
论文链接: https://arxiv.org/abs/2004.01461
github: https://github.com/Yonghongwei/Gradient-Centralization
1. 综述
这篇论文是由阿里达摩院和香港理工大学共同合作。这篇文章相较于传统对于神经网络(deep neural network, DNN)的优化方法:关注在激活函数或者说参数权重,提出了新的优化方案即:Gradient centralization (GC),GC通过将梯度向量化为零均值实现优化。GC可以同时调整(regularize) 权值空间以及输出特征时间,并且,改善了Lipschitzness损失函数以及他的梯度。GC一行代码就可以实现,并且在预训练的时候可以直接运用。在通用图像分类、细粒度图像分类、检测和分割等应用中的实验表明,GC 能持续提升 DNN 学习性能。
2. 介绍(背景)
一个好的DNN优化器应该有两个特征: 加速训练过程以及提高泛化能力。关于加速训练的算法:
- SGD以及他的扩展SGDM是最常用的
- 最近优化方案是基于SGD的,并且解决了梯度消失或者爆炸等问题。例如:weight initialization strategies, efficient active functions (e.g., ReLU), gradient clipping, adaptive learning rate optimization algorithms等等。
除了以上提到的这些优化,像样本的均值和方差 (mean and variance)可以用来正则化激活函数或者改变权值让训练过程更加平稳。有如下:
- Bath normalization (BN, 批量梯度下降)
- instance normalization (IN)
- layer normalization (LN)
- group normalization
但是我们知道的是,在样本比较小的时候,BN是训练比较好的。面对现如今的大数据时代,BN明显已经不再适合。
另外一条优化的线路就是操作权值。有如下:
- weight normalization (WN)
- weight standardization (WS)
这两个方法都是限制向量的权值而达到优化的目的。但是,这些方法都不能直接运用在零均值和单位方差上。所以我们提出了GC的优化方案。
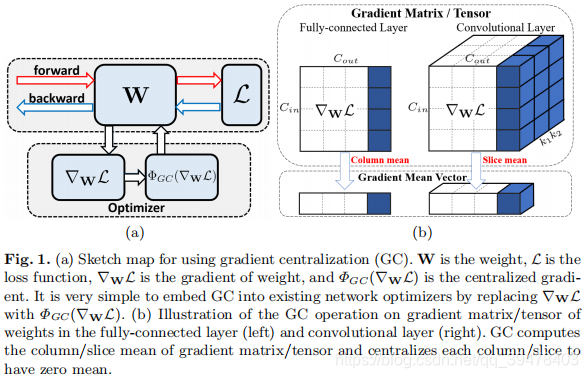
在图a中,GC很简单的中心化梯度向量并且使他们有了零均值,在我们现有的梯度优化算法中,很容易嵌入进去。(例如SGDM, Adam)。它加速了训练过程,优化了模型表现,并使得微调的预训练模型和谐。这篇论文的主要贡献:
- 提出了Gradient Centralization
- 引入了一种新的压缩向量权重的方法,能够同时调整权重空间和输出特征空间。
