一.模块的循环导入问题
在python工程中,由于架构不当,可能会出现模块间互相引用的情况.这时候需要通过一些方法来解决这个问题
1.重新设计架构,解决互相引用的关系.
2.把import语句放置在模块的最后
3.把import语句放置在函数中
方法2:
示例代码:拥有两个模块:m1.py和m2.py
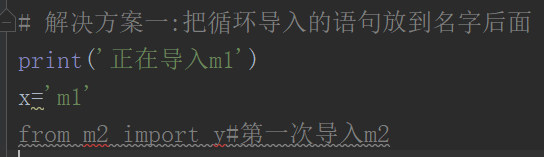

运行执行文件run.py.文件中只导入m1模块
执行结果:

这样就可以解决互相引用出错的问题
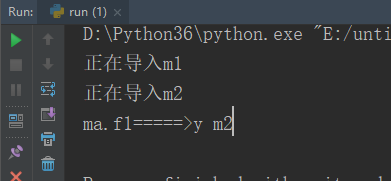
方法3
示例代码:拥有两个模块:m1.py和m2.py


运行执行文件run.py.文件中导入m1模块,并执行m1中的f1()函数
执行结果:
二.区分python文件的两种用途
在模块中我们也可以运行模块本身代码.从而做到测试自身代码的作用,但是如果没有将模块中的运行的代码关闭时就会发生在导入该模块时自动运行了模块中的功能
为了解决这一问题,我们可以使用python自带的__name__
例如:

当模块执行时会运行其中的两个函数,当是执行文件运行时则不运行这两个函数
三.模块的搜索路径
模块的导入需要一个叫做"路径搜索"的过程,即在文件系统"预定义区域"中查找某个文件,这些预定义区域只不过时你的Python搜索路径的集合.
模块搜索路径的优先级:
1.内存中已经加载过的
2.内置模块
3.sys.path第一个值是当前执行文件所在的文件夹
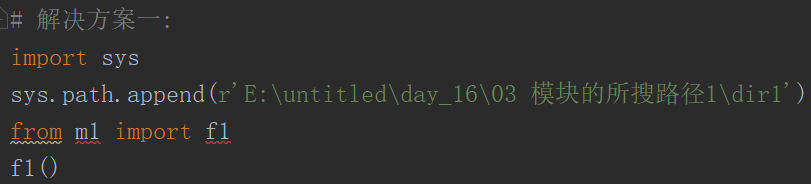
代码示例:执行文件run.py需要调用在同级文件夹dir1下的m1模块
解决方案一:
解决方案二:

两种方法都可以解决问题,只要在合适的环境下选择合适的方法即可
环境变量是以当前执行文件为准
所有被导入的模块参照环境变量sys.path都是以执行文件为准
四.绝对导入与相对导入
绝对导入:以执行文件的sys.path为起始点开始导入,称为绝对导入
优点:执行文件与被导入的模块都可以使用
缺点:所有导入都是以sys.path为起始点,导入麻烦
相对导入:参照当前所在文件的文件夹为起始点开始查找,称为相对导入
符号:.代表当前所在文件的文件夹.加一个.代表上一级文件夹
优点:导入更加简便
缺点:只能在被导入的模块中使用,不能在执行文件中使用