1. copy命令
对于数据加载,GreenPlum数据库提供copy工具,copy工具源于PostgreSQL数据库,copy命令支持文件与表之间的数据加载和表对文件的数据卸载。使用copy命令进行数据加载,数据需要经过Master节点分发到Segment节点,同样使用copy命令进行数据卸载,数据也需要由Segment发送到Master节点,由Master节点汇总后再写入外部文件,这样就限制了数据加载与卸载的效率,但是数据量较小的情况下,copy命令就非常方便。下面测试通过copy命令实现操作系统文件到数据库中表的数据加载。
1.1 创建测试表
lottu=# create table tbl_pay_log_copy (id int primary key,order_num varchar(100),accountid varchar(30),qn varchar(20),appid int,amount numeric(10,2),pay_time timestamp); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "tbl_pay_log_copy_pkey" for table "tbl_pay_log_copy" CREATE TABLE lottu=# d tbl_pay_log_copy Table "public.tbl_pay_log_copy" Column | Type | Modifiers -----------+-----------------------------+----------- id | integer | not null order_num | character varying(100) | accountid | character varying(30) | qn | character varying(20) | appid | integer | amount | numeric(10,2) | pay_time | timestamp without time zone | Indexes: "tbl_pay_log_copy_pkey" PRIMARY KEY, btree (id), tablespace "tbs_lottu" Distributed by: (id) Tablespace: "tbs_lottu"
1.2 准备测试数据
[gpadmin@mdw ~]$ head ios_pay.txt 73,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 17:36:43 72,ysios_receipt_32946f3d37e774781babe103352bd230,27424976,yriu1244_16043_001,2616,30.00,2017-11-06 15:18:56 75,ysios_receipt_3e2e432550253450412692392c7675d0,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 07:33:03 74,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 20:40:46 77,ysios_receipt_ee6bed338a32f836a999133cd2e6d547,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 22:27:46 76,ysios_receipt_ae53b142924c0604820537d61a9dd73e,27424976,yriu1244_16043_001,2616,648.00,2017-10-19 12:10:17 79,ysios_receipt_30ec130bcdf0e864629d12f8392d4b43,27385229,yriu1244_16043_001,2616,98.00,2017-10-21 07:46:01 78,ysios_receipt_e2b62024f1b0c3a2c3aae1e80f126eb6,27387306,yriu1244_16043_001,2616,25.00,2017-10-20 01:54:24 81,ysios_receipt_3e72a8e32c9fee546ab08d103606e6cb,27424976,yriu1244_16043_001,2616,30.00,2017-10-21 13:55:54 80,ysios_receipt_6ca291884fcfe3d1583b49a3611b4ccc,27424976,yriu1244_16043_001,2616,25.00,2017-10-21 13:55:51 [gpadmin@mdw ~]$ wc -l ios_pay.txt 20027 ios_pay.txt [gpadmin@mdw ~]$ du -sh ios_pay.txt 1.9M ios_pay.txt
现在文本“ios_pay.txt”有20027行记录;大小约2M。
1.3 copy命令语法
lottu=# h copy Command: COPY Description: copy data between a file and a table Syntax: COPY table [(column [, ...])] FROM {'file' | STDIN} [ [WITH] [OIDS] [HEADER] [DELIMITER [ AS ] 'delimiter'] [NULL [ AS ] 'null string'] [ESCAPE [ AS ] 'escape' | 'OFF'] [NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'] [CSV [QUOTE [ AS ] 'quote'] [FORCE NOT NULL column [, ...]] [FILL MISSING FIELDS] [ [LOG ERRORS INTO error_table] [KEEP] SEGMENT REJECT LIMIT count [ROWS | PERCENT] ] COPY {table [(column [, ...])] | (query)} TO {'file' | STDOUT} [ [WITH] [OIDS] [HEADER] [DELIMITER [ AS ] 'delimiter'] [NULL [ AS ] 'null string'] [ESCAPE [ AS ] 'escape' | 'OFF'] [CSV [QUOTE [ AS ] 'quote'] [FORCE QUOTE column [, ...]] ]
常用参数
分隔符:[DELIMITER [ AS ] 'delimiter']
处理空列(含有空格符的是不行的):[NULL [ AS ] 'null string']
记录错误数据,错误日志表自动创建: [LOG ERRORS INTO error_table] [KEEP]
允许错误的行数或者百分比,大于指定值导入失败全部回滚:SEGMENT REJECT LIMIT count [ROWS | PERCENT] ]
1.4 数据加载
执行必须拥有superuser权限的用户
lottu=# du lottu List of roles Role name | Attributes | Member of -----------+----------------------+----------- lottu | Superuser, Create DB |
执行命令;使用默认参数如下:
命令:copy tbl_pay_log_copy from '/home/gpadmin/ios_pay.txt' with delimiter ',' null '' ;
lottu=# copy tbl_pay_log_copy from '/home/gpadmin/ios_pay.txt' with delimiter ',' null '' ; ERROR: invalid input syntax for type numeric: "w" (seg0 sdw1:40000 pid=3183) CONTEXT: COPY tbl_pay_log_copy, line 32, column 3
出现错误行记录;先不讨论如何跳过错误行记录;执行copy命令失败;是否有必要对表进行VACUUM?可以验证下
lottu=# select ctid,id from tbl_pay_log_copy ; ctid | id ------+---- (0 rows) lottu=# insert into tbl_pay_log_copy (id) values (1); INSERT 0 1 lottu=# select ctid,id from tbl_pay_log_copy ; ctid | id --------+---- (0,17) | 1 (1 row)
执行失败;数据是回滚了;但是插入记录并不是从(0,0)开始的;所以执行有必要对表进行VACUUM
如何跳过错误行;加入下面参数即可
LOG ERRORS INTO参数指定错误数据记录到哪张表中
SEGMENT REJECT LIMIT参数指定最大跳过的错误数
命令:copy tbl_pay_log_copy from '/home/gpadmin/ios_pay.txt' with delimiter ',' null '' LOG ERRORS INTO tbl_pay_log_copy_errs SEGMENT REJECT LIMIT 100;
lottu=# copy tbl_pay_log_copy from '/home/gpadmin/ios_pay.txt' with delimiter ',' null '' LOG ERRORS INTO tbl_pay_log_copy_errs SEGMENT REJECT LIMIT 100; NOTICE: Error table "tbl_pay_log_copy_errs" does not exist. Auto generating an error table with the same name WARNING: The error table was created in the same transaction as this operation. It will get dropped if transaction rolls back even if bad rows are present HINT: To avoid this create the error table ahead of time using: CREATE TABLE <name> (cmdtime timestamp with time zone, relname text, filename text, linenum integer, bytenum integer, errmsg text, rawdata text, rawbytes bytea) NOTICE: Found 1 data formatting errors (1 or more input rows). Errors logged into error table "tbl_pay_log_copy_errs" COPY 20026
表tbl_pay_log_copy成功插入20026行记录;1条失败记录插入表tbl_pay_log_copy_errs;该表不需要创建;若库不存在表;则会创建
下面看下这20026条数据的数据分布情况。是否倾斜?
lottu=# select gp_segment_id,count(*) from tbl_pay_log_copy group by 1; gp_segment_id | count ---------------+------- 0 | 10013 1 | 10013
1.5 数据卸载
Copy工具不仅可以把数据从文件加载到数据库的表中,也可以将数据从数据库的表中卸载到操作系统的文件中。如下:
命令:copy tbl_pay_log_copy to '/home/gpadmin/tbl_pay_log_copy_output.txt' WITH DELIMITER AS ',';
lottu=# copy tbl_pay_log_copy to '/home/gpadmin/tbl_pay_log_copy_output.txt' WITH DELIMITER AS ','; COPY 20026
也可以根据query进行卸载;这样可以根据需求导出自己需要的记录或者列记录。如下:
命令:copy (select * from tbl_pay_log_copy where id = 73) to '/home/gpadmin/tbl_pay_log_copy_id_73.txt' WITH DELIMITER AS ',';
lottu=# copy (select * from tbl_pay_log_copy where id = 73) to '/home/gpadmin/tbl_pay_log_copy_id_73.txt' WITH DELIMITER AS ','; COPY 1
查看导出文件
[gpadmin@mdw ~]$ ll tbl_pay_log_copy_output.txt tbl_pay_log_copy_id_73.txt -rw-r--r--. 1 gpadmin gpadmin 109 Apr 18 22:52 tbl_pay_log_copy_id_73.txt -rw-r--r--. 1 gpadmin gpadmin 1917463 Apr 18 22:50 tbl_pay_log_copy_output.txt
使用SELECT的COPY效率比直接使用表名COPY效率低很多,对于数据量稍大的表,可以考虑使用中间表结合COPY的方式来卸载数据
1.6 其他参数解释
format:指定导入的文件格式为csv格式
escape:指定了在引号中的转义字符为反斜杠,这样即使在引号字串中存在引号本身,也可以用该字符进行转义,变为一般的引号字符,而不是字段终结
header true:指定文件中存在表头。如果没有的话,则设置为false
quote:指定了以双引号作为字符串字段的引号,这样它会将双引号内的内容作为一个字段值来进行处理
2. 使用gpfdist的外部表
外部表提供了对Greenplum数据库之外的来源中数据的访问。可以用SELECT语句访问它们,外部表通常被用于抽取、装载、转换(ELT)模式,这是一种抽取、转换、装载(ETL)模式的变种,这种模式可以利用Greenplum数据库的快速并行数据装载能力。这是COPY命令不持有的。
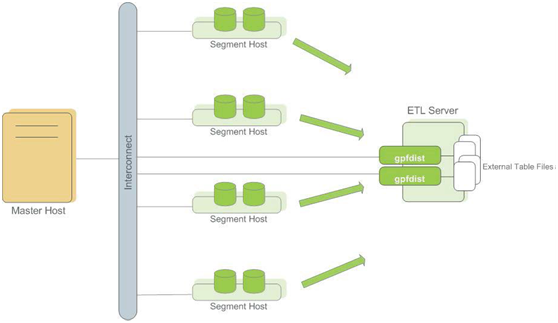
外部表加载方式有很多;详细介绍《请见Greenplum数据库参考指南》
gpfdist原理:
gpfdist是一个使用HTTP协议的文件服务器程序,它以并行的方式向Greenplum数据库的Segment供应外部数据文件一个gpfdist实例,每秒能供应200MB并且很多gpfdist进程可以同时运行,每一个供应要被装载的数据的一部分。当使用者用INSERT INTO <table> SELECT * FROM <external_table>这样的语句开始装载时,INSERT语句会被Master解析并且分布给主Segment。Segment连接到gpfdist服务器并且并行检索数据,解析并验证数据,从分布键数据计算一个哈希值并且基于哈希键把行发送给它的目标Segment。每个gpfdist实例默认将接受最多64个来自Segment的连接。通过让许多Segment和gpfdist服务器参与到装载处理中,可以以非常高的速率被装载。
2.1 创建实验环境
lottu=# create table tbl_pay_log_gpfdist(id int primary key,order_num varchar(100),accountid varchar(30),qn varchar(20),appid int,amount numeric(10,2),pay_time timestamp); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "tbl_pay_log_gpfdist_pkey" for table "tbl_pay_log_gpfdist" CREATE TABLE lottu=# d tbl_pay_log_gpfdist Table "public.tbl_pay_log_gpfdist" Column | Type | Modifiers -----------+-----------------------------+----------- id | integer | not null order_num | character varying(100) | accountid | character varying(30) | qn | character varying(20) | appid | integer | amount | numeric(10,2) | pay_time | timestamp without time zone | Indexes: "tbl_pay_log_gpfdist_pkey" PRIMARY KEY, btree (id), tablespace "tbs_lottu" Distributed by: (id) Tablespace: "tbs_lottu" [gpadmin@mdw ~]$ head ios_pay.txt 73,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 17:36:43 72,ysios_receipt_32946f3d37e774781babe103352bd230,27424976,yriu1244_16043_001,2616,30.00,2017-11-06 15:18:56 75,ysios_receipt_3e2e432550253450412692392c7675d0,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 07:33:03 74,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 20:40:46 77,ysios_receipt_ee6bed338a32f836a999133cd2e6d547,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 22:27:46 76,ysios_receipt_ae53b142924c0604820537d61a9dd73e,27424976,yriu1244_16043_001,2616,648.00,2017-10-19 12:10:17 79,ysios_receipt_30ec130bcdf0e864629d12f8392d4b43,27385229,yriu1244_16043_001,2616,98.00,2017-10-21 07:46:01 78,ysios_receipt_e2b62024f1b0c3a2c3aae1e80f126eb6,27387306,yriu1244_16043_001,2616,25.00,2017-10-20 01:54:24 81,ysios_receipt_3e72a8e32c9fee546ab08d103606e6cb,27424976,yriu1244_16043_001,2616,30.00,2017-10-21 13:55:54 80,ysios_receipt_6ca291884fcfe3d1583b49a3611b4ccc,27424976,yriu1244_16043_001,2616,25.00,2017-10-21 13:55:51 [gpadmin@mdw ~]$ wc -l ios_pay.txt 20027 ios_pay.txt [gpadmin@mdw ~]$ du -sh ios_pay.txt 1.9M ios_pay.txt
现在文本“ios_pay.txt”有20027行记录;大小约2M。
2.2 gpfdist加载数据
在看下gpfdist工具,gpfdist工具可以实验并行加载,需要先启动gpfdist进程及监听端口,这个命令在Master和Segment节点的GPHOME/bin目录下,如果配置了GP的环境变量,可以直接使用,如果在没有安装GP的服务器上使用gpfdist工具,只需要将gpfdist命令的文件拷贝到相应的服务器上即可使用。
本实验文件在Master节点上;只需在Master启动。
命令: nohup gpfdist -d /home/gpadmin -p 1234 -l /home/gpadmin/gpfdist.log &
[gpadmin@mdw ~]$ nohup gpfdist -d /home/gpadmin -p 1234 -l /home/gpadmin/gpfdist.log & [1] 28777
如上命令,启动gpfdist进程,扫描路径为/home/gpadmin,监听端口为1234,下面创建一张基于gpfdist工具的外部表。
create external table med_pay_log_gpfdist (id int,order_num varchar(100),accountid varchar(30),qn varchar(20),appid int,amount numeric(10,2),pay_time timestamp) location('gpfdist://mdw:1234/ios_pay.txt') format 'TEXT' (DELIMITER as ',' null as ''ESCAPE as 'OFF') encoding 'utf8' LOG ERRORS INTO med_pay_log_gpfdist_err SEGMENT REJECT LIMIT 100;
查看gpfdist进程
ps -ef|grep gpfdist|grep -v "grep"
停掉gpfdist进程
kill xxx pg_cancel_backend(xxx)
加载数据
lottu=# insert into tbl_pay_log_gpfdist select * from med_pay_log_gpfdist; NOTICE: Found 1 data formatting errors (1 or more input rows). Rejected related input data. INSERT 0 20026 Time: 780.017 ms
ANALYZE表
lottu=# analyze tbl_pay_log_gpfdist; ANALYZE
加载完成之后需要停到gpfdist进程
[gpadmin@mdw ~]$ ps -ef|grep gpfdist|grep -v "grep" gpadmin 28777 20448 0 00:32 pts/1 00:00:00 gpfdist -d /home/gpadmin -p 1234 -l /home/gpadmin/gpfdist.log [gpadmin@mdw ~]$ kill 28777
删除外部表
lottu=# drop external table med_pay_log_gpfdist; DROP EXTERNAL TABLE
GP数据库查询数据,先扫描到的数据会直接返回,也就是多次查询的结果可能是不一样的,使用gpfdist工具加载,而gpfdist工具加载数据是并行加载的,最先插入到数据库的数据并不一定是从第一条数据开始的。
查看数据是否倾斜
lottu=# select gp_segment_id,count(*) from tbl_pay_log_gpfdist group by 1; gp_segment_id | count ---------------+------- 1 | 10013 0 | 10013
2.3 卸载数据
使用可写外部表卸载数据时,如果使用gpfdist工具,就可以实现并行卸载,而且数据不需要经过Master节点,直接由Segment节点写入到外部文件中,效率比较高,卸载大量数据时,使用这种方式会节省大量的时间。
下面测试通过可写外部表并且使用gpfdist工具来卸载数据到sdw1主机上
在sdw1主机启动gpfdist进程
nohup gpfdist -d /home/gpadmin -p 1234 -l /home/gpadmin/gpfdist.log &
创建可写外部表
lottu=# create writable external table med_pay_log_gpfdist_unload (like tbl_pay_log_gpfdist) location ('gpfdist://192.168.1.202:1234/unload.txt') Format 'text'; NOTICE: Table doesn't have 'distributed by' clause, defaulting to distribution columns from LIKE table CREATE EXTERNAL TABLE Time: 46.912 ms
卸载数据
lottu=# insert into med_pay_log_gpfdist_unload select * from tbl_pay_log_gpfdist; INSERT 0 20026
卸载完成之后需要停到gpfdist进程
[gpadmin@sdw1 ~]$ ps -ef|grep gpfdist|grep -v "grep" gpadmin 4650 1163 0 00:57 pts/0 00:00:00 gpfdist -d /home/gpadmin -p 1234 -l /home/gpadmin/gpfdist.log [gpadmin@sdw1 ~]$ kill 4650
删除外部表
lottu=# drop external table med_pay_log_gpfdist_unload; DROP EXTERNAL TABLE
3. GreenPlum数据加载工具gpload
gpload是一种数据装载工具,它扮演着Greenplum外部表并行装载特性的接口的角色。gpload使用定义在一个YAML格式的控制文件中的规范来执行一次装载。
它会执行下列操作:
- 调用gpfdist进程
- 基于定义的源数据创建一个临时的外部表定义
- 执行INSERT、UPDATE或者MERGE操作将源数据载入数据库中的目标表
- 删除临时外部表
- 清除gpfdist进程
3.1 创建实验环境
create table tbl_pay_log_gpload (like tbl_pay_log_gpfdist);
3.2 创建YAML格式控制文件
使用gpload工具,需要编写gpload工具的控制文件,这个控制文件是使用yuml语言编写,如下是gpload工具的演示
--- VERSION: 1.0.0.1 DATABASE: lottu USER: lottu HOST: mdw PORT: 5432 GPLOAD: INPUT: - SOURCE: LOCAL_HOSTNAME: - sdw1 PORT: 1234 FILE: - /home/gpadmin/unload.txt - COLUMNS: - id: int - order_num: varchar - accountid: varchar - qn: varchar - appid: int - amount: numeric - pay_time: timestamp - FORMAT: text - ERROR_LIMIT: 25 - error_table: public.tbl_pay_log_gpload_err OUTPUT: - TABLE: public.tbl_pay_log_gpload - MODE: INSERT SQL: - BEFORE: "truncate table public.tbl_pay_log_gpload" - AFTER: "ANALYZE tbl_pay_log_gpload"
特别提醒:“-”后一定要有空格;“:”后也一定要有空格。
参数说明:
VERSION 自定义版本号(可选项) DATABASE 需要连接的数据库,如果没有指定,根据$PGDATABASE变量确定 USER 执行操作的用户。如果没指定,根据$PGUSER变量确定 HOST 可选项。指定master节点的主机名(IP)。如果没指定,根据变量$PGHOST确定。 PORT 可选项。指定master的端口,默认是5432或者$GPORT。 GPLOAD 必须项。load部分的开始。一个GPLOAD部分必须包含一个INPUT和一个OUTPUT。 INPUT 必须项。定义加载数据的格式和位置。gpload在当前主机上启动一个或者多个gpfdist文件分布式实例 。注意,gpload命令所在主机可网络访问Greenplum中的每个节点(master&segment)。 SOURCE 必须项。INPUT部分的SOURCE块其定义了source文件所在位置。一个INPUT部分中可以有1个或者多个SOURCE块定义。每个SOURCE块定义对应了一个本机的gpfdist实例。每个SOURCE块定义必须制定一个source文件。 LOCAL_HOSTNAME 可选项。gpload工具运行所在的主机名或者IP地址。如果这台主机有多个网卡,能同时使用每个网卡(每个网卡都有一个IP地址),通过设定LOCAL_HOSTNAME和PORT 实现多个gpfdist实例,可提升数据加载速度。默认情况,只使用主主机名或者IP地址。 PORT 可选项。gpfdist实例需要的端口。 FILE 必须项。文件位置。可同时制定多个相同格式的文件,入/home/gpadmin/script/*.txt。如果是gzip或bzip2文件,会自动解压(在环境变量中设定好gunzip、bunzip2的路径)。 CLOUMNS 可选项。说明source文件的格式,列名:数据类型。DELIMITER参数,指明source文件中两个数据之间的分隔符。如果没有指定COLUMNS选项,意味着source文件中的列的顺序、列的数量、数据类型都和目标表一致。COLUMN的作用:SOURCE_TO_TARGET的mapping关系。 FORMAT 可选项。source文件的类型,比如text、csv。默认text格式不说指定。 DELIMITER 可选项。一行数据中,各列的分隔符号。TEXT格式中默认tab作为分隔符;CSV中以都好","作为分隔符。 ERROR_LIMIT 可选项。允许的错误行数。加载数据时,错误数据将被忽略。如果没有到达错误限制数量,所有正常行会加载到GP中,问题行会存放到err_table中。如果超过错误值,正常数据也不会加载。 ERROR_TABLE 可选项。前提是开启了ERROR_LIMIT 。错误表将记录错误行。如果错误表不存在,会自动创建。若存在,直接插入数据。 EXTERNAL 可选项。定义外部表。 OUTPUT 必须项。定义最终source文件加载到的目标表。 TABLE 必须项。目标表。 MODE 可选项。有三种模式:insert,插入数据; update,当MATCH_COLUMNS参数值(相当于关联列)等于加载数据时,更新UPDATE_COLUMS参数设置的列(相当于update的列)。 并且,必须设置UPDATE_CONDITION参数(相当于where过滤条件)。merge, 加载数据时,插入目标表中不存在的数据,更新目标中存在的数据。 MATCH_COLUMNS 在UPDATE或者MERGE模式下使用。相当于关联列。这里写目标表的列名。 UPDATE_COLUMNS 在UPDATE或者MERGE模式下使用。更新的目标表列名。 UPDATE_CONDITION 可选项。目标表的列名,相当于where条件。用在update或者merge模式。 MAPPING 可选项。如果设置了MAPPING参数,那么前面设置的COLUMNS参数会失效,因为MAPPING级别高于COLUMNS。关联格式:target_column_name: source_column_name。where过滤格式:target_column_name: 'expression' RELOAD 可选项。导入时,是truncate之前目标表的数据,还是保留目标表数据。两种模式,TRUNCATE 和REUSE_TABLES。 SQL 可选项。定义开始运行gpload和gpload结束执行的SQL语句。BEFORE,开始运行gpload执行的SQL,SQL需引号括起来;AFTER,gpload结束后执行的SQL,SQL需引号括起来。
3.3 加载数据
然后使用gpload工具,将数据加载到数据库。
[gpadmin@sdw1 ~]$ gpload -f gpload.yml 2018-04-19 18:28:37|INFO|gpload session started 2018-04-19 18:28:37 Password: 2018-04-19 18:28:40|INFO|started gpfdist -p 1234 -P 1235 -f "/home/gpadmin/unload.txt" -t 30 2018-04-19 18:28:42|INFO|running time: 5.38 seconds 2018-04-19 18:28:43|INFO|rows Inserted = 22052 2018-04-19 18:28:43|INFO|rows Updated = 0 2018-04-19 18:28:43|INFO|data formatting errors = 0 2018-04-19 18:28:43|INFO|gpload succeeded
4. 数据装载性能技巧
-
在装载前删除索引 – 若装载一张新创建的表,最快的方式是先创建表,再装载数据,然后再创建任何需要的索引。在已存在的数据上创建索引比不断的递增索引要快。若向一个已有的表添加大量数据,更快的方式可能是,先删除索引,然后装载数据,然后再重新创建索引。临时的增加maintenance_work_mem服务器参数可以提升CREATE INDEX名的速度,不过,这可能对于装载数据本身没有性能提升。应该考虑在没有系统用户在用时进行删除并重新建立索引操作。
-
在装载之后运行ANALYZE -- 在修改了表中的大部分数据之后,强烈建议执行ANALYZE操作。执行ANALYZE(或者VACUUM ANALYZE)以确保查询规划器拥有最新的统计信息。如果没有统计信息或者统计信息过时了,规划器可能会根据过期的统计信息或不存在的统计信息选择一个较差的查询计划,以至导致较差的性能。
-
在装载出错后执行VACUUM – 如果运行的不是单条记录错误隔离模式,装载操作将在首次发生错误时终止。而目标表已经收到了错误发生前的记录。这些记录是无法被访问的,但它们仍占据磁盘空间。若这种情况发生在大的装载操作上,会导致大量的磁盘空间浪费。执行VACUUM命令可以回收这些浪费的空间。
- 在装载期间通过将gp_autostats_mode配置参数设置为NONE禁用自动统计信息收集。set gp_autostats_mode = none;
使用gpfdist和gpload装载数据的详细指导请见《Greenplum数据库参考指南》。