| 作业要求 | 第四次作业 |
|---|---|
| 我在这个课程的目标 | 能够实现简单软件的开发,对软件进行测试、维护和管理,可以将本课程与之前所学联系起来 |
| 此作业在哪个具体方面帮我实现目标 | 软件开发过程中的团队合作 |
| 参考文献 | 程序参考文献: https://blog.csdn.net/lbj1260200629/article/details/89600055 https://blog.csdn.net/weixin_43936464/article/details/84779924 效能测试参考文献: https://www.cnblogs.com/MonC/articles/9744687.html 单元测试参考文献: https://blog.csdn.net/huilan_same/article/details/52944782 回归测试参考文献: https://blog.csdn.net/LWT000aa/article/details/78735235 |
| gitee链接 | gitee链接 |
作业一、代码规范复审
https://www.cnblogs.com/lmengmeng/p/12613565.html
作业二、结对编程
下面只给出了红楼梦的相关代码,水浒传的代码可通过gitee链接查看
组队成员的博客:https://www.cnblogs.com/youmine/p/12635776.html
一、程序代码和运行结果
# 红楼梦人物统计
import jieba
import csv
class NameCount():
def getNameTimesSort(self, name_list, txt_path):
# 添加jieba分词
mydict = ['琏二奶奶', '凤哥儿', '凤丫头', '宝姑娘', '颦儿', '二姑娘', '三姑娘', '四姑娘', '云妹妹', '蓉大奶奶']
for item in mydict:
jieba.add_word(item)
#打开并读取txt文件
txt = open(txt_path, "r", encoding='utf-8').read()
# 定义别名列表
bieming = [["王熙凤", "凤丫头", '琏二奶奶', '凤姐', '凤哥儿', '凤辣子','熙凤'],["林妹妹", "黛玉", '林姑娘', '林黛玉'], ["宝钗", '宝姑娘', '宝丫头', '宝姐姐', '薛宝钗'],
['探春', '三姑娘', '贾探春'], ['湘云', '云妹妹', '史湘云'],['迎春', '二姑娘', '贾迎春'],['元春', '大姑娘', '娘娘', '贵妃', '元妃', '贾元春'],
['惜春', '四姑娘', '贾惜春'], ['妙玉'],['巧姐'], ['李纨', '大嫂子'], ['秦可卿', '可卿', '蓉大奶奶']]
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 计算出场次数(各个别名的合计次数)
lst = list()
for i in range(12):
lt = 0
for item in bieming[i]:
lt += counts.get(item, 0)
lst.append(lt)
items = list()
for i in range(12):
items.append([name_list[i], lst[i]])
items.sort(key=lambda x: x[1], reverse=True)
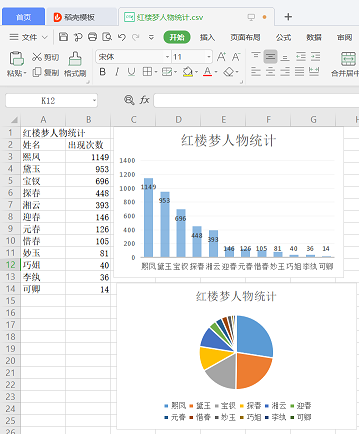
f = open('红楼梦人物统计.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['红楼梦人物统计'])
csv_writer.writerow(["姓名", "出现次数"])
for i in range(12):
word, count = items[i]
csv_writer.writerow([word, count])
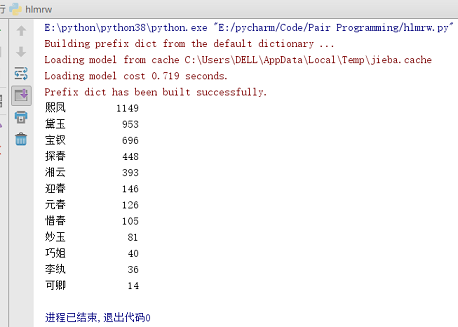
print("{0:<10}{1:>5}".format(word, count))
f.close()
return items
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
# txt文件所在路径
txt_path = 'E:pycharmCodePair Programming红楼梦.txt'
NameCount().getNameTimesSort(name_list,txt_path)
二、单元测试
import unittest
from hlmrw import*
class MyTestCase(unittest.TestCase):
def setUp(self):
pass
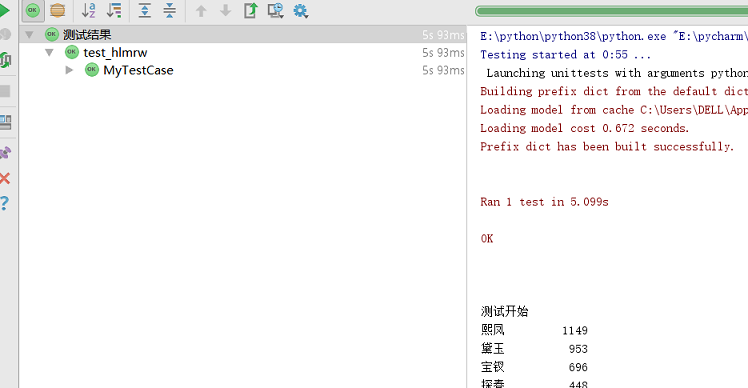
def test_something(self):
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
txt_path = 'E:pycharmCodePair Programming红楼梦.txt'
name_list_count = [1149, 953, 696, 448, 393, 146, 126, 105, 81, 40, 36, 14]
items = list()
for i in range(12):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list,txt_path))
def tearDown(self):
pass
if __name__ == '__main__':
unittest.main()
三、回归测试
#page.py
from selenium import webdriver
import time
#打开浏览器
path = "C:/UsersDELLAppDataLocalGoogleChromeApplicationchromedriver.exe"
driver = webdriver.Chrome(executable_path=path)
#driver = webdriver.Chrome()
#最大化窗口
driver.maximize_window()
#打开百度
driver.get("http://www.baidu.com")
#休眠一秒
time.sleep(10)
#关闭浏览器
driver.close()
#hgtest_hlmrw.py
import unittest
from hlmrw import *
import page
import test_hlmrw
import HTMLTestRunner
class MyTestCase(unittest.TestCase):
def setUp(self):
print("测试开始")
def test_something(self):
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
txt_path = 'E:pycharmCodePair Programming红楼梦.txt'
name_list_count = [1149, 953, 696, 448, 393, 146, 126, 105, 81, 40, 36, 14]
items = list()
for i in range(12):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list,txt_path))
def tearDown(self):
print("测试结束")
if __name__ == '__main__':
testunit = unittest.TestSuite()
testunit.addTest(MyTestCase('test_something'))
filename = '红楼梦回归测试.html'
fp = open(filename, 'wb')
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u'红楼梦人物统计', description=u'用例执行')
runner.run(testunit)
fp.close()
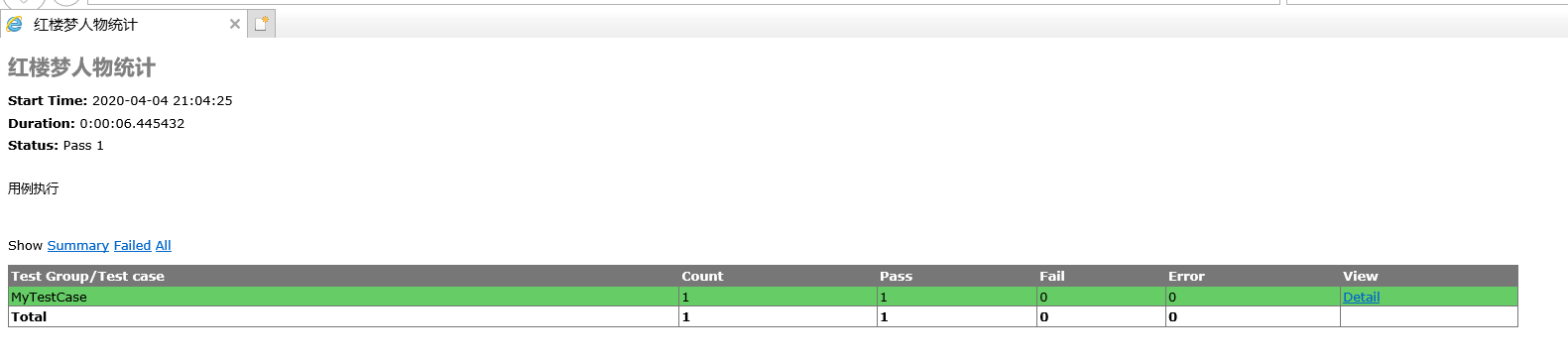
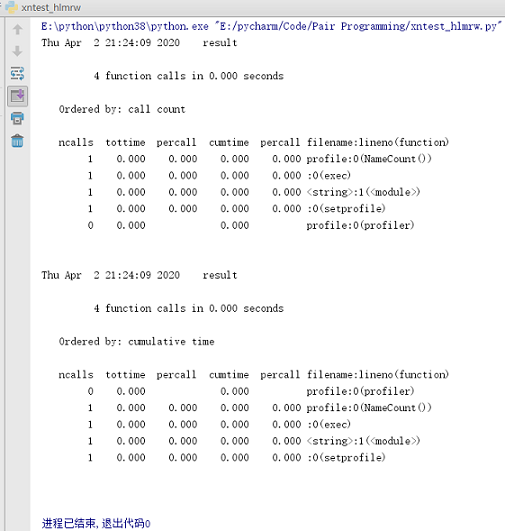
四、效能测试
import pstats
import profile
from hlmrw import*
if __name__ == '__main__':
profile.run('NameCount()', 'result')
# 直接把分析结果打印到控制台
p = pstats.Stats('result') # 创建Stats对象
p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序
p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
五、托管代码
六、总结
| PSP | Personal Software Process Stages | Time |
|---|---|---|
| Planning | 计划 | 168h |
| ·Estimate | ·估计这个任务需要多少时间 | 30h |
| Development | 开发 | |
| ·Analysis | ·需求分析(包括学习新技术) | 6h |
| ·Design Spec | ·生成设计文档 | 1h |
| ·Design Review | ·设计复审(和同学审核设计文档) | 1h |
| ·Design Standard | ·代码规范(为目前的开发制定合适的规范) | 0.5h |
| ·Design | ·具体设计 | 4h |
| ·Coding | ·具体编码 | 48h |
| ·Code Review | ·代码复审 | 24h |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 72h |
| Reporting | 报告 | |
| ·Test Reportt | ·测试报告 | 1.5h |
| ·Size Measurement | ·计算工作量 | 0.5h |
| ·Postmortem&Process Improvement Plan | ·事后总结,并提出过程改进计划 | 0.5h |
| Total | 合计 | 189h |
本次作业中需要运用python软件来书写,统计人物时要用到jieba库,在回归测试中需要用到selenium库、webdriver、HTMLTestRunner(注意python2和python3之间的区别)。