1、先看一个实际的需求
在五子棋中,有存盘退出和续上盘的功能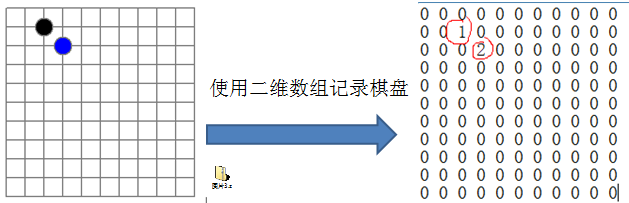
由于该二维数组中的很多值都是0,因此记录了很多没意义的数据,占用了很多连续的内存空间,为了节省内存空间,我们可以把这个数组做一个转换来存储,以达到减少内存开销的目的,因此,稀疏数组就被提出来了。
2、基本介绍
当一个数组中大部分元素是0,或者为同一个元素时,可以使用稀疏数组来保存该数组,具体处理方法是: > 1、稀疏数组有三列,分别记录了原数组有多少行、有多少列、有多少个不同的值 > 2、把不同的值的元素的行列和值记录在一个小规模的数组中,从而缩小程序的规模如上面的数组:

可以记录为:
| 11 | 11 | 2 |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 3 | 2 |
3、代码实现
``` public class SparseArray {public static void main(String[] args) {
int chessArr[][] = new int[11][12];//为了区别行列,此处将列设置为12
chessArr[1][2] = 1;
chessArr[2][3] = 2;
//输出原始的二维数组
System.out.println("原始的二维数组:");
for(int[] row : chessArr){
for(int data : row){
System.out.printf("%d ", data);
}
System.out.println();
}
//将二维数组转换成稀疏数组
//1、先遍历二维数组,统计非0的个数
int sum = 0;
for(int[] row : chessArr){
for(int data : row){
if(data != 0){
sum++;
}
}
}
//2、创建对应的稀疏数组
int[][] sparseArray = new int[sum + 1][3];
sparseArray[0][0] = chessArr.length;
sparseArray[0][1] = chessArr[0].length;
sparseArray[0][2] = sum;
int x = 1;//稀疏数组存储数据从第二行开始
for(int i = 0 ; i < chessArr.length ; i++){
for(int j = 0 ; j < chessArr[i].length ; j++){
if(chessArr[i][j] != 0){
sparseArray[x][0] = i;
sparseArray[x][1] = j;
sparseArray[x][2] = chessArr[i][j];
x++;
}
}
}
System.out.println("稀疏数组:");
for(int[] row : sparseArray){
for(int data : row){
System.out.printf("%d ", data);
}
System.out.println();
}
int[][] originArray = new int[sparseArray[0][0]][sparseArray[0][1]];
for(int i = 1 ; i < sparseArray.length ; i++){
originArray[sparseArray[i][0]][sparseArray[i][1]] = sparseArray[i][2];
}
System.out.println("恢复后的原始二维数组:");
for(int[] row : originArray){
for(int data : row){
System.out.printf("%d ", data);
}
System.out.println();
}
}
}
运行结果:
