字节对齐的剖析
一、须要了解的名词和概念
1、数据类型自身的对齐值:即数据本身所占字节长度。
2、结构体或类的自身对齐值:即当中数据成员类型对齐值的最大值。
3、指定对齐值:由编程人员通过#pragma pack(value)指定的value值,通过#pragma pack()代码解除。
4、结构体、类、数据成员的有效对齐值:即2、3的较大值。
5、圆整: 即结构体成员变量占用总长度须要是对结构体有效对齐值的整数倍
以上为理解字节对齐的最基本要求,请耐心看完。
二、CPU的指令执行过程
在讨论字节对齐之前先简单看一下CPU对指令处理读写指令的工作过程:首先CPU从PC(程序计数器)中得到指令地址,通过总线从内存中取出指令(即其操作码+地址码),放入IR(指令寄存器)中(PC->AR[地址寄存器]->bus->DR[数据寄存器]->IR)对操作码进行译码,得到详细操作。同一时候PC自增1(下一条指令)。上述过程消耗一个CPU周期(机器周期)。然后进入下一个CPU周期。CPU取出其操作对象的地址码。通过总线在内存中定位到该地址。再进入下一个周期,若此时为写操作,则直接将数据写入到内存地址中,操作结束,若为读操作,则将数据通过总线从内存中取到CPU中,然后交由累加器或者其它控制元件进行处理完成。个人觉得。cache速度小于寄存器速度,故读取数据应当耗时很多其它。但由于计算机由CPU周期控制。在同步时钟信号的控制下应当是一样的,假设异步控制可能略有差异。
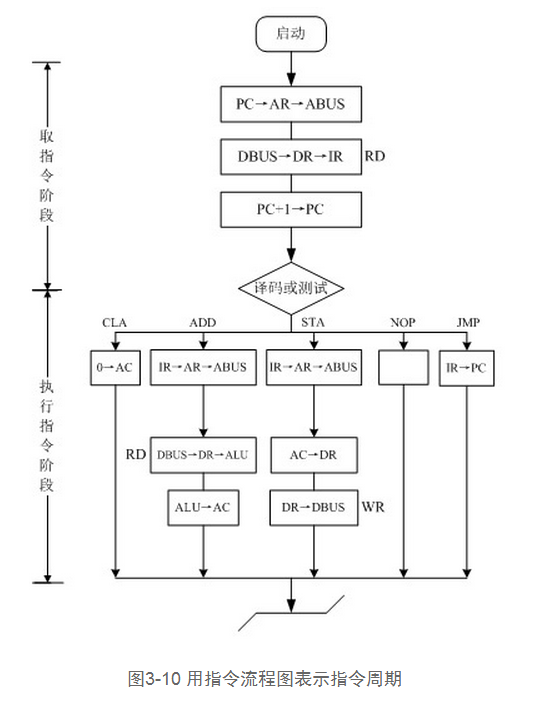
三、字节对齐的案例和分析
上述介绍看似和字长对齐没有不论什么关系,首先是为了让大家对CPU处理数据读写有个全面的认识。其次我们能够知道假设降低数据读取次数显然能够提高数据处理效率。
那么所谓的字节对齐就是起此作用的。宏观上来讲,它是通过一次读取有效对齐值来避免不必要的读操作,核心思想是使用空间去置换时间。
相信非常多人在对结构体使用sizeof运算符(orkeyword)的时候出现的那种大于其内部元素字节长度之和的现象非常是费解,这事实上就是由于字节对齐的原因,我们来看一个样例
struct A
{
int a1;
char a2;
short a3;
};
struct B
{
char b2;
int b1;
short b3;
};
intmain()
{
A a;
B b;
cout<<sizeof(a)<<''<<sizeof(b)<<endl;
system("pause");
return 0;
}
执行结果

注:这里使用dev进行编译,假设使用VC会编译时自己主动进行优化
分析一下原因:为了使程序更高速的对内存中数据进行操作,势必须要降低訪存时间,显然仅仅要尽可能多地(贪心思想)取出存放的数据就能达到这一目的。所以在存储结构体中数据时默认会依照最大的长度填充字段(不足补空,同一时候长度受限于系统总线长度)。
这样一来。A结构中。int为4字节,char+short为3字节,另外补足一个为空的字节,共计8字节(为4字节(32位)的整数倍)须要訪存2次就能取出数据(执行阶段)。而B结构体中,默认依照有效对齐值对齐,则char类型所占空间扩展为4字节,int占4字节,short扩展为4字节,共占12个字节。
设想一下假设没有字段对齐,当要取B结构中的第二个int时,将会先取出其前3个字节然后第二次訪存取出其最后一个字节。显然效率太低(举一个不太恰当的样例,好比用一个大夹子去夹取一些货物,假设每次夹取前都要调整夹子的宽度势必会耽误时间,也能够类比一下计算机网络中数据包的封装,比方TCP/IP协议中的数据包头都是对齐封装的。也是为了便于读取迅速以提高效率)
四、总结
存储规则:终于的结构体的总字节数应当保证为内部数据成员最长字节数的整数倍,且每一个数据成员的存储起始地址位置为字长的整数倍(即存储地址%字节长度=0)
以上就是字段对齐的过程和意义,须要注意的是有些比較严格的机器会有一些字段对齐相关的错误隐患。比方部分机器要求首地址均从偶数開始(由于数据所占字节数均为2的指数幂),假设从奇数边界去訪问数据变量就可能出现报错。
人类对CPU资源蛮横无理的榨取就如同当年资本主义剥削无产阶级每一分劳动剩余价值一样残酷。可是这样的“残酷”却将使人类文明不断向前迈进。
參考资料来源:
http://blog.csdn.net/21aspnet/article/details/6729724
http://blog.163.com/liuqiang_mail@126/blog/static/109968875201232012758232/
https://software.intel.com/zh-cn/articles/book-Processor-Architecture_CPU_work_process
http://home.51.com/fogball/diary/item/10055783.html