题目:论文查重
github连接:https://github.com/ml-h/ml-h-h/blob/master/031804114/第一次编程作业最终版.py
*1.基本理论原理描述如下
第一步,向量空间模型VSM
向量空间模型(Vector Space Model,简称VSM)表示通过向量的方式来表征文本。一个文档(Document)被描述为一系列关键词(Term)的向量。
简言之,判断一篇文章是否是你喜欢的文章,即将文章抽象成一个向量,该向量由n个词Term组成,每个词都有一个权重(Term Weight),不同的词根据自己在文档中的权重来影响文档相关性的重要程度。
Document = { term1, term2, …… , termN }
Document Vector = { weight1, weight2, …… , weightN }
#V(d)=(t1w1(d);...;tnWn(d))
其中ti(i=1,2,...n)是一列相互之间不同的词,wi(d)是ti在d中对应的权值。
选取特征词时,需要降维处理选出有代表性的特征词,包括人工选择或自动选择。
第二步,TF-IDF
特征抽取完后,因为每个词语对实体的贡献度不同,所以需要对这些词语赋予不同的权重。计算词项在向量中的权重方法——TF-IDF。
它表示TF(词频)和IDF(倒文档频率)的乘积:
TF-IDF=词频(TF)*逆文档频率(IDF)
逆文档频率网上有很多解释,最后TF-IDF计算权重越大表示该词条对这个文本的重要性越大
第三步,余弦相似度计算

其中分子表示两个向量的点乘积,分母表示两个向量的模的积。
原理到代码实现的过程部分
============
calss:

计算相对词频:
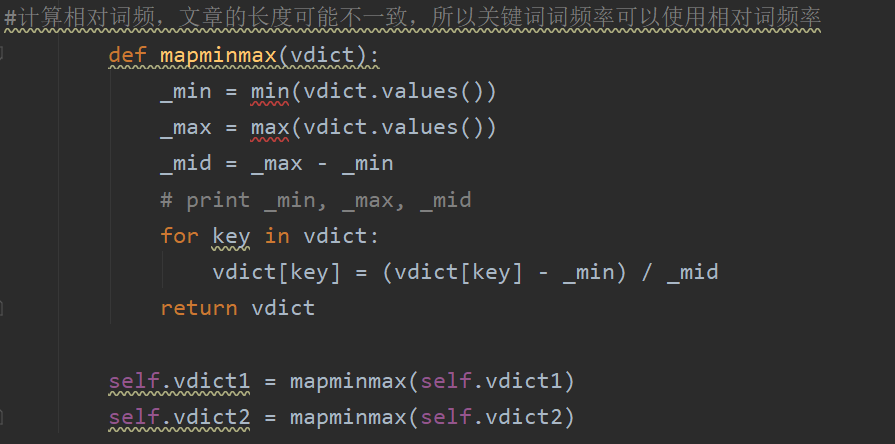
三:异常处理、函数分析、性能改进
异常处理:
try:
f=open(output,"w")
f.write(result+"
")
f.close()
print("结果已存入文件夹中")
except IOError:
print("Error: 没有找到文件或读取文件失败")
函数分析:
def __init__(self, target1, target2, topK=800):
self.target1 = target1
self.target2 = target2
self.topK = topK
target1和target2分别为对比的两篇文章样本,topK为将提取出前面800个关键词
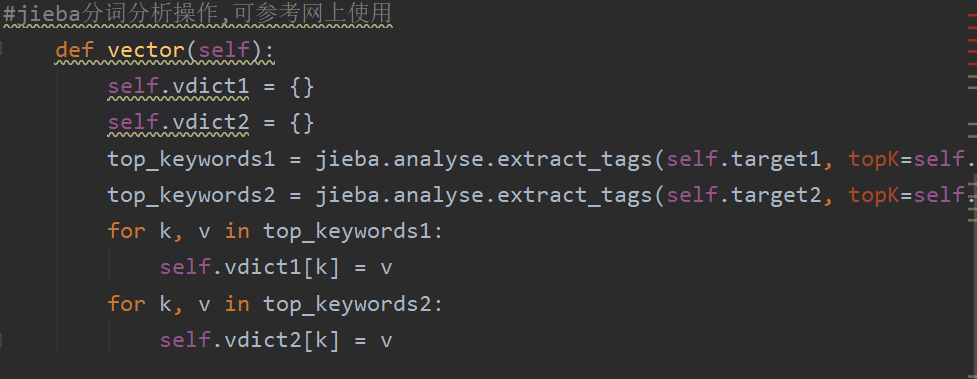
利用jieba.analyse库对文本拆分

计算相对的词频并且得到最后的数据。
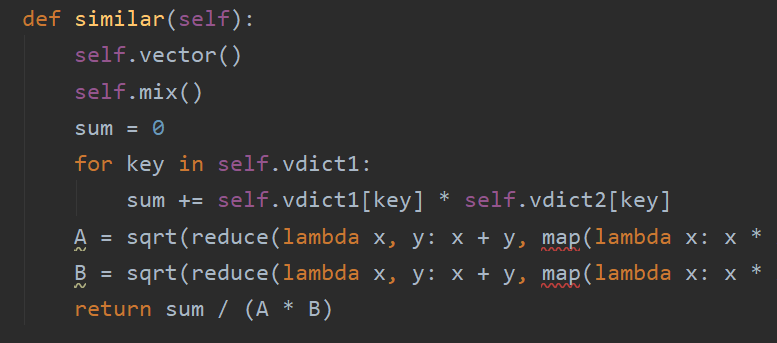
相似度的计算,利用的是文章相似度的计算公式。
性能改进:

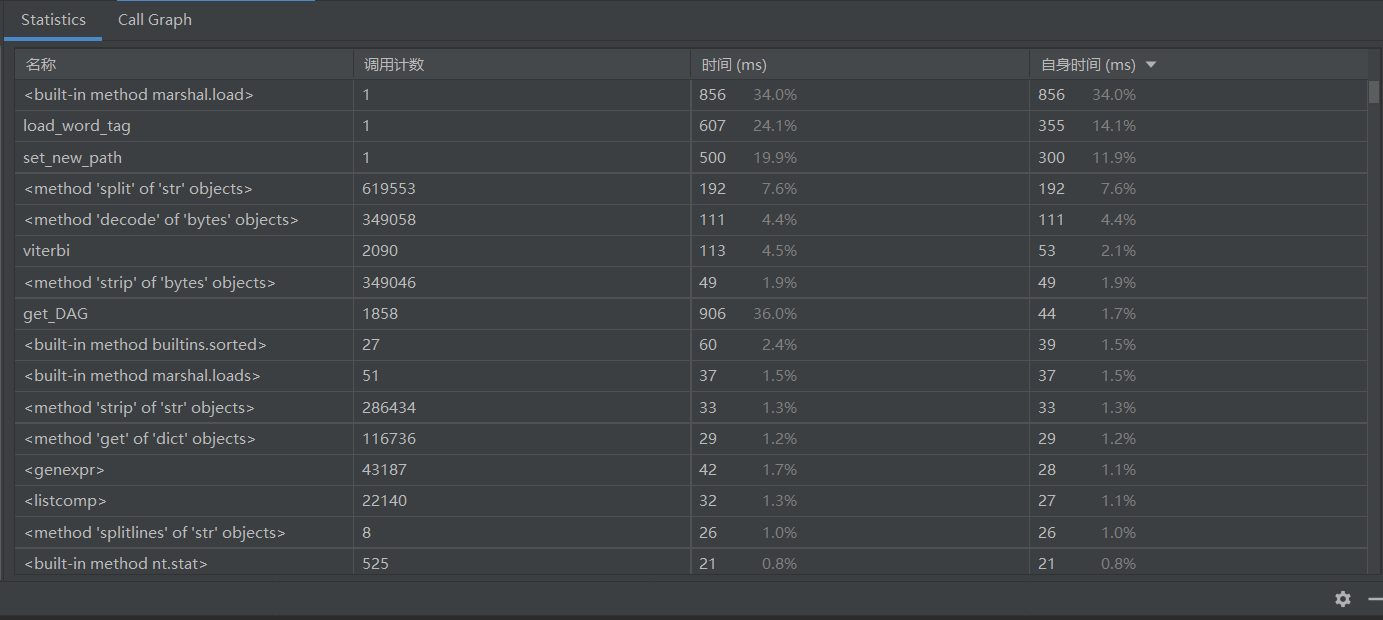


四:单元测试展示

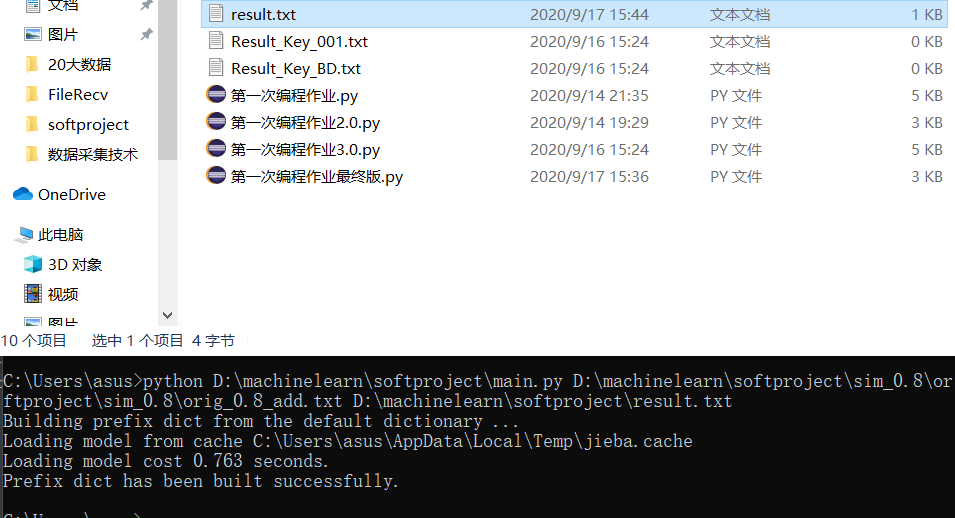
五:PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 130 |
| Estimate | 估计这个计划需要多少时间 | 60 | 60 |
| Development | 开发 | 210 | 220 |
| Analysis | 需求分析 | 500 | 480 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 | 40 | 60 |
| Design | 具体设计 | 130 | 120 |
| Coding | 具体编码 | 130 | 120 |
| Code Review | 代码复审 | 40 | 30 |
| Test | 测试 | 120 | 200 |
| Reporting | 报告 | 30 | 20 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进过程 | 40 | 50 |
| 合计 | 1530 | 1620 |
六:总结
光题目就研究了很久,之前没用过测试的软件,安全不知道这个东西,疯狂百度,查阅博客,找到适合的相近的方法,利用修改。总的过程很艰辛,很费时间,但是确实也看到了很多不一样的东西。