20155207 2006-2007-2 《Java程序设计》第5周学习总结
教材学习内容总结
第八章
语法与继承架构
Java中的错误以对象方式呈现为 java.lang.Throwable 的个种子类实例。
使用try...catch
- Scanner对象的nextInt()方法,可以将用户输入的下一个字符串剖析为int值
- 如果出现InputMismatchException错误信息,表示不符合Scanner对象预期。
- Java中所有信息都会被打包为对象,如果愿意,可以尝试(try)捕捉(catch)代表错误的对象后做一些处理
try{
...(需要尝试捕捉的程序代码)
}
catch(... ex){
...(发生错误时执行的代码)
}
这里使用了try、catch语法,JVM会尝试执行try区块中的程序代码。如果发生错误,执行流程会跳离错误发生点,然后比较catch括号中声明的类型,是否符合被抛出的错误对象类型,如果是的话,就执行catch区块中的程序代码。
异常继承架构
- 错误会被包装为对象,这些对象都是可抛出的,因此设计错误对象都继承自 java.lang.Throwable 类,Throwable定义了取得错误信息、堆栈追踪等方法,他有两个子类:java.lang.Error 和 java.lang.Exception。
- Error与其子类实例代表严重系统错误。
- Exception或其子类实例表现程序设计本身的错误,通常称错误处理为异常处理。
- Exception或其子对象,但非属于RuntimeException或其子对象,被称为受检异常。
- 属于Runtimeexception衍生出来的实例,代表API设计者实现某方法时,某些条件成立时会引发错误,而且认为API客户端应该在调用方法前做好检查,以避免引发错误,称为非受检异常。
- String 的 matches()方法中设定了"d*",是规则表示式,表示检查字符串中的字符是不是数字,若是则match()会返回true。
- 如果父类异常对象在子类异常对象前被捕捉,则catch子类异常对象的区块将永远不会被执行。
- 多重捕捉语法
try {
做一些事...
} catch(IOException | InterruptionedException | ClassCastException e) {
e.printStackTrace();
}
catch括号中列出的异常不得有继承关系,否则会发生编译错误。
catch or throw?
-
Scanner创建时可以给予InoutStream实例,而FileInputStream可指定档名来开启与读取文档内容更,是InputStream的子类。
-
操作对象的过程中如果方法设计流程中发生异常,而设计时没有充足的信息知道该如何处理,那么可以抛出异常,让调用方法的客户端来处理。为了告诉编译程序这个事实,必须用 throws 声明此方法会抛出的异常类型或父类型,编译程序才会让你通过编译。
-
在catch区块进行完部分错误处理之后,可以使用throw(不是throws)将异常再抛出
-
如果抛出的是受检异常,表示你认为客户端有能力且应处理异常,此时必须在方法上使用throws声明。
-
FileNotFoundException与EOFException都是一种IOException。
-
如果使用继承时,父类某个方法声明throws 某些异常,子类重新定义该方法时可以:
-
不声明throws任何异常
-
throws父类该方法中声明的某些异常
-
throws父类该方法中声明异常的子类
-
-
但是不可以:
-
throws父类方法中未声明的其他异常
-
throws父类方法中声明异常的父类
-
自定义异常
- java是唯一采用受检异常的语言,两个目的: 一是文件化;二是提供编译程序信息。
- 自定义异常类别时,可以继承
Throw、Error或Exception或其子类,如果不是继承自Error或RuntimeException,那么就会是受检异常
堆栈追踪
若想得知异常发生的根源,以及多重方法调用下异常的堆栈传播,可以利用异常对象自动收集的堆栈追踪来取得相关信息
- 查看堆栈追踪最简单的方法,就是直接调用异常对象的printStackTrace()。
- 如果想要取得个别的堆栈追踪元素进行处理,则可以使用getStackTrace()。
- 要善用堆栈追踪,前提是程序代码中不可有私吞异常的行为。
- 如果想要异常堆栈起点为重抛异常的地方,可以使用 fillInStackTrace() 方法,这个方法会重新装填异常堆栈,将起点设为重抛异常的地方,并返回 Throwable 对象
关于assert
assert有两种使用的语法:
- assert boolean_expression;
- assert boolean_expression : detail_expression;
boolean_expression 若为 true,则什么事都不会发生,如果为 false,则会发生 java.lang.AssertionError,此时若采取的是第二个语法,则会将 detail_expression 的结果显示出来,如果当中是个对象,则调用 toString() 显示文字描述结果。
断言功能
-
断言:程序执行的某个时间点或某个情况下,必然处于或不处于何种状态,这是一种断言。
-
何时使用断言?
- 断言客户端调用方法前,已经准备好某些前置条件(通常在private方法之中)
- 断言客户端调用方法前,已经准备好某些前置条件(通常在private方法之中)
- 断言客户端调用方法后,具有方法承诺的结果。
- 断言对象某个时间点下的状态。
- 使用断言取代批注。
- 断言程序流程中绝对不会执行到的程序代码部分。
-
checkGreaterThanZero()是一种前置条件检查,如果程序上线后就不再需要这种检查的话,可以将之以assert取代,并在开发阶段使用 -ea 选项,而程序上线后取消该选项。 -
使用断言的时机:一定不能有
default的状况,也可以使用assert来取代。
异常与资源管理
使用 finally
- 无论try区块中有无发生异常,若撰写有finally区块,则finally区块一定会被执行。
- 如果程序撰写的流程中先 return 了,而且也有 finally 区块,那 finally 区块会先执行完后,再将值返回。
- 尝试关闭资源语法:想要尝试自动关闭资源的对象,是在撰写在 try 之后的括号中,如果无须catch处理任何异常,可以不用撰写,也不用撰写 finally 自行尝试关闭资源。
java.lang.AutoCloseable 接口
- JDK的尝试关闭资源语法可套用的对象,必须操作java.lang.AutoCloseable接口。
- 尝试关闭资源语法也可以同时关闭两个以上的对象资源,只要中间以分号分隔。
- 在 try 的括号中,越后面撰写的对象资源会越早被关闭。
第九章
使用Collection收集对象
Collection架构
- 收集对象的行为,像是新增对象的 add()方法、移除对象的remove()方法等,都是定义在 java.util.Collection中。
- 既然可以收集对象,也要能逐一取得对象,这就是java.lang.Iterable定义的行为,它定义了iterator()方法返回 java.lang.Iterable操作对象,可以让你逐一取得收集的对象。
- 收集对象的共同行为定义在 Collection 中,然而收集对象会有不同的需求。
-
java.util.List:收集时记录每个对象的索引顺序,并可依索引取回对象
-
java.util.Set:收集的对象不重复,具有集合的行为
-
java.util.Queue:收集对象时以队列方式,收集的对象加入至尾端,取得对象时从前端
-
java.util.Deque:可对Queue的两端进行加入、移除等操作
-
java.util.ArrayList:以数组操作 List(想要收集对象时具有索引顺序,操作方法之一是使用数组)
-
List
List 是一种Collection,作用是收集对象,并以索引方式保留收集的对象顺序,其操作类之一是java.util.ArrayList.
ArrayList特性
- 考虑是否使用 ArrayList,就等于考虑是否要使用到数组的特性。
- 数组在内存中会是连续的线性空间,根据索引随机存取时速度快,如果操作上有这类需求时,像是排序,就可使用ArrayList,可得到较好的速度表现。
- ArrayList有个可制定容量的构造函数,如果大致知道将收集的对象范围,实现建立足够长度的内部数组。
LinkedList特性
LinkedList在操作List接口时,采用了链接(Link)结构。- 在
SimpleLinkedList内部使用Node 封装新增的对象,每次add()新增对象之后,将会形成链状结构。 - 若收集的对象经常会有变动索引的情况,也许考虑链接方式操作的List会比较好,像是随时会有客户端登录或注销的客户端List,使用LinkedList会有比较好的效率。
内容不重复的Set
使用 Set 接口操作对象:在收集对象的过程中若有相同的对象,则不再重复收集,若有这类需求,可以使用 Set 接口的操作对象。
- String的split()方法,可以指定切割字符串的方式。
- set不能将重复的对象排除,java中许多要判断对象是否重复,都会调用hashCode()与equals()。
支持队列操作的Queue
-
Queue继承自Collection,所以也具有Collection的add()、remove()、element()等方法,然而Queue定义了自己的offer()、poll()与peek()等方法,最主要的差别之一在于:add()、remove()、element()等方法操作失败时会抛出异常,而offer()、poll()与peek()等方法操作失败时会返回特定值。
-
如果对象有操作 Queue,并打算以队列方式使用,且队列长度受限,通常建议使用offer()、poll()与peek()等方法
-
offer():offer()方法用来在队列后端加入对象,成功返回 true ,失败则返回 false
-
poll():poll()方法用来取出队列前端对象,若队列为空则返回 null
-
peek():peek()用来取得(但不取出)队列前端对象,若队列为空则返回 null
-
LinkeedList 不仅操作了 List 接口,也操作了 Queue 的行为,所以可将 LinkedList 当作队列来使用
-
对队列的前端和尾端进行操作:在前端加入对象与取出对象,在尾端加入对象与取出对象,Queue的子接口Deque就定义了这类行为
-
操作失败时抛出异常:addFiret()、removeFirst()、getFirst()、addLast()、removeLast()、getLast()
-
操作失败时返回特定值:offerFirst()、pollFirst()、peekFirst()、offerLast()、pollLast()、peekLast()
-
java.util.ArrayDeque操作了Deque接口,可以使用ArrayDeque来操作容量有限的堆栈
使用泛型
执行时期被收集的对象会失去形态信息,也因此取回对象之后,必须自行记得对象的真正类型,并在语法上告诉编译程序让对象重新扮演为自己的类型。
Lambda表达式
- Lambda 表达式:
Request request = () -> out.printf("处理数据 %f%n",Math.random());
-
相对于匿名类语法来说,Lambda表达式的语法省略了接口类型与方法名称,->左边是参数列,而右边是方法本体
-
在使用 Lambda 表达式,编译程序在推断类型时,还可以用泛型声明的类型作为信息来源
-
虽然不鼓励使用Lambda表达式来写复杂的演算,不过若流程较为复杂,无法在一行的Lambda表达式中写完时,可以使用区块{}符号包括演算流程
-
在Lambda表达式中使用区块时,如果方法必须返回值,在区块中就必须使用return
Iterable与Iterator
-
iterator() 方法会返回 java.util.Iterator接口的操作对象,这个对象包括了Collection收集的所有对象,可以使用Iterator的hasNext() 看看有无下一个对象,若有,再使用 next() 取得下一个对象
-
interator()方法提升至新的java.util.Iterable父接口
-
在JDK5之后有了增强式for循环,除了运用在数组上,还可运用在操作Iterable接口的对象上
-
Iterable 新增了 forEach() 方法,可以让你对迭代对象进行指定处理
Comparable与Comparator
-
Collections的sort()方法要求被排序的对象必须操作java.lang.Comparable接口,这个接口有个compareTo()方法必须返回大于0、等于0或小于0的数
-
Collections的sort()方法有另一个重载版本,可接受java.util.Comparator接口的操作对象,如果使用这个版本,排序方式将根据Comparator的compare()定义来决定
-
在Java的规范中,跟顺序有关的行为,通常要不对象本身是Comparable,要不就是另行指定Comparator对象告知如何排序
-
JDK8在List上增加了sort()方法,可接受Comparator实例来指定排序方式
键值对应的Map
常用 Map 操作类
-
若要根据某个键来取得对应的值,可以事先利用java.util.Map接口的操作对象来建立键值对应数据,之后若要取得值,只要用对应的键就可以迅速取得
-
建立 Map 操作对象时,可以使用泛型语法指定键与值的类型
-
要建立键值对应,可以使用put()方法,第一个自变量是键,第二个自变量是值
-
对于 Map 而言,键不会重复,判断键是否重复是根据 hashCode() 与 equals(),所以作为键的对象必须操作 hashCode() 与 equals()。若要指定键取回对应的值,则使用 get() 方法
-
如果想要键是有序的,可以使用 TreeMap。如果使用 TreeMap 建立键值对应,则键的部分将会排序,条件是作为键的对象必须操作 Comparable 接口,或者是在创建TreeMap时指定操作Comparator接口的对象
-
Properties类继承自Hashtable,HashTable操作了Map接口,Properties自然也有Map的行为。虽然也可以使用put()设定键值对应、get()方法指定键取回值,不过一般常用Properties的setProperty()指定字符串类型的键值,getProperty()指定字符串类型的键,取回字符串类型的值,通常称为属性名称与属性值。
-
可以使用Properties的load()方法指定InputStream的实例
-
如果想取得Map中所有的键,可以调用Map的keySet()返回Set对象。由于键是不重复的,所以用Set操作返回是理所当然的做法,如果想取得Map中所有的值,则可以使用values()返回Collection对象。
-
如果想同时取得Map的键与值,可以使用entrySet()方法,这会返回一个Set对象,每个元素都是Map.Entry实例。可以调用getKey()取得键,调用getValue()取得值。
教材学习中的问题和解决过程
- 教材P233代码while一行()内代码含义
static int nextInt() {
String input = console.next();
while(!input.matches("\d*")) {
System.out.println("请输入数字");
input = console.next();
}
return Integer.parseInt(input);
}
- 之后教材有提到,得知"d*"是规则表示式
代码调试中的问题和解决过程

- 要在代码开头添加
import java.util.*;
代码托管
-
代码提交过程截图:
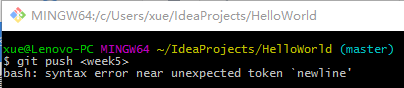
遇到该问题还没有解决- 运行 git log --pretty=format:"%h - %an, %cd : %s" 并截图
-
代码量截图:

- 运行 find src -name "*.java" | xargs cat | grep -v ^$ | wc -l 并截图
上周考试错题总结
- CH06判断:可以用父类声明对象引用,用子类生成对象,但需要强制类型转换。(X)
- CH06填空:写出编译P165 RPG.java的命令(javac –d . *.java)
结对及互评
评分标准(满分10分)
-
从0分加到10分为止
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
6 其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
7 扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
点评模板:
-
基于评分标准,我给本博客打分:10。得分情况如下:
-
正确使用Markdown语法 + 1
-
模板中的要素齐全 + 1
-
教材学习中的问题和解决过程 + 1
-
代码调试中的问题和解决过程 + 1
-
本周有效代码超过300分行的 + 2
-
体会感想 + 1
-
进度条 + 1
-
commit message 规范 +1
-
排版精美 +1
点评过的同学博客和代码
其他(感悟、思考等,可选)
在本周的学习中,我反而在学习的过程中觉得自己有很多不会的地方,一方面可能是因为本周的学习内容相对比较难比较生疏,另一方面,我觉得也是因为我思考的多了,对代码想要了解的更加深入一点,对于出现的错误想要尽可能的解决。所以我觉得本周我对于代码的学习反而没有上周感觉的那么顺畅。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 2/2 | 20/20 | |
| 第二周 | 186/186 | 2/4 | 18/38 | |
| 第三周 | 689/875 | 3/7 | 22/60 | |
| 第四周 | 242/1117 | 2/9 | 30/90 | |
| 第五周 | 698/1815 | 2/9 | 30/120 |
-
计划学习时间:30小时
-
实际学习时间:24小时