做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500
爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后在代码中用正则表达式来匹配相关节点的信息。
难点:
1.选取抓取节点
2.抓取信息的正则表达式(需要考虑到特别个例,有时候要重复试很多次才搞定)
3.格式的转换(window下命令提行默认的编码是GBK,而网页默认的是编码是utf-8,编码不匹配就会出现乱码)
4.将抓取的信息加载到数据库里,这里对格式处理的要求比较高。之前在这里卡了好久。
抓取的一些小技巧:
对于抓取条码多而复杂的,而且在源码中的格式不是完全一样的,可以将代表性的条目单独挑出来分析,我是将条目剔出来放到excel表格中进行分析的:
分析书名和作者:

一次类推,可以比较快速和方便的匹配到你想要的东西。
本爬虫采用的是面向对象编程的形式来代码实现。

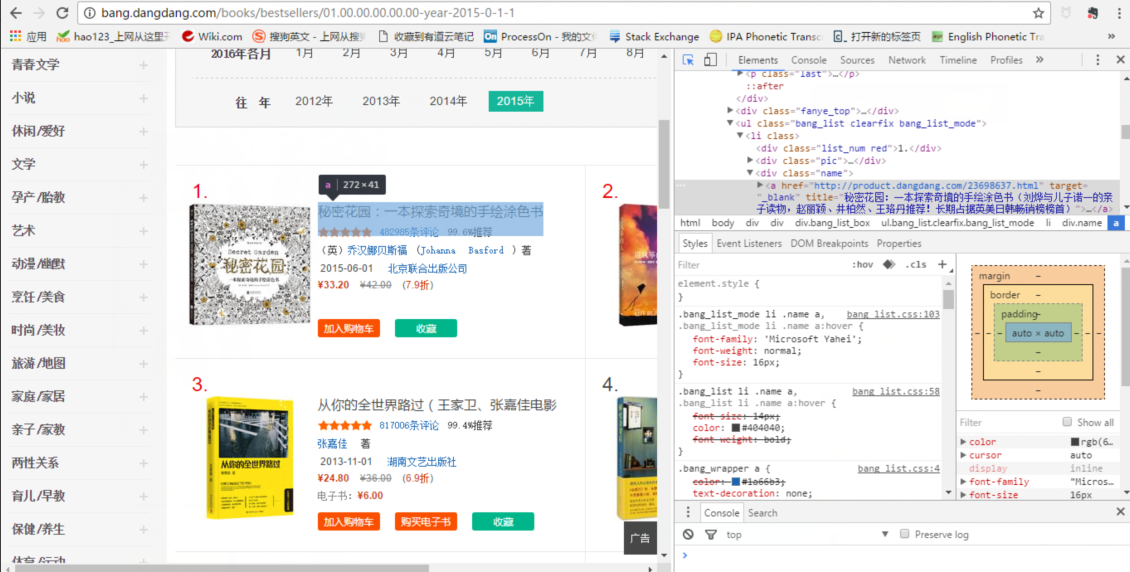
网页源码

代码中,正则表达式匹配的部分示例:

爬取过程的打印信息:
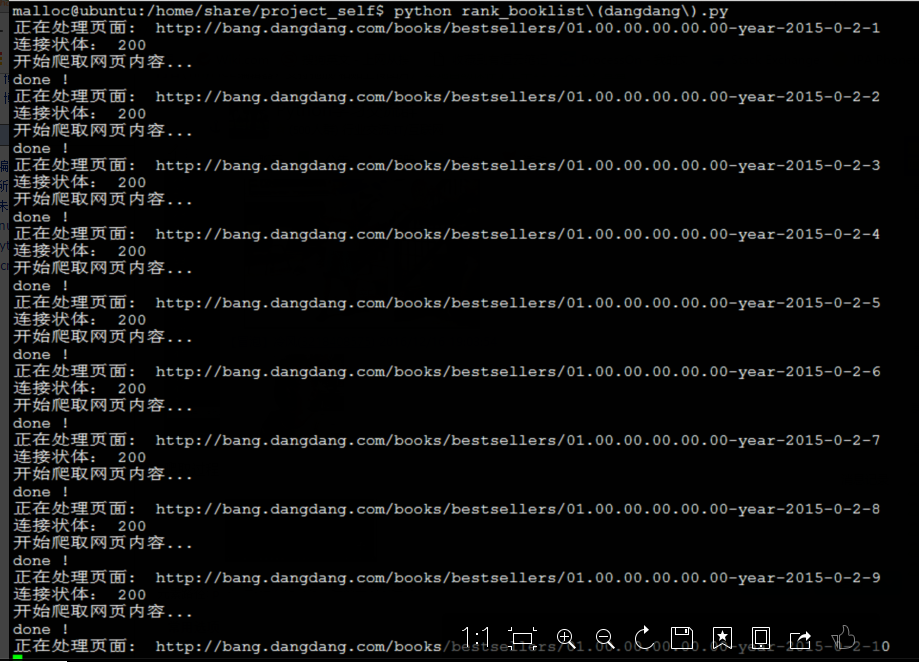
结果展示(由于之后要以一定的格式插入数据库,所以格式上没有做很好的排版):

数据插入数据库后相关的操作:
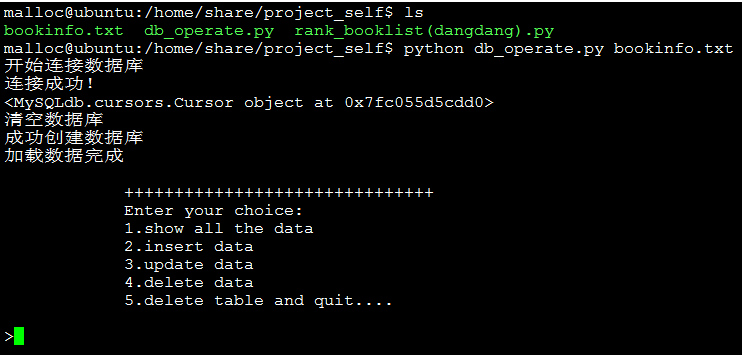
以上是相关图片展示,废话少说直接上代码,代码托管在github上:
https://github.com/ptJohny/Web-Crawler/tree/master/crawler_bookinfo
以上只是单线爬虫,之后将会更新更多类型的爬虫。