作业文件:
1. 神经网络
在之前的练习中,我们已经实现了神经网络的前反馈传播算法,并且使用这个算法通过作业给的参数值预测了手写体数字。这个练习中,我们将实现反响传播算法来学习神经网络的参数。
1.1 可视化数据
这一节的代码将会加载数据,并且以二维的格式展现出来。运行代码会将训练集加载到变量X与y中。

load('ex4data1.mat'); m = size(X, 1); % Randomly select 100 data points to display sel = randperm(size(X, 1)); sel = sel(1:100); displayData(X(sel, :));
在ex4data1.mat中有5000个训练样本,每个样本是有关数字的20*20的像素的灰度图像。每个像素代表灰度相应位置的灰度强度。这20*20的灰度被展开成1*400的向量。每个训练样本变成了单独的一行,在我们的X矩阵中。所以训练集为一个5000*400的矩阵,其中每一行表示一个手写体数字图。

训练集的第二部分是一个5000*1的向量y,代表这个训练集的标签。为了更适应MATLAB没有0号的索引的情况,我们用标签10代表手写体数字0。 标签1-9表示手写体数字1-9。
1.2 模型表示
图尔表示我们的神经网络。包含三层,一个输入层,一个隐藏层和一个输出层。我们的输入为手写体数字图的像素,因为图的大小为20*20,所以输入层有400个单元,(不包括额外的偏置单元)
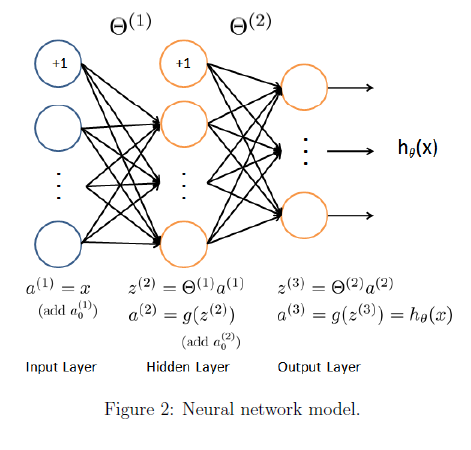
作业已经提供了训练好的网络的参数,theta1,theta2。存储在 ex4weights.mat中,运行下面的代码加载theta1与theta2。参数维度的大小与每层的神经元的个数有关。
% Load the weights into variables Theta1 and Theta2 load('ex4weights.mat');
1.3 前反馈与代价函数
我们现在将会实现神经网络的代价函数与梯度。首先,在nnCostFunction.m文件中完成代码返回代价值。回忆神经网络的代价函数(没有正则化)是:
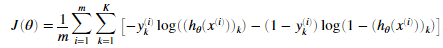
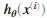 的计算如图二所示,K=10表示可能的标签的数目。注意
的计算如图二所示,K=10表示可能的标签的数目。注意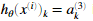 是第K个输出单元的激活值(输出值)。想起原始标签(在变量y中)是1-10。为了训练神经网络,我们需要将y设置只包含0或1的情况,像这样。
是第K个输出单元的激活值(输出值)。想起原始标签(在变量y中)是1-10。为了训练神经网络,我们需要将y设置只包含0或1的情况,像这样。
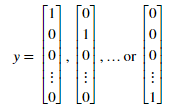
举个例子,如果xi是数字5的图像,因此对应的yi(我们使用代价函数计算的值)应该为一个10维的向量,其中y5=1其他的元素值为0。我们应该实现前反馈传然后计算每个样本i的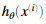 ,并且将所有的代价值加在一起。我们的代码应该适应任意大小的数据集,有任意数量的标签(我们可以假定至少有三个以上的标签。
,并且将所有的代价值加在一起。我们的代码应该适应任意大小的数据集,有任意数量的标签(我们可以假定至少有三个以上的标签。
实现说明:矩阵X包含的每个样本在每一行中。比如(X(i,:))是第i个训练样本。当我们在nnCostFunction.m中实现代码的时候。我们应该为X添加一列1。神经网络的每个参数以行的形式在Theta1与Theta2中表示。具体来说,Theta1的第一行表示第二层的第一个隐藏单元。我们可以使用循环遍历每个样本来计算代价。推荐第一次实现前反馈传播不要使用正则化。这样会容易调试。只有我们将会实现正则化代价函数。
如果我们完成了代码,调用 nnCostFunction使用已经给好的Theta1与Theta2我们应该看到代价值应该为 0.287629
nnCostFunction.m文件中填写代码:
X = [ones(m,1),X];
for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); J = J+(1/m)*(-y1*log(a3)-(1-y1)*log(1-a3)); end end
疑问,第一次填写的代码为下面部分,本地测试没问题,提交作业提示 c(i,:) = (1:10)维度问题不能赋值。
X = [ones(m,1),X]; z2 = X*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [ones(m,1),a2]; z3 = a2*Theta2'; a3 = 1./(1+exp(-z3)); c = zeros(size(a3)); for i = 1:m c(i,:) = (1:10); c(i,:) = c(i,:)==y(i); end J = (-c.*log(a3)-(1-c).*log(1-a3)); J = (1/m)*sum(J(:));
运行下面代码,结果输出 0.287629
input_layer_size = 400; % 20x20 Input Images of Digits hidden_layer_size = 25; % 25 hidden units num_labels = 10; % 10 labels, from 1 to 10 (note that we have mapped "0" to label 10) % Unroll parameters nn_params = [Theta1(:) ; Theta2(:)]; % Weight regularization parameter (we set this to 0 here). lambda = 0; J = nnCostFunction(nn_params, input_layer_size, hidden_layer_size, num_labels, X, y, lambda); fprintf('Cost at parameters (loaded from ex4weights): %f', J);
1.4 正则化代价函数
神经网络的正则化的代价函数为:
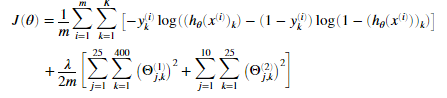
我们可以假定神经网络只有三层,一个输入层,一个隐藏层,和一个输出层。然而我们的代码应该对于任意的输入单元,隐藏单元,和输出单元都适应。虽然我们已经具体指明了Theta1与Theta2。
注意我们不应该正则化偏执单元参数。对于矩阵Theta1和Theta2来说。不应该正则化这两个矩阵的第一列。我们现在应该为我们的代价函数添加正则化。我们已经在 nnCostFunction.m完成了非正则化的代价函数,因此可以在此文件中直接添加正则化项。我们完成后,运行下面代码,使用已经给定的参数Thtea1与Theta2,与lambda=1.我们应该看待代价值为0.383770
添加正则化项后,nnCostFunction.m中的代码为:
for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); J = J+(1/m)*(-y1*log(a3)-(1-y1)*log(1-a3)); end end J1 = Theta1(:,2:end).^2; J2 = Theta2(:,2:end).^2; J = J+lambda/(2*m)*(sum(J1(:))+sum(J2(:)));
运行下面代码我们看到结果为 0.383770
% Weight regularization parameter (we set this to 1 here). lambda = 1; J = nnCostFunction(nn_params, input_layer_size, hidden_layer_size, num_labels, X, y, lambda); fprintf('Cost at parameters (loaded from ex4weights): %f', J);
2. 反向传播
在这一节我们将会实现通过反向传播算法来计算神经网络的代价函数的梯度。我们应该在 nnCostFunction.m文件中完成代码,返回梯度的正确值。一旦我们完成梯度。我们就可以高级优化器如fmicg来最小化代价函数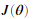 训练神经网络。
训练神经网络。
我们首先实现反向传播算法计算未正则化的神经网络的参数的梯度。在验证我们计算的未正则化的梯度是正确的之后,我们将会实现正则化的神经网络的梯度。
2.1 sigmoid 梯度
为了帮助我方开始本节的计算,我们将会首先实现sigmoid梯度函数,sigmoid函数的梯度可以通过下面式子计算。
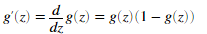
其中
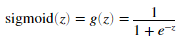
当我们完成代码后,试着通过调用sigmoidGradient(z)来测试一些数。对于大的数(无论是正的还是负的),梯度的值应该接近0,当z=0的时候,梯度值应该是0.25。我们的代码应该对无论是矩阵还是向量,都应该起作用。对于矩阵,我们的函数应该对每一个元素都执行。
sigmoidGradient.m中填写代码
g = sigmoid(z).*(1-sigmoid(z));
2.2 随机初始化
当我们训练神经网络的时候,进行随机初始化来来打破对称性是非常有必要的。
为什么要打破对称性,可以参考知乎用户回答:
为什么神经网络在考虑梯度下降的时候,网络参数的初始值不能设定为全0,而是要采用随机初始化思想? - koala tree的回答 - 知乎 https://www.zhihu.com/question/36068411/answer/95670563
还有个回答是:
设想你在爬山,但身处直线形的山谷中,两边是对称的山峰。
由于对称性,你所在之处的梯度只能沿着山谷的方向,不会指向山峰;你走了一步之后,情况依然不变。
结果就是你只能收敛到山谷中的一个极大值,而走不到山峰上去。
这个回答暂时不理解先存疑。
进行随机初始化参数一个很有效的方法是随机选择theta的值均匀分布在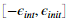 中。我们应该使用
中。我们应该使用 。这个范围的值保证了参数值是小的,并且是学习更有效率。
。这个范围的值保证了参数值是小的,并且是学习更有效率。
我们的任务是完成randInitializeWeights.m文件,来可以初始化权重theta。将下面代码粘贴到文件中。
% Randomly initialize the weights to small values epsilon_init = 0.12; W = rand(L out, 1 + L in) * 2 * epsilon_init - epsilon init;
当我们完成时,运行下面代码来调用randInitialWeights来初始化神经网络参数。
initial_Theta1 = randInitializeWeights(input_layer_size, hidden_layer_size); initial_Theta2 = randInitializeWeights(hidden_layer_size, num_labels); % Unroll parameters initial_nn_params = [initial_Theta1(:) ; initial_Theta2(:)];
一个有效的策略选择 是基于网络神经元的个数。
是基于网络神经元的个数。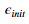 的一个好的选择是
的一个好的选择是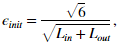
其中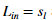 ,
,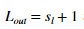 是与
是与 相邻的层的神经元的个数。
相邻的层的神经元的个数。
2.3 反向传播
现在我们将会实现反向传播算法。想起反向传播算法的只管理解如下。给定一个训练样本,我们首先需要执行向前传播来计算神经网络的所有激活值。包括假设函数 的输出值。之后对于每一层l的每个节点j。我们一般计算一个“误差项”
的输出值。之后对于每一层l的每个节点j。我们一般计算一个“误差项” ,来衡量一个节点值对输出的所有错误的影响程度。
,来衡量一个节点值对输出的所有错误的影响程度。
对于输出节点,我们可以直接计算网络的激活值与真实目标值的差值。并且定义为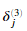 ,因为第3层就是输出层。对于隐藏层,我们计算的
,因为第3层就是输出层。对于隐藏层,我们计算的 是第l+1层的节点误差项的加权平均值。
是第l+1层的节点误差项的加权平均值。
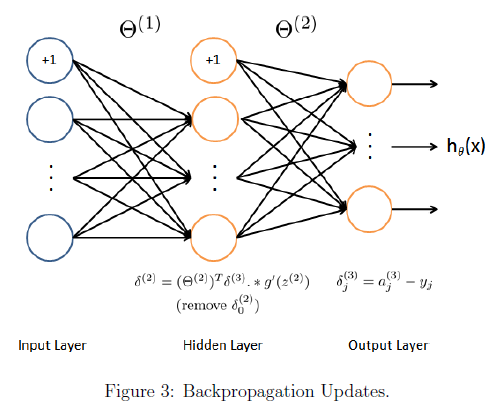
具体来说,下面是反向传播算法(也如图3所示)。我们应该在一个循环中实现第1-4步来一次出处理一个样本。具体来说,我们应该实现对于一个循环 for t = 1:m,步骤1-4在带这个循环内。对于第i次迭代执行的是处理第i个训练样本(xi,yi)。第5步是用m除累加的梯度值,来获得此神经网络价值函数的梯度值。
- 将输入层的值设定为第i个训练样本xi的值。执行前馈传播(图2),计算第2,3层激活值(z2,a2,z3,a3)。注意我们应该对a+1项,来确保a1,a2激活的向量包括偏置单元。在MATLAB中,如果a_1是一个列向量,为a_1添加对应的1是a_1=[1:a_1]
- 对于第3层的每个输出单元k,令
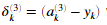 ,其中
,其中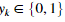 。表示是否当前的训练样本属于类k(yk=1),或者是否属于其他类(yk=0)。逻辑数组对我们的解决这个问题很有帮助。
。表示是否当前的训练样本属于类k(yk=1),或者是否属于其他类(yk=0)。逻辑数组对我们的解决这个问题很有帮助。 -
对于隐藏层l=2,令
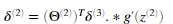
-
对每个样本累加梯度值通过下面这个式子:
 ,注意我们应该跳过或者移除
,注意我们应该跳过或者移除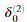 。在MATLAB中移除
。在MATLAB中移除 对应delta_2 = delta_2(2:end)。
对应delta_2 = delta_2(2:end)。 -
或者神经网络代价函数(未正则化)梯度值通过,用m除累加的梯度。

当实现反向传播算法时候,如果出现维度不匹配情况,使用size函数来打印矢量大小是非常有帮助的。
当我们实现反向传播算法,下一节的代码将会执行梯度检测,梯度检测会使我们对自己写的梯度代码有信心。
在nnCostFunction.m文件中添加梯度后:
X = [ones(m,1),X]; Delta1 = zeros(size(Theta1)); Delta2 = zeros(size(Theta2)); for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); J = J+(1/m)*(-y1*log(a3)-(1-y1)*log(1-a3)); end end J1 = Theta1(:,2:end).^2; J2 = Theta2(:,2:end).^2; J = J+lambda/(2*m)*(sum(J1(:))+sum(J2(:))); for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); delta3(j) = a3-y1; end delta2 = (delta3*Theta2(:,2:end)).*sigmoidGradient(z2); Delta1 = Delta1+delta2'*x; Delta2 = Delta2+delta3'*a2; end Theta1_grad = 1/m*Delta1; Theta2_grad = 1/m*Delta2;
2.4 梯度检测
在我们的神经网络中,我们最小化代价函数 为了执行梯度检测,我们想象可以把参数Theta1与Theta2展开成一个长向量
为了执行梯度检测,我们想象可以把参数Theta1与Theta2展开成一个长向量 。通过这样做。我们可以认为代价函数是
。通过这样做。我们可以认为代价函数是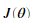 ,并使用它来执行梯度检测。
,并使用它来执行梯度检测。
加入我们有一个函数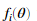 据称可以计算
据称可以计算 ,我们想验证是否
,我们想验证是否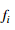 输出了正确的偏导数。
输出了正确的偏导数。

我们可以验证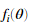 函数的正确性,对于每一个i
函数的正确性,对于每一个i
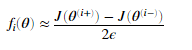
我们已经在computeNumericalGradient.m实现了这个方法来计算数值梯度。我们不需要修改这个文件,但是作业鼓励我们看看这个代码,来了解他是怎么工作的。
运行下面代码,将会创建一个小型的神经网络和数据集,来检测我们的梯度。如果我们的梯度值是正确的我们应该会看到相对差距应该小于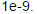
当执行梯度检测的时候,使用有数量相对少的输入单元与隐藏单元的神经网络是更有效率的。因为有更少的参数。Theta的每个维度都需要计算两次代价函数,成本很好。在checkNNGradients,方法中,我们的代码创建了一个小的随机模型和数据集,在computeNumericalGradient中来进行梯度检测。当我们确定我们的梯度计算是正确的之后,我们应该在学习算法中关掉梯度检测。
梯度检测对任意的我们计算的代价与梯度都使用。具体来说我们可以使用相同的computeNumericalGradient.m函数来检测是否我们在其他章节实现的梯度是不是正确的。
2.5 正则化神经网络
在我们完成反向传播算法后,我们将会为我们的梯度加上正则化。可以证明我们可以为使用反向传播计算梯度的时候我们可以加上额外项。
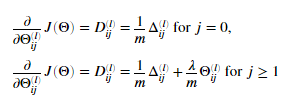
需注意我们不行该正则化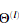 的第一列。现在修改 nnCostFunction.m中的代码,考虑正则化。运行下面代码。如果我们的代码正确。我们应该看到相对差距应该小于1e-9
的第一列。现在修改 nnCostFunction.m中的代码,考虑正则化。运行下面代码。如果我们的代码正确。我们应该看到相对差距应该小于1e-9
nnCostFunction.m中的代码:
X = [ones(m,1),X]; Delta1 = zeros(size(Theta1)); Delta2 = zeros(size(Theta2)); for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); J = J+(1/m)*(-y1*log(a3)-(1-y1)*log(1-a3)); end end J1 = Theta1(:,2:end).^2; J2 = Theta2(:,2:end).^2; J = J+lambda/(2*m)*(sum(J1(:))+sum(J2(:))); for i = 1:m x = X(i,:); for j = 1:num_labels y1 = y(i)==j; z2 = x*Theta1'; a2 = 1./(1+exp(-z2)); a2 = [1,a2]; z3 = a2*Theta2(j,:)'; a3 = 1./(1+exp(-z3)); delta3(j) = a3-y1; end delta2 = (delta3*Theta2(:,2:end)).*sigmoidGradient(z2); Delta1 = Delta1+delta2'*x; Delta2 = Delta2+delta3'*a2; end Theta1_grad = 1/m*Delta1; Theta2_grad = 1/m*Delta2; Theta1_grad(:,2:end) = Theta1_grad(:,2:end)+lambda/m*Theta1(:,2:end); Theta2_grad(:,2:end) = Theta2_grad(:,2:end)+lambda/m*Theta2(:,2:end);
2.6 使用fmincg学习参数
上面任务都完成后,运行下面代码使用fmincg来学习一组好的参数。当训练完成后。代码将会告诉我们分类器的精度。如果我们之前做的都正确的话,我们应该看到训练精度应该为95.3%。可能因为随机初始化的原因变化1%。如果迭代更多次的话,可能会获得更高的精度。
options = optimset('MaxIter', 50); lambda = 1; % Create "short hand" for the cost function to be minimized costFunction = @(p) nnCostFunction(p, input_layer_size, hidden_layer_size, num_labels, X, y, lambda); % Now, costFunction is a function that takes in only one argument (the % neural network parameters) [nn_params, ~] = fmincg(costFunction, initial_nn_params, options); % Obtain Theta1 and Theta2 back from nn_params Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), hidden_layer_size, (input_layer_size + 1)); Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), num_labels, (hidden_layer_size + 1)); pred = predict(Theta1, Theta2, X); fprintf(' Training Set Accuracy: %f ', mean(double(pred == y)) * 100);
3. 可视化隐藏层
理解我们神经网络学习的内容一种方法是可视化我们的隐藏层捕获到了什么。一般来说。给定一个隐藏层单元,可视化其计算内容的一种方法是找到将导致其激活的输入x。(也就是说计算的激活值接近1)。对于我们训练到的神经网络来说。注意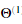 的第i行是一个401维的向量,代表第i个隐藏层的参数。如果我们不考虑偏置项,我们可以得到一个1*400的向量,每个维度值代表输入样本的每个像素的权重。
的第i行是一个401维的向量,代表第i个隐藏层的参数。如果我们不考虑偏置项,我们可以得到一个1*400的向量,每个维度值代表输入样本的每个像素的权重。
因此,可视化隐藏单元捕获的“特征”的一种方法是将这个400维向量重新整形为20 x 20图像并显示它

下面的代码将会使用displayData函数,并且使用25个单元为我们展示图像。每一个都对应网络的隐藏层的单元。我们训练的网络中。我们应该会发现每个隐藏层的单元粗略的表示输入层中相应笔画,和其他图案的探测器。
% Visualize Weights
displayData(Theta1(:, 2:end));
所以就可以证明,相当于通过一定约束,在输入层找到一个输入,为隐藏层提供一个最高的激活值。
3.1 选作练习
在这一部分的练习。我们尝试为我们的神经网络设置不同学习参数(正则化参数,训练次数),来看我们的神经网络的表现的变化。神经网络是很强大的模型可以形成非常复杂的决策边界。没有正则化神经网络很可能会过度拟合,对于给定的训练集获得100%精度。但是预测的话不会有很好的表现。现在我们可以设置正则化参数,与迭代次数。来观察识别精度。
% Change lambda and MaxIter to see how it affects the result lambda = 3; MaxIter = 25; options = optimset('MaxIter', MaxIter); % Create "short hand" for the cost function to be minimized costFunction = @(p) nnCostFunction(p,input_layer_size, hidden_layer_size, num_labels, X, y, lambda); % Now, costFunction is a function that takes in only one argument (the neural network parameters) [nn_params, ~] = fmincg(costFunction, initial_nn_params, options); % Obtain Theta1 and Theta2 back from nn_params Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), hidden_layer_size, (input_layer_size + 1)); Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), num_labels, (hidden_layer_size + 1)); pred = predict(Theta1, Theta2, X); fprintf(' Training Set Accuracy: %f ', mean(double(pred == y)) * 100); % Visualize Weights displayData(Theta1(:, 2:end));