爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
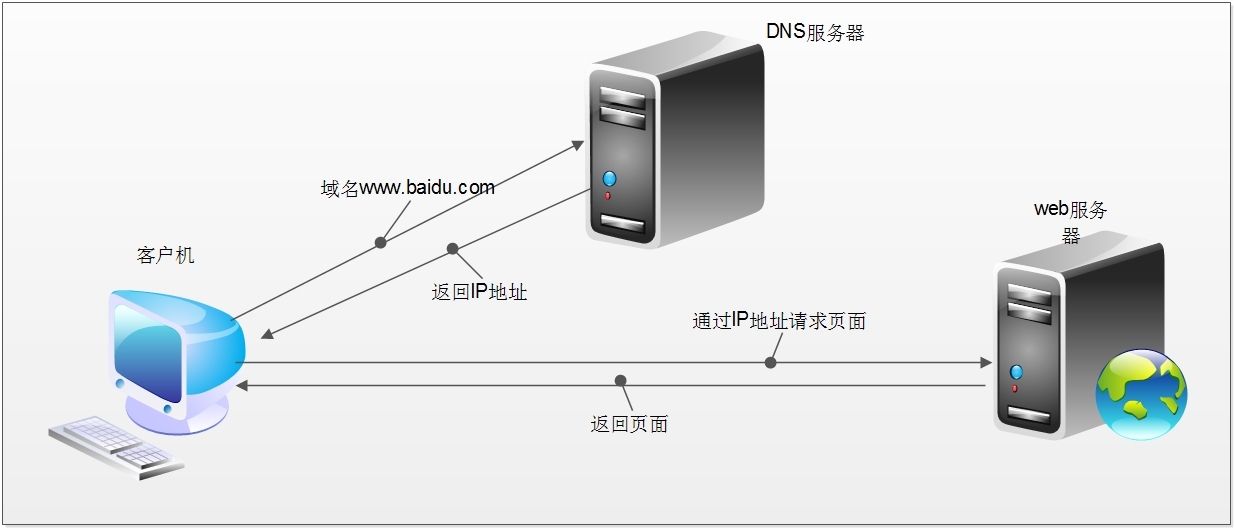
简单来说这段过程发生了以下四个步骤:
-
查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址
-
向IP对应的服务器发送请求。
-
服务器响应请求,发回网页内容。
-
浏览器显示网页内容。
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
浏览器是如何发送和接收这个数据呢?
HTTP协议(HyperText Transfer Protocol,超文本传输协议)目的是为了提供一种发布和接收
HTML(HyperText Markup Language)页面的方法。
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。