1.爬虫实战项目,爬取小说,只能爬取免费小说(VIP小说需要充钱登陆:方法有所差异,后续会进行讲解)
本教程出于学习目的,如有犯规,请留言联系
爬取网站:起点中文网,盗墓笔记免费篇
https://book.qidian.com/info/68223#Catalog
2.网页结构分析
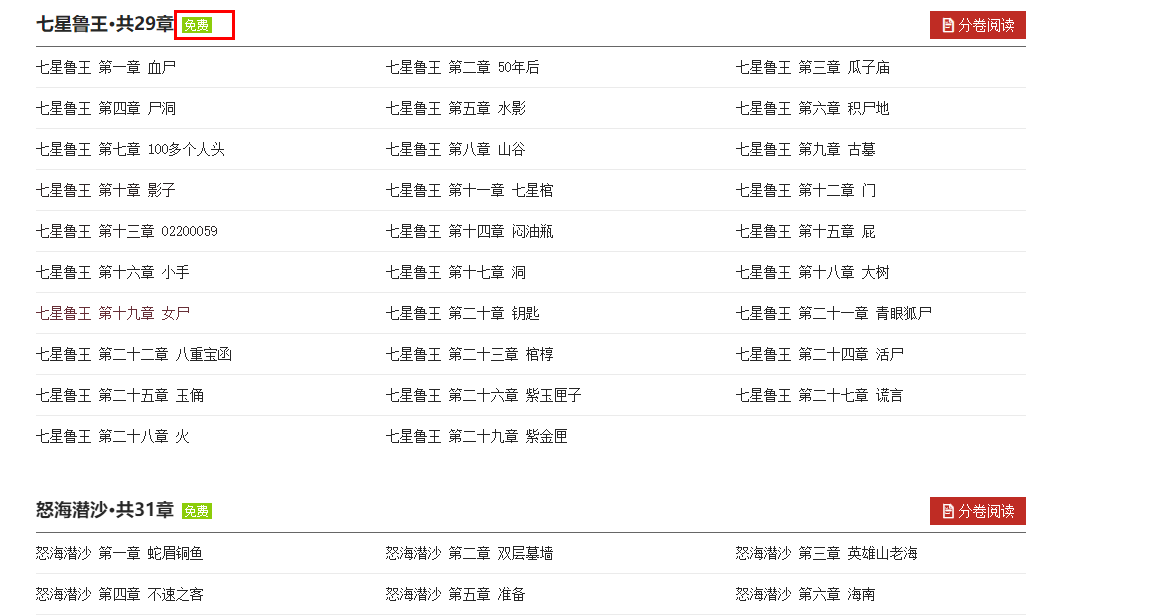
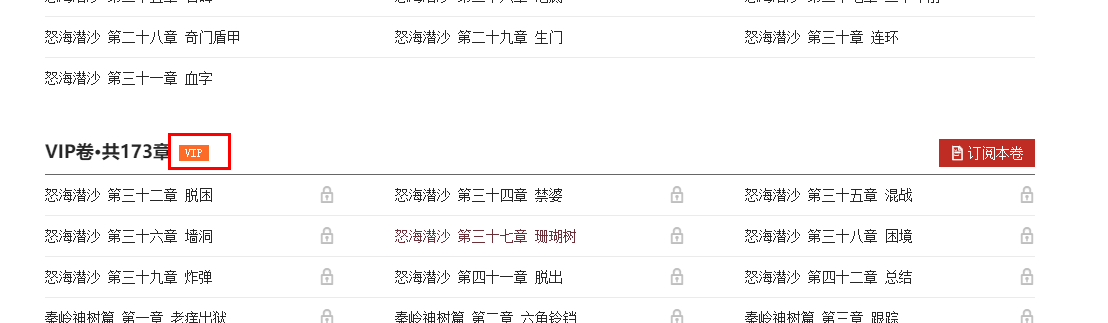

结构分析发现:每一大标题在div元素里面,是否免费,包含在div元素的孙子元素span的类属性里面(class='free' 还是 class='vip')
因此:如果我们想要提取免费章节小说,需要先根据span元素进行判断。
3.完整代码
#!/usr/bin/env python #-*- coding:utf-8 -*- '''爬取盗墓笔记小说免费版 ''' import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } class Story(object): def __init__(self,url): self.url = url def get_html(self,url): try: response = requests.get(url,headers=headers) if response.status_code == 200: return response.text else: return None except Exception as e: print('wrong', e) def get_soup(self,html): try: soup = BeautifulSoup(html,'html.parser') except: soup = BeautifulSoup(html, 'xml') return soup def start(self): html = self.get_html(self.url) soup = self.get_soup(html) try: free_result = soup.select('div.volume span.free') if free_result: for free in free_result: chapters = free.parent.parent.select('li a') # 理解为什么要找到parent元素 for chapter in chapters: title = chapter.text.strip().replace(' ', '_') href = 'https:' + chapter['href'] html = self.get_html(href) soup = self.get_soup(html) content = soup.select('div.read-content')[0].text.strip().replace('u3000', ' ') print('�33[1;34m开始爬取: {title}�33[0m'.format(**locals())) with open(title+'.txt', 'w') as fw: fw.write(content) except: None if __name__ == '__main__': url = 'https://book.qidian.com/info/68223#Catalog' gg = Story(url) gg.start()