其实,激发起写博客冲动的是帝国时代2高清版的上市,最近在重温这款经典游戏使得我很想整理一下帝国里兵种相克关系与那些帝国的真实历史。不过,这个博客的初衷始终是技术博客,所以先压一压欲望,把之前欠的文章先发一发吧: 毕业论文我选择的主题是《基于数据挖掘的NBA球队建队方案研究》,期间我将basketballreference和82games两个NBA数据网站的数据抓取到本地的数据库中进行研究;使用了scikit-learen库对球队数据进行基本的数据挖掘(聚类与分类);贯穿始末的则是django框架:model用于数据持久化,view用于操作数据,template用于展示结果(借助了google chart)。以上的工作都是基于python的,也可以看出python的强大了吧。接下来我会以一个系列的形式讲解整个过程是如何实现的,本文是系列的第一篇:数据抓取与持久化。
说到python的数据抓取就不得不提BeautifulSoup,它提供了强大的html文档遍历、查询、筛选功能,稍微现代一点的网站(有清晰的css)都可以轻松地抓取到想要的内容,而对于古老的网站可能要用正则表达式来直接筛选内容。此外,django虽然是一个web开发框架,但由于它方便的数据库操作api(避免再去学sql)我决定使用它在本地环境下做数据的持久化以及之后的数据操作和展示。这里就不介绍django的入门了,感兴趣的同学可以去看官网的教学。"Let’s learn by example."是django教学的第一句话也是我认为学习编程最好的方法,于是现在我们直接以basketball-reference为例开始上代码! 首先,明确这个例子的任务是从bbr(basketball-reference的简称)上抓取所有现役球员的基本信息,包括:姓名、球龄、身高、体重。 第二,在django的model中建立数据表:
class Player(models.Model): name = models.CharField(max_length=100, verbose_name="姓名") exp = models.IntegerField(verbose_name="球龄") height = models.CharField(max_length=10, verbose_name="身高") weight = models.CharField(max_length=10, verbose_name="体重") def __unicode__(self): return self.name
第三,要抓取所有现役球员的信息,首先要获得所有球员页面的链接,找到bbr球员列表页,进行网站结构分析: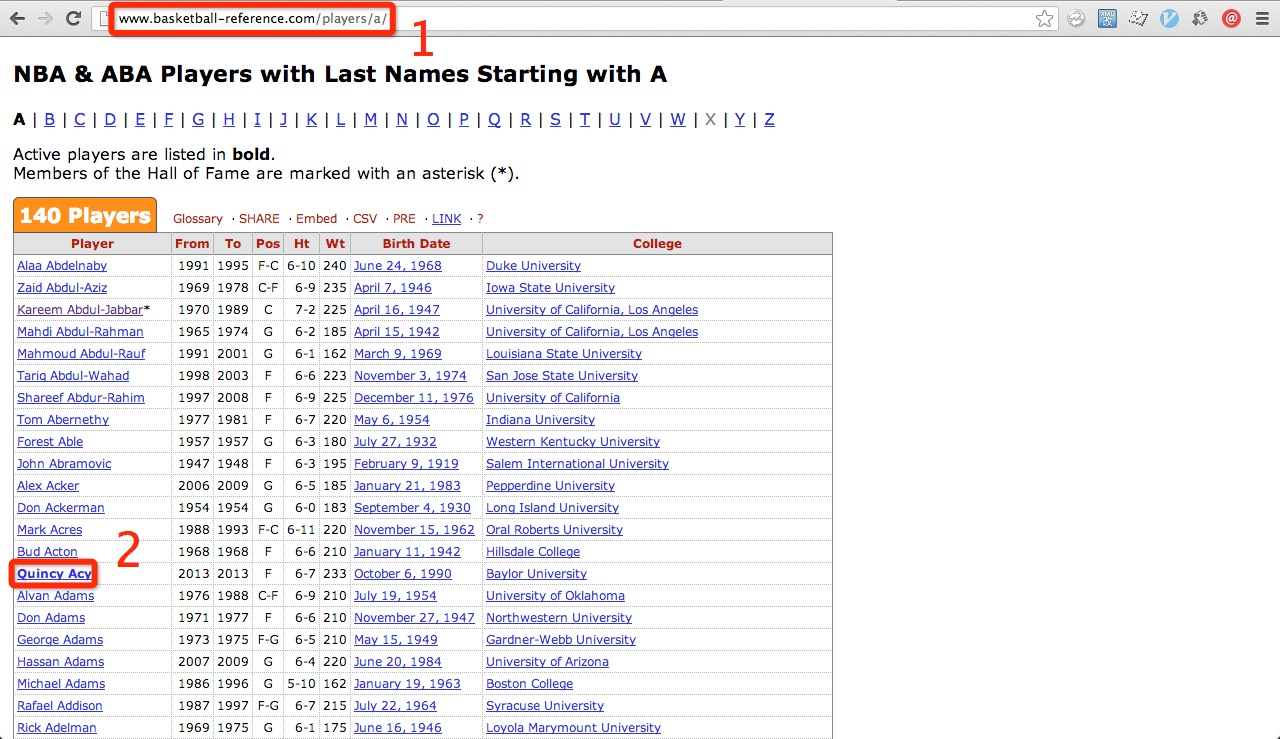
可以得出,1.列表链接的形式为/players/a/, /players/b/, /players/c/等等;2.现役球员的名字是有加粗的。于是通过一个函数获得所有现役球员的链接:
def playerUrl(url):
soup = BeautifulSoup(urllib.urlopen(url))
players = soup.find(id='players').contents[5].find_all('tr')
active = []
for tr in players:
td = tr.find_all('td')[0]
if td.find('strong'):
active.append(td.find('a')['href'])
return active
然后和抓取链接一样先分析再抓取的方式,从球员页面中(例如雷阿伦)抓取姓名、球龄、身高、体重四个信息并放入数据库中:
def playerData(player_url):
url = 'http://www.basketball-reference.com' + player_url
soup = BeautifulSoup(urllib.urlopen(url))
# player info
playerdic = {
'name' : soup.find('h1').string,
'exp' : '',
'height' : '',
'weight' : '',
}
spans = soup.find(id="info_box").find_all('span', 'bold_text')
for span in spans:
if span.string == 'Height:':
playerdic['height'] = span.next_sibling[1:-3]
if span.string == 'Weight:':
playerdic['weight'] = span.next_sibling[1:8]
if span.string == 'Experience:':
s = span.next_sibling[1:]
playerdic['exp'] = int(s.split(' ')[0])
# into db
player = Player.objects.create(**playerdic)
最后,在django的view中调用函数,在本地打开view对应的网页进行抓取:
from bs4 import BeautifulSoup
import urllib
from django.http import HttpResponse
from mining.models import Player
from string import lowercase
def gainBbrData(request):
abc = lowercase[:23]
abc = ''.join([abc, lowercase[24:]]) # NBA没有X开头的人名
player_urls = []
for s in abc:
url = 'http://www.basketball-reference.com/players/'+ s +'/'
player_urls.extend(playerUrl(url))
for url in player_urls:
playerData(url)
return HttpResponse('gained')
结果: 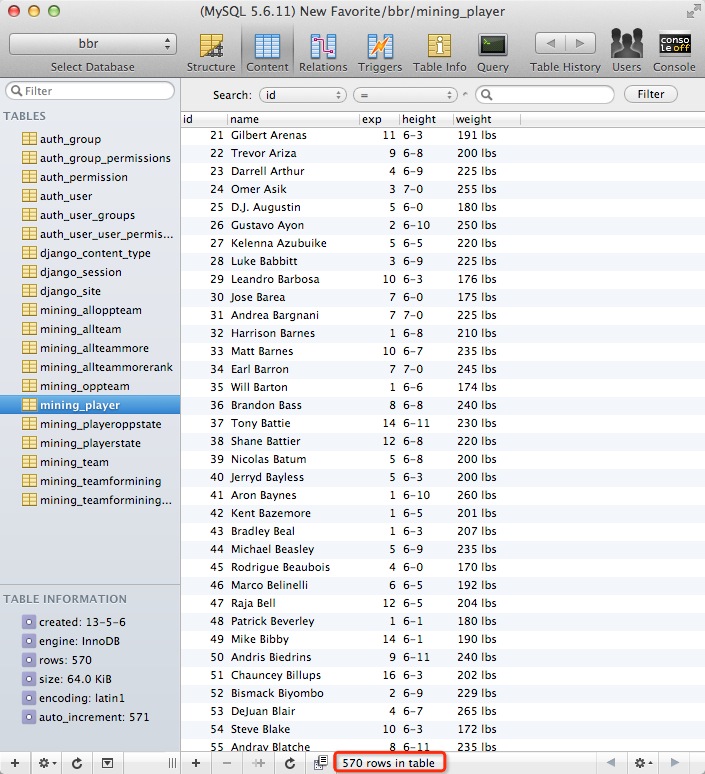
看来现役有570名球员。 这个实例就到此为止。为了做论文,我还抓取了其他一大批数据,包括球队数据,球员的具体的比赛数据,还有球员的对位对手的比赛数据等等。方法都是类似的只不过如果网速不好(比如厦门大学的图书馆)会很花时间就是了。系列的第一篇就到此为止,最后补充一句:从别人那里抓数据最好不要用于商业。
——谢绝剽窃,转载请注明出处并加上链接!