理论部分
概述
- 循环神经网络(RNN),是一类可以在一定程度上预测未来的网络
- 它们可以处理任意长度的序列,而不是像我们到目前为止考虑的所有网络一样,用于固定大小的输入。例如,它们可以将句子、文档或音频样本作为输入,使其对于自然语言处理应用非常有用,例如自动翻译或语音转文本
- RNN面临的两个主要困难
- 不稳定的梯度
- (非常)有限的短期记忆
循环神经元和层
- 前馈神经网络,激活仅在一个方向上流动,从输入层流向输出层
- 循环神经网络看起来非常像前馈神经网络,除了他还具有指向反向的链接
- 最简单的RNN
- 由一个神经元接受输入,产生输出并将该输出反送回自身组成
- 在每个时间步长t(也称为帧),该循环神经元接受输入x(t)和前一个时间步长y(t)的输出。由于在第一个时间步长中没有先前的输出,因此通常将其设置为0
- 我们可以相对于时间轴来表示这个小网络,这被称为随着时间展开网络(它是同一个递归神经元,每个时间步长代表一个)
\[单个实例的循环层的输出:\\
y_{(t)} = \phi(W^T_xx_{(t)}+W^T_yy_{(t-1)}+b)\\
小批量中的所有实例的循环神经元层的输出\\
Y_{(t)}=\phi(X_{(t)}W_x+Y_{(t-1)}W_y+b)\\
=\phi([X_{(t)}Y_{(t-1)}]W+b),其中 W=\begin{bmatrix}
W_x\\W_y
\end{bmatrix}\\
其中:Y_{(t)}是一个m*n_{neurons}矩阵,包含小批量处理中每个实例在时间步长t时该层的输出\\
m是小批量处理中的实例数量,n_{neurons}是神经元数量\\
X_{(t)}是一个m*n_{inputs}矩阵,包含所有实例的输入(n_{inputs}是输入特征的数量)\\
W_x是一个n_{inputs}*n_{neurons}矩阵,包含当前时间步长的输入的连接权重\\
W_y是一个n_{neurons}*n_{neurons}矩阵,包含前一个时间步长的输出的连接权重\\
b是大小为n_{neurons}的向量,包含每个神经元的偏置项\\
权重矩阵W_x和W_y经常垂直合并成形状为(n_{inputs}+n_{neurons})*n_{neurons}的单个\\
权重矩阵W\\
符号[X_{(t)}Y_{(t-1)}]表示矩阵X_{(t)}、Y_{(t-1)}的水平合并\\
自时间t依赖,Y_{(t)}称为所有输入的函数(即X_{(0)}, X_{(1)}, ..., X_{(t)})
\]
- 记忆单元
- 由于在时间步长t时递归神经元的输出是先前时间步长中所有输入的函数,因此你可以说它具有记忆的形式。在时间步长上保留某些状态的神经网络的一部分称为记忆单元(或简称为单元)。单个循环神经元或一层循环神经元是一个非常基本的单元,它只能学习短模式(通常约为10个步长,但这取决于任务)
- 通常,在时间步长t的单元状态,表示为h(t)(h代表隐藏),是该时间步长的某些输入和其前一个时间步长状态的函数:h(t)=f(h(t-1), x(t))。它在时间步长t处的输出表示为y(t),也是先前状态和当前输入的函数。但是在更复杂的单元中,单元的隐藏状态和其输出可能不同
- 输入和输出序列
- RNN可以同时接受输入序列并产生输出序列。这种类型的序列到序列的网络可用于预测诸如股票价格之类的时间序列:你将过去N天的价格作为输入,它必须输出未来偏移一天的价格(即从前N-1天到明天)
- 你可以向网络提个一个输入序列,并忽略除了最后一个输出外的所有输出。换句话说,这是一个序列到向量的网络。例如,你可以向网络提供与电影评论相对应的单词序列,然后网络将输出一个情感得分(例如从-1[恨]到+1[爱])
- 你可以在每个时间步长中一次又一次地向网络提供相同的输入向量,并让其输出一个序列。这是一个向量到序列的网络。例如,输入可以是图像(或CNN的输出),而输出可以是该图像的描述
- 你可能有一个称为编码器的序列到向量的网络,然后是一个称为解码器的向量到序列的网络,例如,这可以用于将句子从一种语言翻译成为另一种语言,这称为编码器-解码器模型
训练RNN
- 要训练RNN,诀窍是将其按照时间逐步展开,然后简单地使用常规的反向传播。这种策略称为“时间反向传播”(BPTT)
- 就像在常规反向传播中一样,这里有一个通过展开网络的第一次前向通路,然后使用成本函数来评估输出序列,然后该成本函数的梯度通过展开的网络反向传播,最后使用BPTT期间计算的梯度来更新模型参数。由于在每个时间步长使用相同的参数w和b,所以反向传播会做正确的事情,在所有时间步长上求和
预测时间序列
- 每个时间步长只有一个值,因此它们是单变量时间序列,如果每个时间步长有多个值,则它是一个多变量时间序列。典型的任务是预测未来值,这称为预测;另一个常见的任务是替补空白:预测过去的缺失值,这称为插补
- 在处理时间序列(以及其他类型的序列,例如句子)时,输入特征通常表示为形状[批处理大小,时间步长,维度]的3D数组,其中但变量时间序列的维度为1,多变量时间序列的维度更多
- 基准指标
- 在开始使用RNN之前,通常最好有一些基准指标,否则我们可能会认为我们的模型工作得很好,但是实际上它可能表现得比基本模型差
- 最简单的方法是预测每个序列中的最后一个值,这被称为单纯预测
- 另一种简单的办法是使用全连接的网络,由于它希望每个输入都有一个平的特征列表,因此我们需要添加一个Flatten层,让我们只使用一个简单的线性回归模型,使每个预测是时间序列中值的线性组合
- 实际上,与其训练模型在最后一个时间步长预测下一个10个值,不如训练模型在每个时间步长来预测下一个10个值。换句话说,我们可以将这个序列到向量的RNN转换为序列到序列的RNN。这种技术的优势在于,损失将包含每个时间步长的RNN输出项,而不仅仅是最后一个时间步长的输出项。这意味着将有更多的误差梯度流过模型,它们不需要随时间而“流淌”。它们从每个时间步长的输出中流出,这会稳定和加速训练
- 在预测时间序列时,将一些误差与预测一起使用通常很有用,例如在每个记忆单元内添加一个MC Dropout层,删除部分输入和隐藏状态。训练后,为了预测新的时间序列,多次使用模型,并在每个时间步长计算预测的均值和标准差
处理长序列
-
应对不稳定梯度问题
- 我们在深度网络中用于应对不稳定梯度问题的许多技巧也可以用于RNN:良好的参数初始化、更快的优化器、dropout,等等。但是,非饱和激活函数(例如ReLU)在这里可能没有太大的帮助。实际上,它们可能导致RNN在训练过程中变得更加不稳定。假设梯度下降以一种在第一个时间步长稍微增加输出的方式来更新权重。由于每个时间步长都使用相同的权重,因此在第二个时间步长的输出也可能会略有增加,第三个时间步长的输出也会稍有增加,以此类推,直到输出爆炸为止,而非饱和激活函数不能阻止这种情况。你可以使用较小的学习率来降低这种风险,但也可以使用饱和激活函数(例如双曲正切)。同样的方式,梯度本身也会爆炸,如果你发现训练不稳定,可能要查看梯度的大小,也可以使用梯度裁剪
- 此外,批量归一化不能像深度前馈网络那样高效地用于RNN。归一化的另一种形式通常与RNN一起使用会更好:层归一化。它与批量归一化非常相似,但是它不是跨批量维度进行归一化,而是在特征维度上进行归一化。它的一个优点是可以在每个时间步长上针对每个实例独立地即时计算所需的统计信息。这也意味着它在训练和测试期间的行为方式相同,并且不需要使用指数移动平均值来估计训练集中所有实例的特征统计信息。像BN一样,层归一化学习每个输入的比例和偏移参数。在RNN中,通常在输入和隐藏状态的线性组合之后立即使用它
-
解决短期记忆问题
- 由于数据在遍历RNN时会经过转换,因此在每个时间步长都会丢失一些信息。一段时间后,RNN的状态几乎没有任何最初输入的痕迹。
- LSTM(长短期记忆)单元
\[如果你不产看具体构造,则LSTM单元看起来与常规单元完全一样,除了它\\ 的状态被分为两个向量:h_{(t)}和c_{(t)},你可以将h_{(t)}视为短期状态,c_{(t)}为长期状态\\ LSTM关键的思想是网络可以学习长期状态下存储的内容、丢弃的内容以及从\\ 中读取的内容。当长期状态c_{(t-1)}从做导游遍历网络时,你可以看到它首先经过\\ 一个遗忘门,丢掉了一些记忆,然后通过加法操作添加了一些新的记忆(由输入门\\ 选择的记忆)。结果c_{(t)}直接送出来,无须任何进一步的转换。因此,在每个时间\\ 步长中,都会丢掉一些记忆,并添加一些记忆。此外,在加法算法之后,长期状态\\ 被复制并通过tanh函数传输,然后结果被输出门滤波。这将产生短期状态h_{(t)},\\ 等于该时间步长的单元输出y_{(t)}。\\ 门的运作方式:\\ 首先,将当前输入向量x_{(t)}和先前的短期状态h_{(t-1)}馈入四个不同的全连接层。\\ 它们都具有不同的目的:\\ 主要层是输出g_{(t)}的层。它通常的作用是分析当前输入x_{(t)}和先前(短期)状态\\ h_{(t-1)}。在基本单元中,除了这一层,没有其他东西,它的输出直接到y_{(t)}\\ 和h_{(t)}。相比之下,在LSTM单元中,该层的输出并非直接输出,而是将其最重要的\\ 部分存储在长期状态中(其余部分则丢弃)。其他三层是门控制器。由于它们使用逻辑激活\\ 函数,因此它们的输出范围是0到1.如你所见,它们的输出被馈送到逐元素乘法\\ 运算。因此,如果他们输出0,则关闭门;如果它们输出1,则打开门。特别地:\\ 遗忘门(由f_{(t)}控制)控制长期状态的哪些部分应当被删除\\ 输入门(由i_{(0)}控制)控制应将g_{(t)}的哪些部分添加到长期状态\\ 最后输出门(由o_{(t)}控制)控制应在此时间步长读取长期状态的哪些部分并输入\\ h_{(t)}和y_{(t)} \]

-
窥视孔连接
- 在常规LSTM单元中,门控制器只能查看输入x(t)和先前的短期状态h(t-1)。通过让它们也查看长期状态来给它们更多的功能,这看可能是一个好主意,因为它并非总能提高性能
-
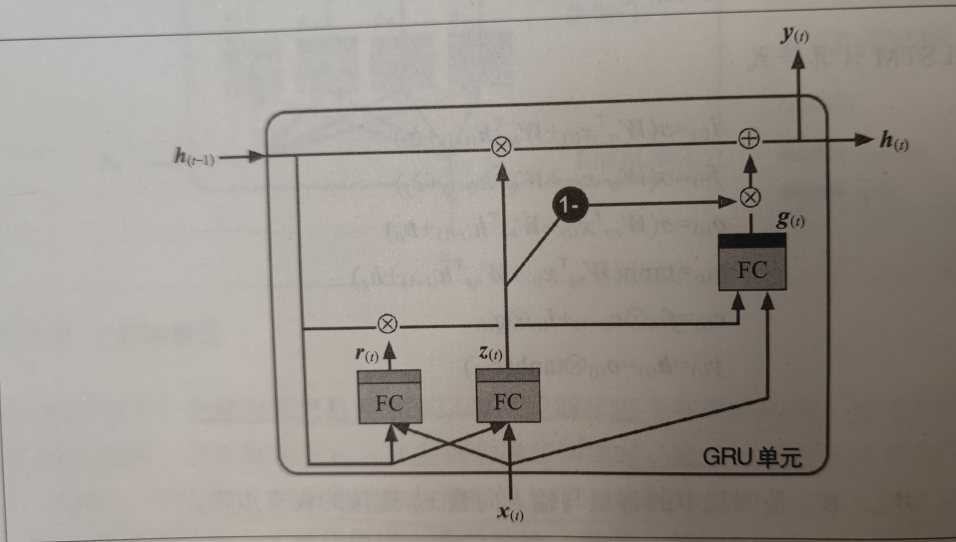
GRU(门控循环)单元
- GRU是LSTM单元的简化版,它的性能似乎也不错。
- 两个状态向量合并为一个h(t)
- 单个门控制器z(t)控制遗忘门和输出门
- 没有输出门,在每个时间步长都输出完整的状态向量。但是有一个新的门控制器r(t)控制先前状态的哪一部分将显示给主要层g(t)
-
LSTM和GRU单元是RNN成功的主要原因之一。尽管它们可以处理比简单RNN更长的序列,但它们的短期记忆仍然非常有限,而且很难学习100个或更多时间步长序列中的长期模式,例如音频样本、长时间序列或长句子。解决这个问题的一种方法是缩短输入序列,例如使用一维卷积层
-
使用一维卷积层处理序列
- 一维卷积层在一个序列上滑动多个内核,为每个内核生成一维特征图。每个内核将学习检测单个非常短的顺序模式(不长于内核大小)。如果你是用10个内核,则该层的输出将由10个一维的序列(所有长度组成)组成,或者等效地,你可以将此输出视为单个10维的序列。这意味着你可以构建由循环层和一维卷积层(甚至一维池化层)混合而成的神经网络。通过缩短序列,卷积层可以帮助GRU层检测更长的模式
- WaveNet
- 它堆叠了一维卷积层,使每一层的扩散率加倍:第一个卷积层一次只看到两个时间步长,而下一个卷积层一次看到四个时间步长(其接受野为四个时间步长),下一个看到八个时间步长,以此类推。这样,较低的层学习短期模式,而较高的层学习长期模式,由于扩散率的加倍,网络可以非常有效地处理非常大的序列
代码部分
引入
import sys
assert sys.version_info >= (3, 5)
IS_COLAB = 'google.colab' in sys.modules
IS_KAGGLE = 'kaggle_secrets' in sys.modules
import sklearn
assert sklearn.__version__ >= '0.20'
import tensorflow as tf
from tensorflow import keras
assert tf.__version__ >= '2.0'
if not tf.config.list_physical_devices('GPU'):
print('No GPU was detected. LSTMs and CNNs can be very slow without a GPU')
if IS_COLAB:
print('Go to Runtime > Change runtime and select a GPU hardware accelerator')
if IS_KAGGLE:
print('Go to Setting > Accelerator and select GPU.')
import numpy as np
import os
from pathlib import Path
np.random.seed(42)
tf.random.set_seed(42)
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
PROJECT_ROOT_DIR = '.'
CHAPTER_ID = 'rnn'
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, 'images', CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension='png', resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + '.' + fig_extension)
print('Saving figure', fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
基础的RNN
# 生成数据集
def generate_time_series(batch_size, n_steps):
freq1, freq2, offset1, offset2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offset1) * (freq1 * 10 + 10))
series += 0.2 * np.sin((time - offset2) * (freq2 * 20 + 20))
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5)
return series[..., np.newaxis].astype(np.float32)
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 1)
X_train, y_train = series[:7000, :n_steps], series[:7000, -1]
X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1]
X_test, y_test = series[9000:, :n_steps], series[9000:, -1]
# y_train是第51个数
X_train.shape, y_train.shape # ((7000, 50, 1), (7000, 1))
def plot_series(series, y=None, y_pred=None, x_label='$t$', y_label='$x(t)$'):
plt.plot(series, '.-')
if y is not None:
plt.plot(n_steps, y, 'bx', markersize=10)
if y_pred is not None:
plt.plot(n_steps, y_pred, 'ro')
plt.grid(True)
if x_label:
plt.xlabel(x_label, fontsize=16)
if y_label:
plt.ylabel(y_label, fontsize=16, rotation=0)
plt.hlines(0, 0, 100, linewidth=1)
plt.axis([0, n_steps + 1, -1, 1])
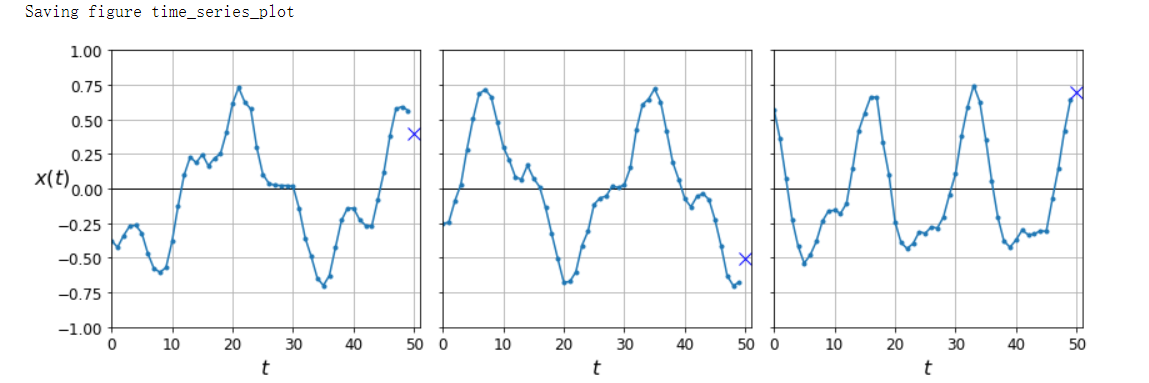
fig, axes = plt.subplots(nrows=1, ncols=3, sharey=True, figsize=(12, 4))
for col in range(3):
plt.sca(axes[col])
plot_series(X_valid[col, :, 0], y_valid[col, 0],
y_label=('$x(t)$' if col == 0 else None))
save_fig('time_series_plot')
plt.show()
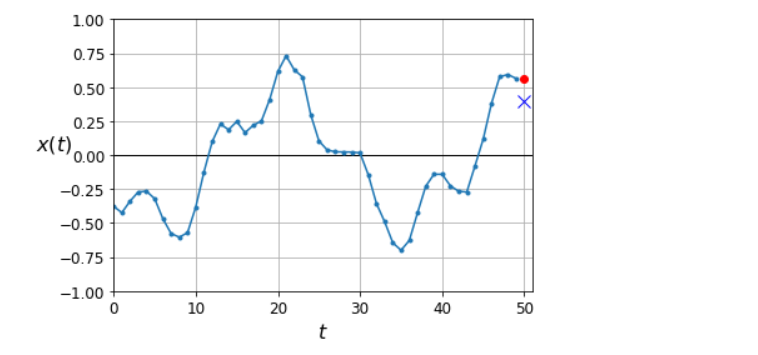
# 计算一些基线
y_pred = X_valid[:, -1] # 第50个值为预测值
np.mean(keras.losses.mean_squared_error(y_valid, y_pred)) # 0.020211367
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
# 线性预测
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[50, 1]),
keras.layers.Dense(1)
])
model.compile(loss='mse', optimizer='adam')
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid) # 0.004168087150901556
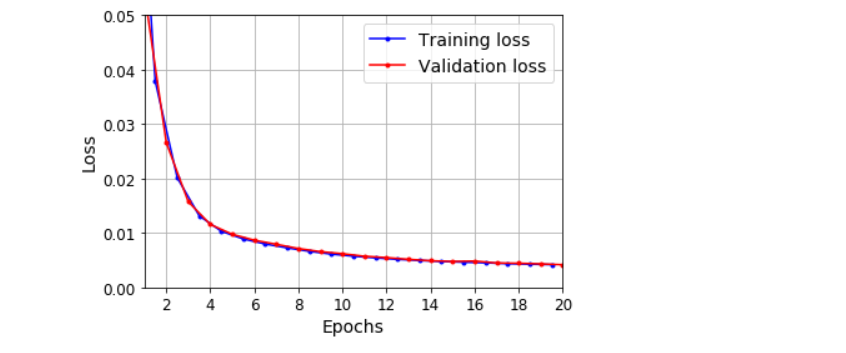
def plot_learning_curves(loss, val_loss):
plt.plot(np.arange(len(loss)) + 0.5, loss, 'b.-', label='Training loss')
plt.plot(np.arange(len(val_loss)) + 1, val_loss, 'r.-', label='Validation loss')
plt.gca().xaxis.set_major_locator(mpl.ticker.MaxNLocator(integer=True))
plt.axis([1, 20, 0, 0.05])
plt.legend(fontsize=14)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid(True)
plot_learning_curves(history.history['loss'], history.history['val_loss'])
plt.show()
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()

# 使用SimpleRNN
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
optimizer = keras.optimizers.Adam(learning_rate=0.005)
model.compile(loss='mse', optimizer=optimizer)
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid) # 0.010881561785936356
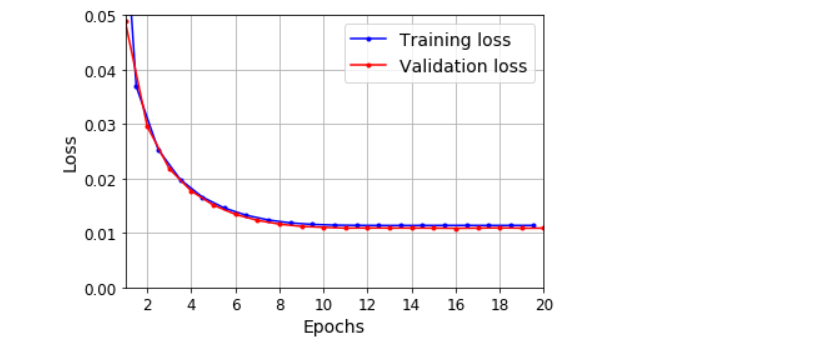
plot_learning_curves(history.history['loss'], history.history['val_loss'])
plt.show()
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()

深度RNN
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.SimpleRNN(1)
])
model.compile(loss='mse', optimizer='adam')
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
注意:最后一层是不理想的:它必须有一个单元,因为我们要预测一个单变量时间序列,这意味着我们每个时间步长必须有一个输出值。但是只有一个单元意味着隐藏状态只是一个数字。那真的不多,可能没什么用。RNN主要使用其他循环层的隐藏状态来传递其所需的所有信息,而不会使用最终层的隐藏状态。此外,由于默认情况下SimpleRNN存使用tanh激活函数,因此预测值必须在-1到1 的范围内。但是,如果你要使用其他激活函数怎么办?由于这两个原因,最好把输出层替换为Dense层:运行速度稍快,精度大致相同
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(1)
])
model.compile(loss='mse', optimizer='adam')
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid) # 0.0026236227713525295
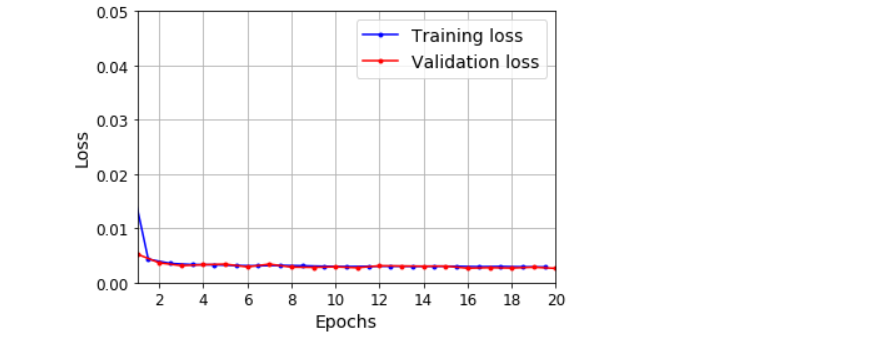
plot_learning_curves(history.history['loss'], history.history['val_loss'])
plt.show()
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()

提前几步预测
np.random.seed(43)
series = generate_time_series(1, n_steps + 10)
X_new, Y_new = series[:, :n_steps], series[:, n_steps:]
X = X_new
for step_ahead in range(10):
y_pred_one = model.predict(X[:, step_ahead:])[:, np.newaxis, :]
X = np.concatenate([X, y_pred_one], axis=1)
Y_pred = X[:, n_steps:]
Y_pred.shape # (1, 10, 1)
def plot_multiple_forecasts(X, Y, Y_pred):
n_steps = X.shape[1]
ahead = Y.shape[1]
plot_series(X[0, :, 0])
plt.plot(np.arange(n_steps, n_steps + ahead), Y[0, :, 0], 'ro-', label='Actual')
plt.plot(np.arange(n_steps, n_steps + ahead), Y_pred[0, :, 0], 'bx-', label='Forecast', markersize=10)
plt.axis([0, n_steps + ahead, -1, 1])
plt.legend(fontsize=14)
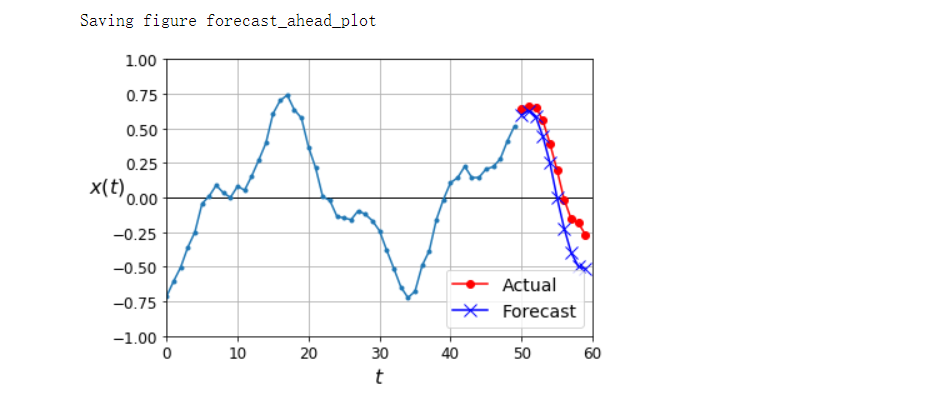
plot_multiple_forecasts(X_new, Y_new, Y_pred)
save_fig('forecast_ahead_plot')
plt.show()
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 10)
X_train, Y_train = series[:7000, :n_steps], series[:7000, -10:, 0]
X_valid, Y_valid = series[7000:9000, :n_steps], series[7000:9000, -10:, 0]
X_test, Y_test = series[9000:, :n_steps], series[9000:, -10:, 0]
X = X_valid
for step_ahead in range(10):
y_pred_one = model.predict(X)[:, np.newaxis, :]
X = np.concatenate([X, y_pred_one], axis=1)
Y_pred = X[:, n_steps:, 0]
Y_pred.shape # (2000, 10)
np.mean(keras.metrics.mean_squared_error(Y_valid, Y_pred)) # 0.027510853
Y_naive_pred = np.tile(X_valid[:, -1], 10)
np.mean(keras.metrics.mean_squared_error(Y_valid, Y_naive_pred)) # 0.25697407
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[50, 1]),
keras.layers.Dense(10)
])
model.compile(loss='mse', optimizer='adam')
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(10)
])
model.compile(loss='mse', optimizer='adam')
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, -10:, :]
Y_pred = model.predict(X_new)[..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
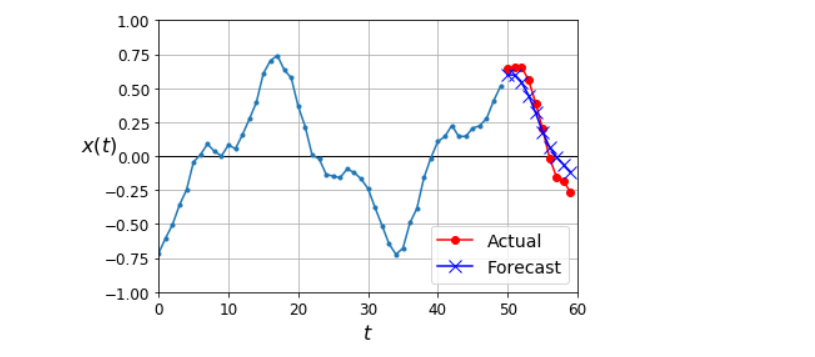
序列到序列的RNN
损失将包含每个时间步长的RNN输出项,而不仅仅是最后一个时间步长的输出项。这意味着将有更多的误差梯度流过模型,它们不需要随时间而“流淌”。它们从每个时间步长的输出中流出,这会稳定和加速训练
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 10)
X_train = series[:7000, :n_steps]
X_valid = series[7000:9000, :n_steps]
X_test = series[9000:, :n_steps]
Y = np.empty((10000, n_steps, 10))
for step_ahead in range(1, 10 + 1):
Y[..., step_ahead - 1] = series[..., step_ahead:step_ahead + n_steps, 0]
Y_train = Y[:7000]
Y_valid = Y[7000:9000]
Y_test = Y[9000]
X_train.shape, Y_train.shape # ((7000, 50, 1), (7000, 50, 10))
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
def last_time_step_mse(Y_true, Y_pred):
return keras.metrics.mean_squared_error(Y_true[:, -1], Y_pred[:, -1])
model.compile(loss='mse', optimizer=keras.optimizers.Adam(learning_rate=0.01), metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()

包含批量归一化的深度RNN
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.BatchNormalization(),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.BatchNormalization(),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
包含层归一化的深度RNN
from tensorflow.keras.layers import LayerNormalization
class LNSimpleRNNCell(keras.layers.Layer):
def __init__(self, units, activation='tanh', **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units, activation=None)
self.layer_norm = LayerNormalization()
self.activation = keras.activations.get(activation)
def get_initial_state(self, inputs=None, batch_size=None, dtype=None):
if inputs is not None:
batch_size = tf.shape(inputs)[0]
dtype = inputs.dtype
return [tf.zeros([batch_size, self.state_size], dtype=dtype)]
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True, input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
创建一个自定义的RNN类
class MyRNN(keras.layers.Layer):
def __init__(self, cell, return_sequences=False, **kwargs):
super().__init__(**kwargs)
self.cell = cell
self.return_sequences = return_sequences
self.get_initial_state = getattr(self.cell, 'get_initial_state', self.fallback_initial_state)
def fallback_initial_state(self, inputs):
batch_size = tf.shape(inputs)[0]
return [tf.zeros([batch_size, self.cell.state_size], dtype=inputs.dtype)]
@tf.function
def call(self, inputs):
states = self.get_initial_state(inputs)
shape = tf.shape(inputs)
batch_size = shape[0]
n_steps = shape[1]
sequences = tf.TensorArray(inputs.dtype, size=(n_steps if self.return_sequences else 0))
outputs = tf.zeros(shape=[batch_size, self.cell.output_size], dtype=inputs.dtype)
for step in tf.range(n_steps):
outputs, states = self.cell(inputs[:, step], states)
if self.return_sequences:
sequences = sequences.write(step, outputs)
if self.return_sequences:
return tf.transpose(sequences.stack(), [1, 0, 2])
else:
return outputs
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
MyRNN(LNSimpleRNNCell(20), return_sequences=True, input_shape=[None, 1]),
MyRNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
LSTM
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
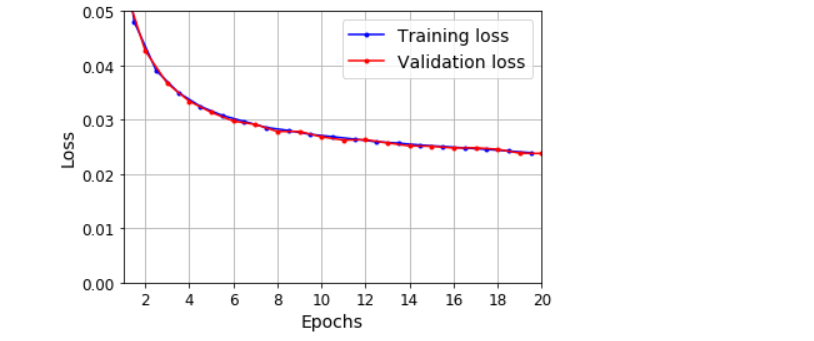
model.evaluate(X_valid, Y_valid) # [0.023788679391145706, 0.008560794405639172]
plot_learning_curves(history.history['loss'], history.history['val_loss'])
plt.show()
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
GRU
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.GRU(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
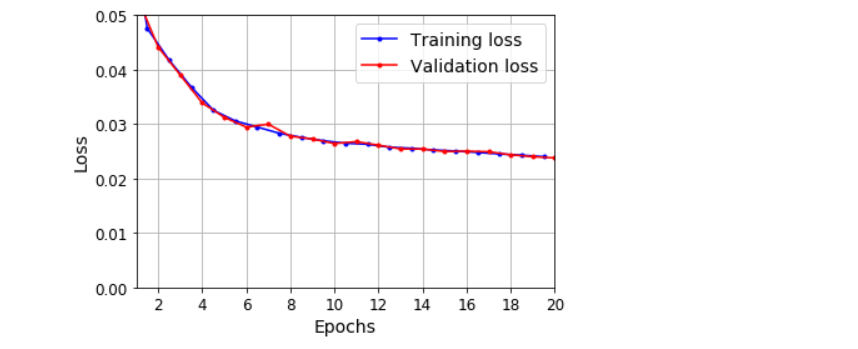
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
model.evaluate(X_valid, Y_valid) # [0.023785505443811417, 0.010262805968523026]
plot_learning_curves(history.history['loss'], history.history['val_loss'])
plt.show()
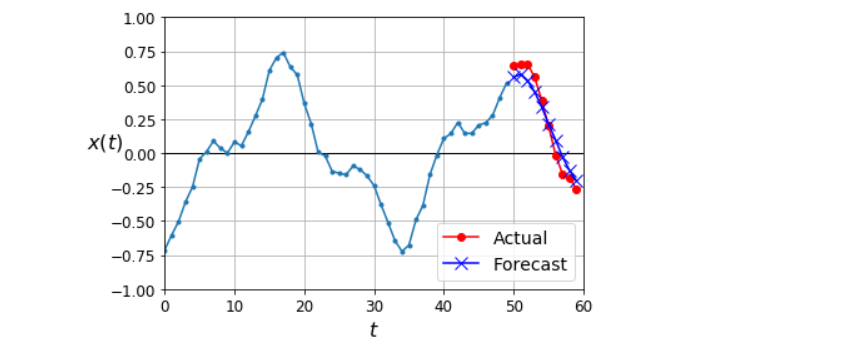
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()

使用一维卷积层处理序列
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Conv1D(filters=20, kernel_size=4, strides=2, padding='valid', input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train[: ,3::2], epochs=20, validation_data=(X_valid, Y_valid[:, 3::2]))
WaveNet
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=[None, 1]))
for rate in (1, 2, 4, 8) * 2:
model.add(keras.layers.Conv1D(filters=20, kernel_size=2, padding='causal', activation='relu', dilation_rate=rate))
model.add(keras.layers.Conv1D(filters=10, kernel_size=1))
model.compile(loss='mse', optimizer='adam', metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20, validation_data=(X_valid, Y_valid))
原始的WaveNet
以下是的原始WaveNet:它使用门控激活单元(Gated Activation Units)代替ReLU,参数化跳跃连接,并在左侧填充0,以避免序列越来越短:
class GatedActivationUnit(keras.layers.Layer):
def __init__(self, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
def call(self, inputs):
n_filters = inputs.shape[-1] // 2
linear_output = self.activation(inputs[..., :n_filters])
gate = keras.activations.sigmoid(inputs[..., n_filters:])
return self.activation(linear_output) * gate
def wavenet_residual_block(inputs, n_filters, dilation_rate):
z = keras.layers.Conv1D(2 * n_filters, kernel_size=2, padding="causal",
dilation_rate=dilation_rate)(inputs)
z = GatedActivationUnit()(z)
z = keras.layers.Conv1D(n_filters, kernel_size=1)(z)
return keras.layers.Add()([z, inputs]), z
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
n_layers_per_block = 3 # 10 in the paper
n_blocks = 1 # 3 in the paper
n_filters = 32 # 128 in the paper
n_outputs = 10 # 256 in the paper
inputs = keras.layers.Input(shape=[None, 1])
z = keras.layers.Conv1D(n_filters, kernel_size=2, padding="causal")(inputs)
skip_to_last = []
for dilation_rate in [2**i for i in range(n_layers_per_block)] * n_blocks:
z, skip = wavenet_residual_block(z, n_filters, dilation_rate)
skip_to_last.append(skip)
z = keras.activations.relu(keras.layers.Add()(skip_to_last))
z = keras.layers.Conv1D(n_filters, kernel_size=1, activation="relu")(z)
Y_proba = keras.layers.Conv1D(n_outputs, kernel_size=1, activation="softmax")(z)
model = keras.models.Model(inputs=[inputs], outputs=[Y_proba])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=2, validation_data=(X_valid, Y_valid))