- 写在前面
之前做了个微信端顾客扫码评价员工的功能,除了打分数,还可以打标签。
需要统计分数和统计各个员工每种标签被点击的次数。
后来加了个要求,需要查看客户对某个员工一次服务所打出的标签组合。
在不修改表设计的前提下,解决这个问题!
实际开发时数据表设计需要考虑的东西比较多,而这篇分享主要是写函数的应用,为了方便看,所以表设计简化了,下面两个表的设计也都是简化过的。
数据表设计如下(只列出部分要用到的字段):

测试数据格式如下:


备注说明:
(1)tagIDs的值1,2,表示“态度非常好,笑容甜美”。
(2)表2的每1条记录代表客户的每1次评价。
所以,问题可以简化为查询表2中id=2的中文标签组合,返回“态度非常好,笑容甜美”。
在解决问题之前,先来认识几个函数!!!
--------@_@! 知识点一 ---------------------------------------------------------------------------
charindex函数
charindex函数返回字符或者字符串在另一个字符串中的起始位置。
charindex函数调用方法如下:CHARINDEX ( expression1 , expression2 [ , start_location ] )
--------------------------------------------------------------------------------------------------
语句示例:
select charindex('1', '1,2,3') as position select charindex('world', 'hello,world') as position select charindex('sql', 'hello,world') as position
在sqlserver中运行后的结果为:
1 7 0
可见,当experssion1与expression2没有匹配时返回0。
--------@_@??----------------------------------------------------------------------------
疑问:这样的写法是正确的吗?
提问:如果tagIDs='1,2,3,16',那么id=6的话,按上面的写法是不是也算是包含在里面?
-----------------------------------------------------------------------------------------
sqlserver中执行下面语句:
select 'found' as flag where charindex(ltrim(6),'1,2,3,16')>0
输出结果为:found
=_=|| 那么该如何处理使得6不会跟16里面的6匹配上呢?
当6变成“,6,”时,“,6,”就不会和“1,2,3,16”中的6匹配上了!
那么“,6,”和“1,6”中的6也匹配不上了!
把母字符串也进行修改也在前后都加上“,”
这样“6”和“,1,6,”、“,6,7,8,”中的6都可以匹配上了!同时也跟“,1,2,3,16,”中16的6匹配不上。
select 'notFound' as flag where charindex(','+ltrim(6)+',',','+'1,2,3,16'+',')=0
查询结果为:notFound。 问题解决~
--------@_@ 知识点二 -----------------------------------------------------------------------
STUFF ( character_expression , start , length ,character_expression )
参数说明:
character_expression :一个字符数据表达式。character_expression 可以是常量、变量,也可以是字符列或二进制数据列。
start :一个整数值,指定删除和插入的开始位置。如果 start 或 length 为负,则返回空字符串。 如果 start 比第一个character_expression 长,则返回空字符串。start 可以是 bigint 类型。
length :一个整数,指定要删除的字符数。如果 length 比第一个 character_expression 长,则最多删除到最后一个character_expression 中的最后一个字符。length 可以是 bigint 类型。
返回类型 :如果 character_expression 是受支持的字符数据类型,则返回字符数据。如果 character_expression 是一个受支持的 binary 数据类型,则返回二进制数据。
备注 :
如果开始位置或长度值是负数,或者如果开始位置大于第一个字符串的长度,将返回空字符串。
如果要删除的长度大于第一个字符串的长度,将删除到第一个字符串中的第一个字符。
如果结果值大于返回类型支持的最大值,则产生错误。
------------------------------------------------------------------------------------------------
语句示例:
select stuff('abcdef', 2,4,'123') --将'abcdef'从第2个开始,连续删掉4个字符,然后将'123'插入
执行结果:
a123f
----------@_@ 知识点三 ----------------------------------------------------------------
For xml path: 用于将查询结果集以XML形式显示
------------------------------------------------------------------------------------------
我们用下面这张表的数据来体验下:

示例语句:
select id, tagName from tb_tagList for xml path
执行结果:
<row> <id>1</id> <tagName>态度非常好</tagName> </row> <row> <id>2</id> <tagName>笑容甜美</tagName> </row> <row> <id>3</id> <tagName>效率很高</tagName> </row> <row> <id>5</id> <tagName>对人热情</tagName> </row> <row> <id>6</id> <tagName>为他人着想</tagName> </row> <row> <id>7</id> <tagName>细心负责</tagName> </row>
如果想改成用“,”,修改语句如下:
SELECT tagName + ',' FROM tb_tagList FOR XML PATH('')
执行结果:
态度非常好,笑容甜美,效率很高,对人热情,为他人着想,细心负责,
会发现最后面还有个逗号!
如果想把它去掉,可以修改语句,将逗号加在每个标签的前面,然后stuff函数把第一个逗号替换为空字符串。
将 tagName + ',' 改为 ',' + tagName
修改语句
SELECT tagNames = (stuff (( select ','+tagName FROM tb_IntegralTagList where fk_scoreCriterion_id = 1 FOR XML PATH('')),1,1,''))
执行结果:
态度非常好,笑容甜美,效率很高,对人热情,为他人着想,细心负责
接下来开始解决问题!!!
比如,查看表2中id=6的评价标签,输出结果为“态度非常好,笑容甜美”


解决方案如下:
(1)先把客户评价表中的标签序列对应的标签查出来

(2)再将tagName进行拼接,变成下面这样

开始实践!!!
由于之前写过这样的查询语句“select * from tabel where id in (1,2,3,4)”,所以想都没想,直接将前端传入的tagIDs = "1,2,3"直接查询。

(-_-)||| 智障~居然犯这种低级错误~
继续解决上面的问题,利用charindex,把id转成字符,看是否包含于tagIDs里面
(1)首先去tagIDs里id对应的标签值
select a.tagName, b.id as appraisalId from tb_tagList a, tb_customerAppraisal b where charindex(','+ltrim(a.id)+',',','+b.tagIDs+',')>0
运行结果:
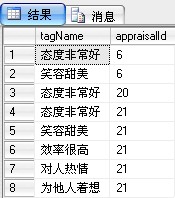
(2)将相同appraisalId的标签进行拼接,语句整理如下:
select b.id as appraisalId,a.tagName into #temp from tb_tagList a, tb_customerAppraisal b where charindex(','+ltrim(a.id)+',',','+b.tagIDs+',')>0 select appraisalId, tagNames = (stuff((select ',' + tagName from #temp where appraisalId = c.appraisalId for xml path('')),1,1,'')) from #temp c group by c.appraisalId drop table #temp
执行结果:(这里将每一次评价的标签都进行拼接,如有需要可以进行进一步地细节处理 )
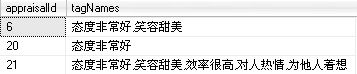
@_@)Y 分享到此结束~