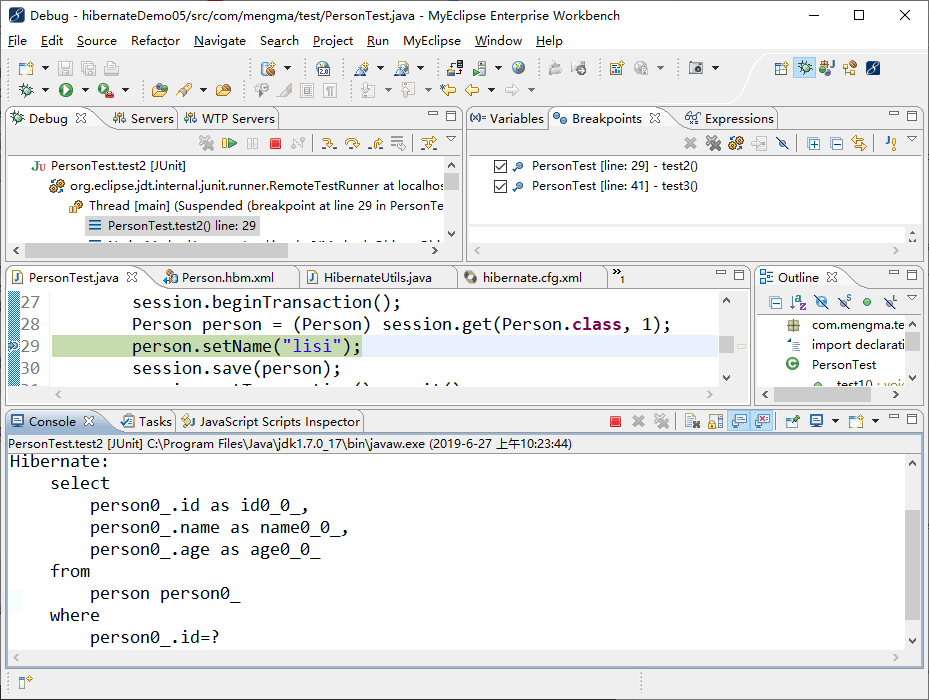
图 2 调试 test2() 方法
从图 2 中可以看出,程序代码已经停在了第 29 行,接下来按 F6 键,使代码依次向下执行,在第 30 行代码处(提交事务前)停止运行。然后以同样的方式运行 test3() 方法,这时代码会停在第 41 行。
由于同时运行了两个方法,但是在 MyEclipse 中,当前窗口只能显示一个运行方法,所以需要手动单击需要显示的方法。此时可以在窗口左上方的 Debug 窗口中看到 test2() 和 test3() 方法,如图 3 所示。
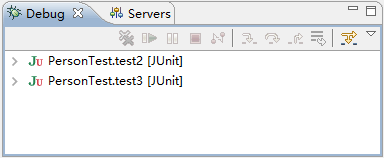
图 3 Debug窗口
单击展开图 3 中的 PersonTest.test3[JUnit] 后,再次单击 Thread[main](Suspended)下面的 PersonTest.test3() 即可进入 test3() 方法的 Debug 调试模式。按 F6 键依次向下执行代码,直到第 38 行代码处停止运行,如图 4 所示。
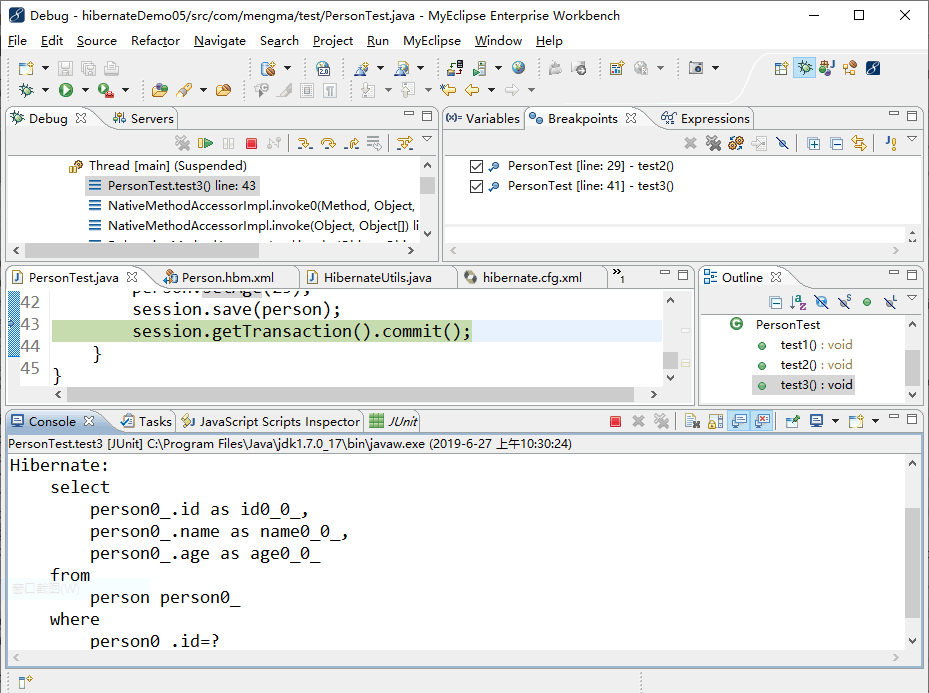
图 4 调试test3()方法
接下来,单击展开图 4 中的 PersonTest.test2[JUnit],回到 test2() 方法,并单击 Debug 窗口上方的 

图 5 查询结果
从图 5 中可以看出,此时 person 表中的数据已经发生了变化。Test2() 提交后,name 字段变为 lisi,但是 test3() 方法提交后,会将 test2() 方法提交的数据覆盖,导致 name 字段变回了原来的 zhangsan,而 age 字段被修改为 25,这就是并发访问数据时的数据丢失。
要解决这一问题,只需在 test2() 和 test3() 方法的 Person person=(Person)session.get(Person.class,1) 中加入 LockMode.UPGRADE 参数即可,具体实现代码如下所示:
Person person=(Person)session.get(Person.class,1,LockMode.UPGRADE);
此时再次通过 Debug 调试运行 test2() 和 test3() 方法,就不会出现数据丢失的情况了,这是因为使用了 Hibernate 的悲观锁模式,当某条数据被锁定时,其他方法无法对此条数据进行操作,直到事务提交后才会被解锁,这时其他方法才可以对这条数据进行操作。
Hibernate乐观锁(optimistic lock)实例详解
相对于悲观锁而言,乐观锁(optimistic lock)通常认为多个事务同时操作同一数据的情况很少发生,因此乐观锁不进行数据库层次上的锁定,而是基于数据版本(Version)标识实现应用程序级别上的锁定机制,这既能保证多个事务的并发操作,又能有效防止第二类丢失更新的发生。
数据版本标识是通过为数据表增加一个 version 字段实现的。增加 version 字段后,程序在读取数据时,会将版本号一同读出,之后在更新此数据时,会将此版本号加一。
在提交数据时,将现有的版本号与数据表对应记录的版本号进行对比,如果提交数据的版本号大于数据表中的版本号,则允许更新数据,否则禁止更新数据。
本节案例在《Hibernate悲观锁》教程的案例的基础上修改,演示基于 Version 乐观锁的使用。具体实现步骤如下。
1. 修改表结构
在 person 表中增加一个 version 字段,并在 version 字段插入一条数据 1,修改表结构和表中数据的 SQL 语句如下所示:
- ALTER TABLE person ADD VERSION INT(10);
- UPDATE person SET version = 1;
- UPDATE person SET age = 20;
修改后,person 表中的数据如图 1 所示。

2. 修改实体类 Person
在 Person 类中添加一个 Integer 类型的 version 属性,并提供相应的 getter 和 setter 方法。3. 修改映射文件 Person.hbm.xml
在 Person.hbm.xml 中添加一个 <version> 标签元素,该元素用于将 Person 类的 version 属性和 person 表的 version 字段进行映射,具体如下所示。- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.mengma.domain.Person" table="person">
- <id name="id" column="id">
- <generator class="native" />
- </id>
- <!-- Person类中的version属性与person表中的version字段进行关联映射 -->
- <property name="version" column="version" type="integer" />
- <property name="name" column="name" type="string" />
- <property name="age" column="age" type="integer" />
- </class>
- </hibernate-mapping>
需要注意的是,<version> 标签必须位于 <id> 标签之后,否则该文件会报错。
4. 运行程序并测试结果
同样在 PersonTest(《Hibernate悲观锁》教程实例中PersonTest.java) 的第 29 行和第 41 行代码处添加断点,使用《Hibernate悲观锁》教程中的 Debug 调试模式运行 test2() 方法和 test3() 方法,执行完 test3() 方法后,控制台的输出结果如图 2 所示。
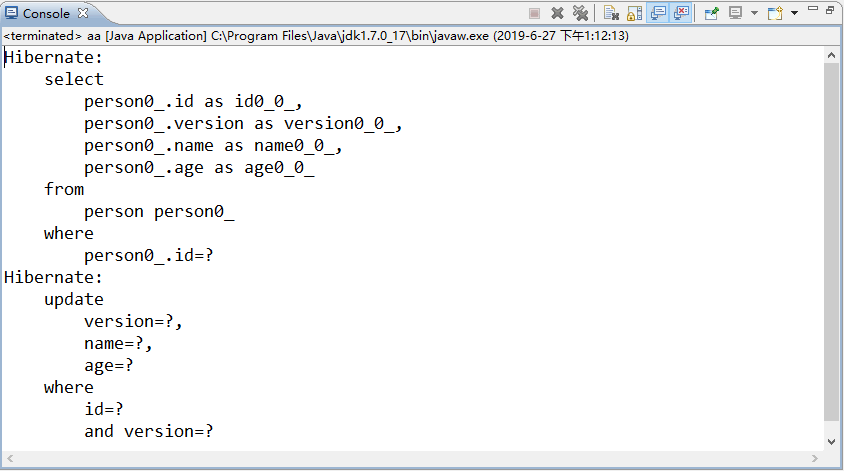
图 2 运行结果
从图 2 的 where 子句中可以看出,Hibernate 的乐观锁是以 id 和 version 决定更新对象的。当 test2() 方法和 test3() 方法执行修改操作未提交时,所查询出的 version 值都是 1,当 test2() 方法先提交后,其数据库中的 version 值就会变为 2。
此时 test3() 方法再执行提交时,会先将之前获取到的 version 值与现状数据库中的 version 值相匹配,由于 id 为 1 的 person 记录的版本号已被 test2() 方法中的事务修改,因此找不到匹配的记录,并且会抛出异常 org.hibernate.StaleObjectStateException。

图 3 修改后的person表数据
从图 3 中可以看到,person 表中的 name 字段已修改为 lisi,并且 version 字段的值变为2,由此可知,test2() 方法已将数据修改成功,这就是 Hibernate 乐观锁的原理和机制。
需要注意的是,在实际应用中应该捕获 org.hibernate.StaleObjectStateException 异常,然后通过自动回滚事务或者通知用户的方式进行相应处理。
Hibernate二级缓存详解
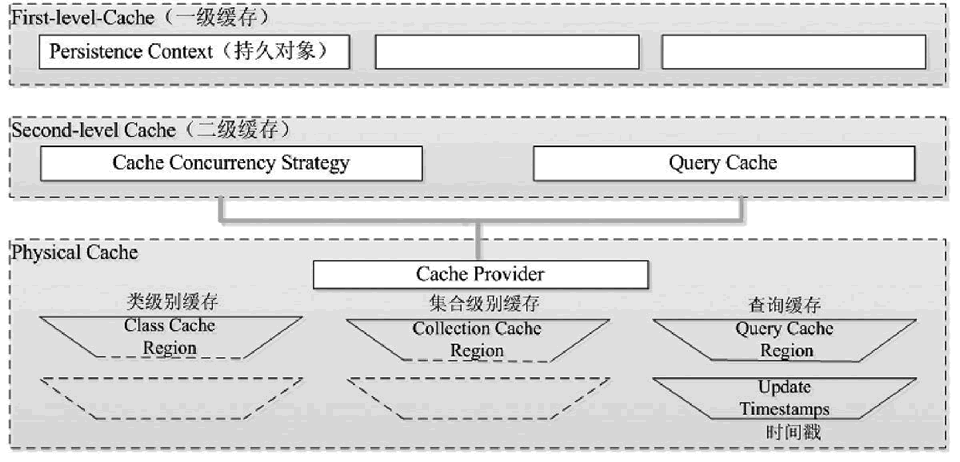
Hibernate 提供了一级缓存和二级缓存两种缓存。一级缓存是 Session 级别的缓存,它是属于事务范围的缓存,这一级别的缓存由 Hibernate 管理,一般情况下无须进行干预。二级缓存是 SessionFactory 级别的缓存,它是属于进程范围的缓存,这一级别的缓存可以进行配置和更改,以及动态地加载和卸载,它是由 SessionFactory 负责管理的。
二级缓存与一级缓存一样,也是根据对象的 ID 加载和缓存数据的。当执行某个查询获得的结果集为实体对象时,Hibernate 就会把获得的实体对象按照 ID 加载到二级缓存中。
在访问指定的对象时,首先从一级缓存中查找,找到就直接使用,找不到则转到二级缓存中查找(必须配置和启用二级缓存)。如果在二级缓存中找到,就直接使用,否则会查询数据库,并将查询结果根据对象的 ID 放到一级缓存和二级缓存中。
SessionFactory 中的缓存可以分为两类,具体如下。
1)内置缓存
Hibernate 自带的只读属性的缓存,不可以被卸载。通常在Hibernate的初始化阶段会把映射的元数据和预定义的SQL语句放到SessionFactory的缓存中,映射元数据是映射文件中数据的复制,而预定义SQL语句是Hibernate根据映射元数据推导出来的。
2)外置缓存(二级缓存)
一个可配置的缓存插件。在默认情况下,SessionFactory 不会启用这个缓存插件,外置缓存中的数据是数据库数据的复制,外置缓存的物理介质可以是内存或硬盘。
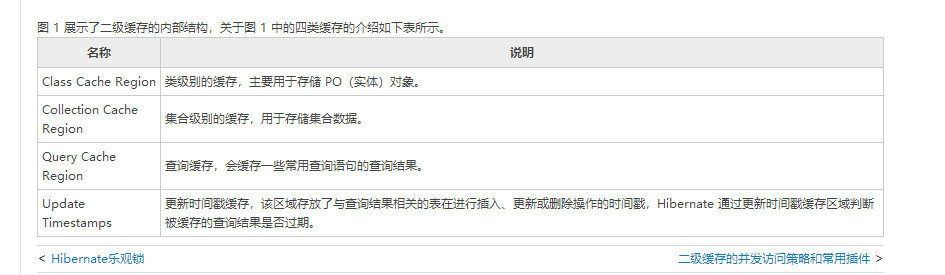
Hibernate 中的二级缓存可以分为四类,分别为类级别的缓存、集合级别的缓存、查询缓存和更新时间戳。二级缓存的内部结构如图 1 所示。
Hibernate二级缓存的并发访问策略和常用插件
二级缓存的并发访问策略
两个并发的事务同时访问持久层缓存中的相同数据时,可能会出现各类并发问题,所以也需要采用必要的隔离措施解决这些问题。
由于在二级缓存中也会出现并发问题,因此在 Hibernate 的二级缓存中,可以设定以下四种类型的并发访问策略,以解决这些问题。每一种访问策略对应一种事务隔离级别,具体介绍如下:
1)只读型(Read-Only)
提供 Serializable 事务隔离级别,对于从来不会被修改的数据,可以采用这种访问策略。
2)读写型(Read-write)
提供 Read Committed 事务隔离级别,对于经常读但是很少被修改的数据,可以采用这种隔离类型,因为它可以防止脏读。
3)非严格读写(Nonstrict-read-write)
不保证缓存与数据库中数据的一致性,提供 Read Uncommitted 事务隔离级别,对于极少被修改,而且允许脏读的数据,可以采用这种策略。
4)事务型(Transactional)
仅在受管理环境下使用,它提供了 Repeatable Read 事务隔离级别。对于经常读但是很少被修改的数据,可以采用这种隔离类型,因为它可以防止脏读和不可重复读。
二级缓存的常用插件
Hibernate 二级缓存需要通过配置二级缓存的插件才可以正常使用,常用的插件有四种,具体如下:
1)EHCache
可作为进程范围内的缓存,存放数据的物理介质可以是内存或硬盘,对 Hibernate 的查询缓存提供了支持。
2)OpenSymphony OSCache
可作为进程范围内的缓存,存放数据的物理介质可以是内存或硬盘;它提供了丰富的缓存数据过期策略,并且对 Hibernate 的查询缓存提供了支持。
3)SwarmCache
可作为集群范围内的缓存,但不支持 Hibernate 的查询缓存。
4)JBossCache
可作为集群范围内的缓存,支持 Hibernate 的查询缓存。
以上的四种缓存插件所支持的并发访问策略如表 1 所示(√代表支持)。
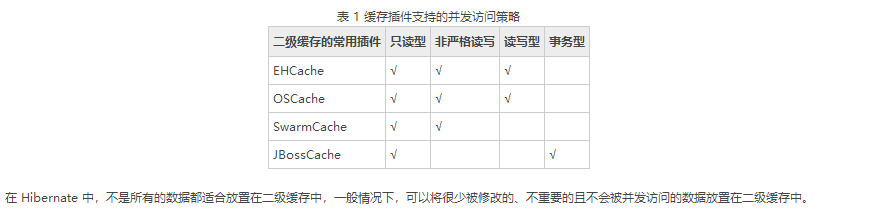
Hibernate整合EHCache插件实现二级缓存
在《Hibernate二级缓存的并发访问策略和常用插件》教程介绍的几种常用的二级缓存插件中,EHCache 缓存插件是理想的进程范围的缓存插件。本小节将以 EHCache 缓存插件为例,介绍二级缓存的配置和使用。本节在教程前几节实例的基础上进行整合,具体步骤如下:
1. 引入 EHCache 相关的 JAR 包
读者可以从官方网址 http://www.ehcache.org/downloads/ 中下载 EHCache 的 JAR 包,成功访问后的页面显示如图 1 所示。
图 1 EHCache的下载
从图 1 中可以看出,目前 EHCache 的最新版本为 ehcache-3.7,本教程使用的是 ehcache-2.10.5,单击图中 Ehcache 2.x 下方的链接,即可下载此版本的 EHCache。下载并解压后,在压缩包文件中找到 ehcache-2.10.5.jar,将其复制到 hibernateDemo05 项目的 lib 目录中,并发布到类路径下即可。
2. 引入 EHCache 的配置文件 ehcache.xml
读者可以直接从 Hibernate 的解压包的 hibernate-distribution-3.6.10.Finalprojectetc 目录中找到 ehcache.xml,找到后,将此文件复制到项目的 src 目录下。ehcache.xml 文件中的主要代码如下所示:
- <?xml version="1.0" encoding="UTF-8"?>
- <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
- updateCheck="false">
- <diskStore path="java.io.tmpdir/Tmp_EhCache" />
- <defaultCache
- eternal="false"
- maxElementsInMemory="10000"
- overflowToDisk="false"
- diskPersistent="false"
- timeToIdleSeconds="1800"
- timeToLiveSeconds="259200"
- memoryStoreEvictionPolicy="LRU" />
- <cache name="cloud_user"
- eternal="false"
- maxElementsInMemory="5000"
- overflowToDisk="false"
- diskPersistent="false"
- timeToIdleSeconds="1800"
- timeToLiveSeconds="1800"
- memoryStoreEvictionPolicy="LRU" />
- </ehcache>

3. 启用二级缓存
在 Hibernate 的核心配置文件中启用二级缓存,并指定哪些实体类需要存储到二级缓存中。其配置代码如下所示:
- <property name="hibernate.cache.use_second_level_cache">true </property>
- <property name="hibernate.cache.provider_class">
- org.hibernate.cache.EhCacheProvider
- </property >
- <mapping resource="com/mengma/domain/Person.hbm.xml"/>
- <class-cache usage="read-write" class="com.mengma.domain.Person"/>
在上述配置代码中,hibernate.cache.use_second_level_cache 用于开启二级缓存,hibernate.cache.provider_class 用于指定二级缓存的供应商。
<class-cache> 标签用于指定将哪些数据存储到二级缓存中,其中 usage 属性表示指定缓存策略。需要注意的是,<class-cache> 标签必须放在 <mapping> 标签的后面。
4. 创建测试类
在 com.mengma.test 包下创建一个名为 SecondEHChcheTest 的测试类,并在类中添加一个 testCache() 方法。在 testCache() 方法中,需要开启两个 Session 对象,然后使用 get() 方法查询四次,通过比较查询结果,观察二级缓存的使用情况。其实现代码如下所示。
- public classSecondEHChcheTest {
- @Test
- public void testCache() {
- Sessionsession1 = HibernateUtils.getSession(); // 开启第一个Session对象
- Transactiontx1 = session1.beginTransaction(); // 开启第一个事务
- Personp1 = (Person) session1.get(Person.class, 1); // 获取p1对象
- Personp2 = (Person) session1.get(Person.class, 1); // 获取p2对象
- System.out.println(p1 == p2); // 第一次比较
- tx1.commit(); // 提交事务
- session1.close(); // sesison1对象关闭,一级缓存被清理
- Sessionsession2 = HibernateUtils.getSession(); // 开启第二个Session对象
- Transactiontx2 = session2.beginTransaction();// 开启第二个事务
- Personp3 = (Person) session2.get(Person.class, 1); // 获取p3对象
- System.out.println(p1 == p3); // 第二次比较
- Personp4 = (Person) session2.get(Person.class, 1); // 获取p4对象
- System.out.println(p3 == p4); // 第三次比较
- tx2.commit(); // 提交事务2
- session2.close(); // session2关闭
- }
5. 运行程序并查看结果
使用 JUnit 测试运行 testCache() 方法,运行成功后,控制台的输出结果如图 2 所示。
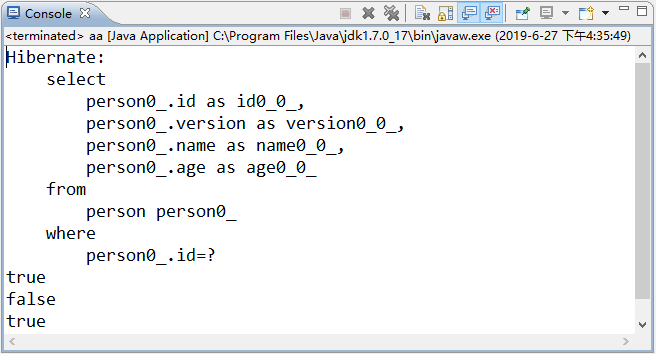
图 2 testCache() 方法的测试结果
从图 2 中可以看到,控制台只输出了一个查询 SQL,这说明 Hibernate 只在数据库中查询了一次。而下面的 true、false 和 true 是三次比较输出的结果。详细解释具体如下。
1)在上述代码中,开启了两个 Session 和事务,从第一个 Session 中获取 p1 对象时,由于一级缓存和二级缓存中没有相应的数据,需要从数据库中查询,所以发出了 SQL 语句。
2)查询出 p1 对象后,p1 对象会保存到一级缓存和二级缓存中。当获取 p2 对象时,因为 Session 没有关闭,所以会从一级缓存中取出该对象。由于 p1 和 p2 对象都保存在一级缓存中,而且指向的是同一实体对象,所以第一次输出结果为true。
3)接着提交事务 tx1,并关闭 session1,此时一级缓存中的数据会被清除。
4)接下来开启第二个 Session 和事务,获取 p3 对象,此时控制台没有产生 SQL 语句是因为 p3 对象是从二级缓存中获取的。取出后,二级缓存会将数据同步到一级缓存中,这时 p3 对象又在一级缓存中存在了。
5)因为 p3 对象是从二级缓存中获取的,而二级缓存中存储的都是对象的散装数据,它们会重新 new 出一个新的对象,所以第二次输出的结果为 false。
6)最后获取 p4 对象时,由于一级缓存中已经存在了 Person 对象,Hibernate 会直接从一级缓存中获取,所以输出结果为 true。