这是我的第一个爬虫代码。。。算是一份测试版的代码。大牛大神别喷。。。
通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配。
List<string> todo :进行抓取的网址的集合
List<string> visited :已经访问过的网址的集合
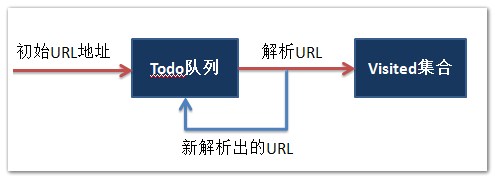
下面实现的是,给定一个初始地址,然后进行爬虫,输出正在访问的网址和已经访问的网页的个数。
需要注意的是,下面代码实现的链接匹配页面的内容如图一、图二所示:
- 图一:

- 图二:

简单代码示范如下:(测试版)
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using System.Web.Security; using System.IO; using System.Net; using System.Text.RegularExpressions; using System.Web; namespace Demo1 { public partial class Form1 : Form { public Form1() { InitializeComponent(); } private void button1_Click(object sender, EventArgs e) { Test1 a = new Test1(); a.getCurrentURL(); } public class Test1 { List<string> todo = new List<string>(); List<string> visited = new List<string>(); string startPoint = "http://www.cnblogs.com/lmei/";
public void getCurrentURL() { RequestSite(startPoint); while (todo.Count > 0)
{ string currentURL = todo[0]; RequestSite(currentURL); if (visited.Contains(currentURL)) //注释1 { Console.WriteLine("已经访问过了" + currentURL); todo.Remove((currentURL)); } else { Console.WriteLine("现在正在访问:===> " + currentURL); visited.Add(currentURL); Console.WriteLine("目前已经访问了:===> " + visited.Count + "个网页" ); todo.Remove((currentURL)); } } } public void RequestSite(string url) { WebRequest req = WebRequest.Create(url); HttpWebResponse res; try{ res = (HttpWebResponse)(req.GetResponse()); } catch (WebException ex) { res = (HttpWebResponse)ex.Response; } Stream st = res.GetResponseStream(); StreamReader rdr = new StreamReader(st); string s = rdr.ReadToEnd(); todo.AddRange(GetLink(s)); } List<string> GetLink(string htmlPage) { Regex regx = new Regex("http://www\.cnblogs\.com\/lmei\/p\/[0-9a-zA-Z]+\.html*" ,RegexOptions.IgnoreCase); MatchCollection matches = regx.Matches(htmlPage); List<string> results = new List<string>(); foreach (Match match in matches) { if (!visited.Contains(match.Value)) //注释2 { results.Add(match.Value); } } return results; } } } }
注释1 :是将已经访问过的网址排除。
注释2 :是将已经访问过的网址排除,但是可能由于同个网页中包含的两个(或两个以上)相同的链接,而且都没被访问过的,这样使得todo队列中会有相同的网址,所以需要注释1那部分进行再次过滤排除。其实也可以将注释2那部分删去,直接让注释1过滤就行。
接下来会进一步补充爬虫抓取的内容。。。