关于线性回归的介绍可以看这里:线性回归介绍
下文主要介绍通过线性回归解决Kaggle中的HousePrices问题,使用的是PyTorch。
下文会给出使用线性回归创建的最终模型,以及超参数等内容,但是整个模型的搭建以及试错的过程由于内容太长,感兴趣
的可以去作者的GitHub下载相关的Jupyter notebook文件,训练数据和测试数据也可以从上面下载。
相关库:
import numpy as np # linear algebra import pandas as pd from pandas import DataFrame import matplotlib.pyplot as plt import torch import torch.nn as nn
模型:
class Net(nn.Module): def __init__(self, D_in, H1, H2, H3, D_out): # D_in, H1, H2, H3, D_out -- 输入维度 第一层输出维度 第二层输出维度 第三层输出维度 最终输出维度 super(Net, self).__init__() self.linear1 = nn.Linear(D_in, H1) self.linear2 = nn.Linear(H1, H2) self.linear3 = nn.Linear(H2, H3) self.linear4 = nn.Linear(H3, D_out) def forward(self, x): # torch.clamp() 将张量的每个元素范围限制到一个(min, max) y = self.linear1(x).clamp(min=0) y = self.linear2(y).clamp(min=0) y = self.linear3(y).clamp(min=0) y = self.linear4(y) return y
解决这个问题最重要的不是模型结构而是对训练数据的处理,这里选择的是将训练数据中非数值数据映射为int值,并且将
每一列数据减去均值后再除以最大值和最小值的差值,也可以通过减去均值除以标准差的方式,不过本文采用的是前者,
感兴趣的读者可以自己实现。
数据的导入和处理:
raw_data = pd.read_csv('./data/kaggle_house/train.csv') # 数值数据的列 numeric_colmuns = [] numeric_colmuns.extend(list(raw_data.dtypes[raw_data.dtypes == np.int64].index)) numeric_colmuns.extend(list(raw_data.dtypes[raw_data.dtypes == np.float64].index)) # 将SalePrice放在最后一列 numeric_colmuns.remove('SalePrice') numeric_colmuns.append('SalePrice') # 去除Id这一列 numeric_colmuns.remove('Id') numeric_data = DataFrame(raw_data, columns=numeric_colmuns) # 缺省值补0 # pd.fillna(n)填充缺失数据 numeric_data['LotFrontage'] = numeric_data['LotFrontage'].fillna(0) numeric_data['MasVnrArea'] = numeric_data['MasVnrArea'].fillna(0) numeric_data['GarageYrBlt'] = numeric_data['GarageYrBlt'].fillna(0) # 均值 最大值 最小值 means, maxs, mins = dict(), dict(), dict() for col in numeric_data: means[col] = numeric_data[col].mean() maxs[col] = numeric_data[col].max() mins[col] = numeric_data[col].min() numeric_data = (numeric_data - numeric_data.mean()) / (numeric_data.max() - numeric_data.min()) # 将原始数据中非数值数据的列找出来 non_numeric_columns = [col for col in list(raw_data.columns) if col not in numeric_colmuns] non_numeric_columns.remove('Id') # 非数值数据 non_numeric_data = DataFrame(raw_data, columns=non_numeric_columns) nan_columns = np.any(pd.isna(non_numeric_data), axis=0) nan_columns = list(nan_columns[nan_columns == True].index) # 将缺失值作为 'N/A' for col in nan_columns: non_numeric_data[col] = non_numeric_data[col].fillna('N/A') # 用映射表把字符串转为int mapping_table = dict() for col in non_numeric_columns: curr_mapping_table = dict() unique_values = pd.unique(non_numeric_data[col]) print(unique_values) for inx, v in enumerate(unique_values): curr_mapping_table[v] = inx + 1 non_numeric_data[col] = non_numeric_data[col].replace(v, inx + 1) mapping_table[col] = curr_mapping_table # 归一化 for col in non_numeric_data: means[col] = non_numeric_data[col].mean() maxs[col] = non_numeric_data[col].max() mins[col] = non_numeric_data[col].min() for col in non_numeric_data: non_numeric_data[col] = (non_numeric_data[col] - means[col]) / (maxs[col] - mins[col]) non_numeric_x_df = DataFrame(non_numeric_data, columns=non_numeric_columns) non_numeric_y_df = DataFrame(numeric_y_df) # 用上所有数据 x_df = DataFrame(numeric_x_df, columns=numeric_x_columns) y_df = DataFrame(numeric_y_df) # 将非数值数据的那些列拼接上去 # x_df = pd.concat([numeric_x_df, non_numeric_x_df], axis=1) # 可以下面的循环语句 也可以用上面的那条语句 pd.concat() for col in non_numeric_columns: x_df[col] = non_numeric_x_df[col] x = torch.tensor(x_df.values, dtype=torch.float) y = torch.tensor(y_df.values, dtype=torch.float)
超参数:
D_in, D_out = x.shape[1], y.shape[1] model6 = Net(D_in, H1, H2, H3, D_out) optimizer = torch.optim.Adam(model6.parameters(), lr=1e-4 * 2)
模型训练:
losses6 = [] for t in range(500): y_pred = model6(x) loss = criterion(y_pred, y) if (t + 1) % 10 == 0: print(t, loss.item()) losses6.append(loss.item()) if torch.isnan(loss): break optimizer.zero_grad() loss.backward() optimizer.step()
下面损失值变化:
9 6.942687511444092 19 4.153867721557617 29 2.8861405849456787 39 2.1543002128601074 49 1.6814405918121338 59 1.2690644264221191 69 0.9127545356750488 79 0.6374701857566833 89 0.44278401136398315 99 0.3076871335506439 109 0.21465598046779633 119 0.15101489424705505 129 0.11797764152288437 139 0.0813324898481369 149 0.06239088624715805 159 0.0478670597076416 169 0.037706196308135986 179 0.029238209128379822 189 0.025697028264403343 199 0.018969601020216942 209 0.015594517812132835 219 0.013458245433866978 229 0.010695122182369232 239 0.009573224931955338 249 0.01129293255507946 259 0.008044157177209854 269 0.008845468983054161 279 0.00610680878162384 289 0.0053095207549631596 299 0.007215226534754038 309 0.002987970830872655 319 0.009104212746024132 329 0.01189067866653204 339 0.0026393337175250053 349 0.002604425884783268 359 0.0021756708156317472 369 0.001827285042963922 379 0.0014763239305466413 389 0.0014955512015148997 399 0.00858624093234539 409 0.002981389407068491 419 0.004797589499503374 429 0.0007704143645241857 439 0.0008664355846121907 449 0.0006161347846500576 459 0.0010636755032464862 469 0.004391425289213657 479 0.008840898983180523 489 0.00047967140562832355 499 0.0010821424657478929
除了上述使用所有数据训练的模型,作者还比较了仅使用数值数据训练模型和仅使用非数值数据训练的模型:
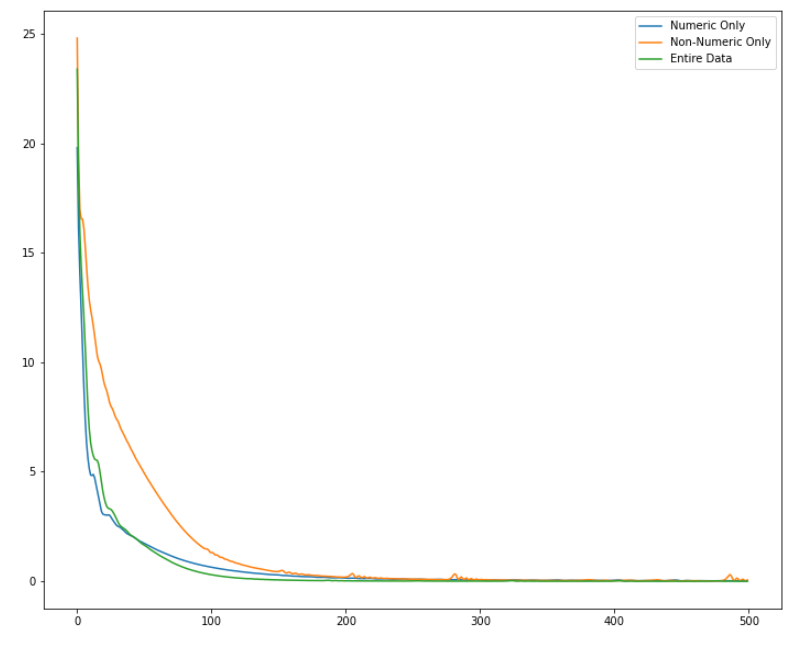
上面是这三种训练方式的模型损失值变化曲线。