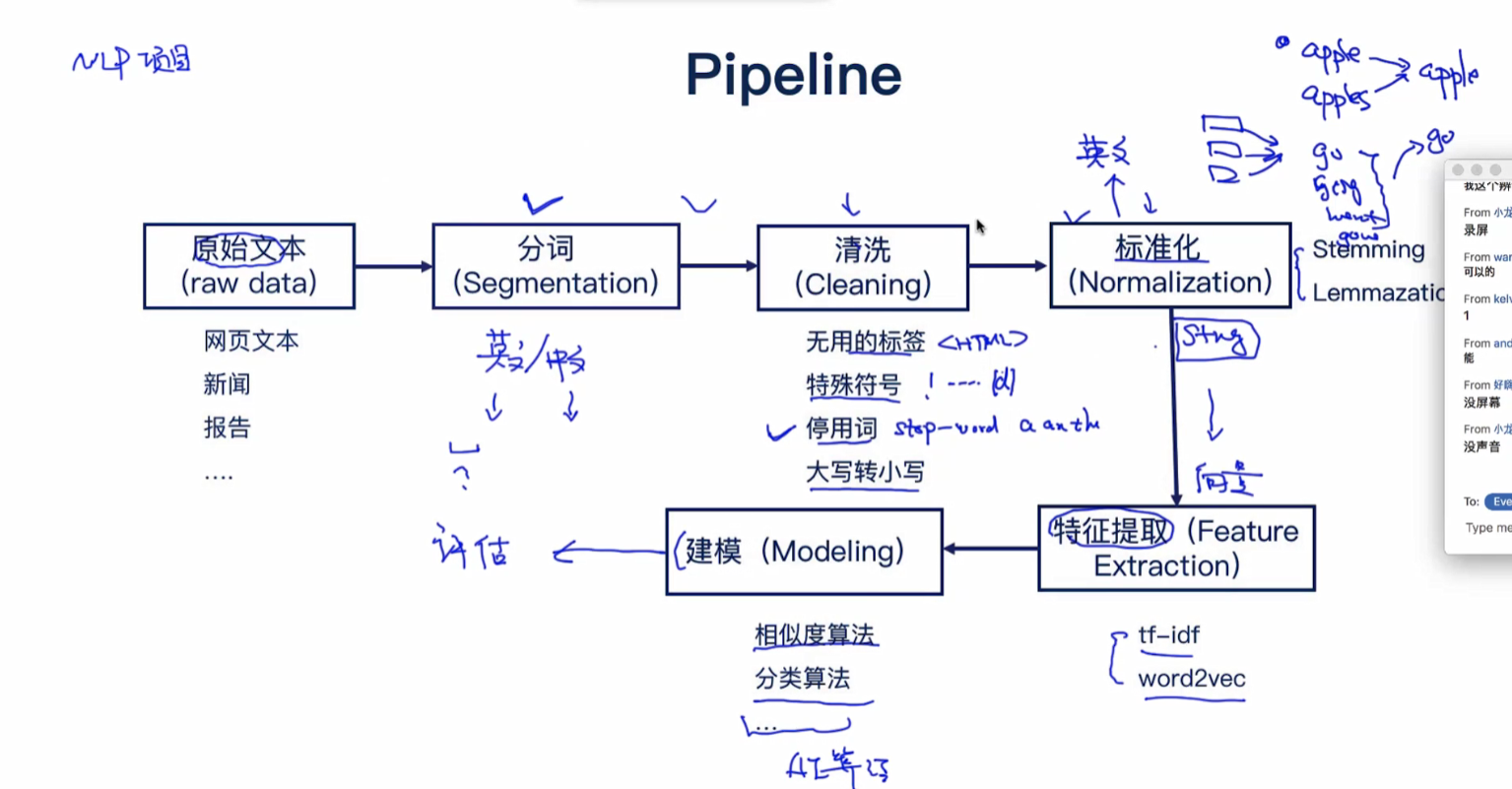
一:分词
常用的分词工具有jieba分词,snowNLP,LTP,HanNLP
1.前向最大匹配算法
现在假设我们有一个词典库{‘这些’,“这些年”,‘年’,‘的’, ‘情’,‘与’,‘爱’,‘终究’,‘是’, ‘错’,‘错付’,‘了’, ‘甄嬛’,。。。}
我们对“这些年的情与爱终究是错付了”利用前向最大匹配法进行分词。
1.首先需要设置max-len,这个参数表示每次分词时候的窗口大小。例如我这里设置为5
2.首先开始划分,将原句划分为"[这些年的情]与爱终究是错付了",但是“这些年的情”并没有在词典库中,所以需要对这5个字逐渐缩小范围
3.缩小一个字,将2中的句子进一步划分为“[这些年的]情与爱终究是错付了”,发现“这些年的”也不在词典库中,所以要再次缩小范围
4.继续缩小范围,将3中的句子划分为“[这些年]的情与爱终究是错付了”,“这些年”在词典库中,所以可以划分出来。我们得到了第一个划分的词汇:这些年
5.接下来继续使用max_len指示的长度划分出5个字符,即“这些年[的情与爱终]究是错付了”,词典库找不到,继续缩小范围
6.缩小成“这些年[的情与爱]终究是错付了”,词典库找不到,继续缩小范围
7.缩小成“这些年[的情与]爱终究是错付了”,词典库找不到,继续缩小范围
8.缩小成“这些年[的情]与爱终究是错付了”,词典库找不到,继续缩小范围
9.缩小成“这些年[的]情与爱终究是错付了”,词典库找到了,所以得到第二个划分的词汇:的
10.接下来继续使用max_len指示的长度划分出5个字符,即“这些年的[情与爱终究]是错付了”,词典库找不到,继续缩小范围
11.缩小成“这些年的[情与爱终]究是错付了”,词典库找不到,继续缩小范围
12.缩小成“这些年的[情与爱]终究是错付了”,词典库找不到,继续缩小范围
13.缩小成“这些年的[情与]爱终究是错付了”,词典库找不到,继续缩小范围
14.缩小成“这些年的[情]与爱终究是错付了”,词典库找到,所以得到第三个划分的词汇:情
依次划分下去便可以得到“这些年 的 情 与 爱 终究 是 错付 了”
前向最大匹配算法是基于贪心算法的。
二:后向匹配算法
就是前向匹配算法倒着来啦。举个例子,划分“我们经常有意见分歧”,词典库中有{‘我们’,‘经常’,‘有’,‘有意见’,‘分歧’},maxlen = 5
1. 划分成“我们经常[有意见分歧]”, 词典库中找不到
2.划分成“我们经常有[意见分歧]”,词典库中找不到
3.划分成“我们经常有意[见分歧]”,词典库中找不到
4.划分成“我们经常有意见[分歧]”, 词典库中找到了,所以分出来
5.继续划分“我们[经常有意见]分歧”,词典库中找不到
6.划分成“我们经[常有意见]分歧”,词典库中找不到
7.划分成“我们经常[有意见]分歧”,词典库中找到了,所以分出来
依次划分下去,将原句划分为“我们 经常 有意见 分歧”