数据集参考自https://blog.csdn.net/c406495762/article/details/77341116
朴素贝叶斯:首先,何为朴素?朴素要求的是条件特征之间相互独立。我们都知道大名鼎鼎的贝叶斯公式,其实朴素贝叶斯的思想很简单。就是通过计算属于某一类别的后验概率,然后比较大小,哪一类的概率大,那么就将它划分为哪一类。。。
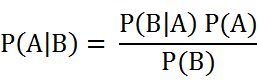
由上述公式可知,我们先验概率P(A)很容易求得,我们重点在与求条件概率。由于条件特征之间相互独立,于是可以拆分成累乘的形式。在代码实现中,我们一般不会去求P(B),因为分母都是一样的,我们只关注类别概率的大小!
将代码记录如下,方便以后查看。
import numpy as np import pandas as pd def getDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] labels = [0,1,0,1,0,1] return postingList,labels #创建词汇表 def createVocabList(dataSet): vocabSet = set([]) for data in dataSet: vocabSet = vocabSet | set(data) return list(vocabSet) #向量化 def vectorize(vocabSet,dataSet): vocab = [0] * len(vocabSet) for data in dataSet: vocab[vocabSet.index(data)] = 1 return vocab #朴素贝叶斯建模 def trainN(X_train,y_train): num = len(X_train) #有多少记录 numvocab = len(X_train[0]) #词向量的大小 p0Num = np.ones(numvocab) #统计非侮辱类的相关单词频数 加入了拉普拉斯平滑 p1Num = np.ones(numvocab) #统计侮辱类的相关单词频数 p0Sum = 2 p1Sum = 2 pA = sum(y_train) / num #先验概率 for i in range(num): if y_train[i]==0: #统计属于非侮辱类的条件概率所需的数据 p0Sum += sum(X_train[i]) p0Num += X_train[i] else: #统计属于侮辱类的条件概率所需的数据 p1Sum += sum(X_train[i]) p1Num += X_train[i] # 为了防止下溢出,计算条件概率的对数 p0 = np.log(p0Num / p0Sum) #频数除以总数 得到概率 p1 = np.log(p1Num / p1Sum) return p0,p1,pA #分类 def classify(testMat,p0,p1,pA): p0Score = sum(testMat * p0) + np.log(pA) p1Score = sum(testMat * p1) + np.log(1-pA) if p0Score > p1Score: return 0 else: return 1 if __name__=='__main__': dataSet,label = getDataSet() vocabSet = createVocabList(dataSet) trainMat = [] for elem in dataSet: trainMat.append(vectorize(vocabSet,elem)) # print(trainMat) p0,p1,pA = trainN(trainMat,label) test1= ['love', 'my', 'dalmation'] test2= ['stupid', 'garbage'] test1_vocab = np.array(vectorize(vocabSet,test1)) test2_vocab = np.array(vectorize(vocabSet,test2)) result1 = classify(test1_vocab,p0,p1,pA) result2 = classify(test2_vocab,p0,p1,pA) if result1==1: print(test1,"属于:侮辱类") else: print(test1, "属于:非侮辱类") print("=======================================") if result2==1: print(test2,"属于:侮辱类") else: print(test2, "属于:非侮辱类")
结果如下:
['love', 'my', 'dalmation'] 属于:非侮辱类
=======================================
['stupid', 'garbage'] 属于:侮辱类