一.shelve模块
shelve也是一种序列化方式,在python中shelve模块提供了基本的存储操作,shelve中的open函数在调用的事和返回一个shelf对象,通过该对象可以存储内容,即像操作字典一样进行存储操作.当在该对象中查找元素时,对象会根据已经存储的内容重新构建,当给某个键赋值的时候,元素会被存储.
下图为实现序列化:
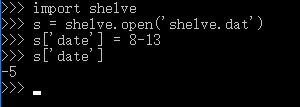
下图为发序列化
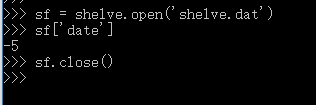
shelve模块特点:使用比较简单,提供一个文件名就可以进行读写操作,读写的方式与字典一致,非常方便,可以将它当作带有自动持久化的字典
shelve的内部使用的是pickle,所以存在跨平台性差的问题
二.XML模块
XML又称可扩展标记语言,可扩展标记语言是一种很像超文本标记语言的标记语言,它的设计宗旨是传输数据,而不是显示数据,它的标签没有被预定义,需要自行定义标签,它被设计为具有自我描述性,它是W3C的推荐标准.
XML语法格式:
一、任何的起始标签都必须有一个结束标签。
二、可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号之前紧跟一个斜线(/),
例如<百度百科词条/>。XML解析器会将其翻译成<百度百科词条></百度百科词条>。
三、标签必须按合适的顺序进行嵌套,所以结束标签必须按镜像顺序匹配起始标签,例如这是一串百度百科中的样例字符串。
这好比是将起始和结束标签看作是数学中的左右括号:在没有关闭所有的内部括号之前,是不能关闭外面的括号的。
四、所有的特性都必须有值。
五、所有的特性都必须在值的周围加上双引号。
注意:最外层必须有且只有一个标签,这个标签称为根标签
第一行应该又文档注释 例如:<?xml version="1.0" encoding "utf-8"?>
python对XML的解析:
python有三种方法解析XML:SAX,DOM以及ElementTree
1.SAX(simple API for XML)
python标准库包含SAX解析器,SAX用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件.
2.DOM(Document Object Model)
将XML数据在内存中解析成一个树,通过对树的操作来操作XML
3.ElementTree
ElementTree就像一个轻量级的DOM,具有方便友好的API,代码可用性好,速度快,消耗内存少.
与json的区别:
都是一种数据交互处理方式,只是xml比json诞生的更早,json的数据容量比xml小
python中的xml处理:
ElmentTree表示整个文件的元素树
Elment表示一个节点
属性:
1.text:开始标签与结束标签中间的文本
2.attrib:所有的属性
3.tag:标签的名字


<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2012</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> <newTag name="宇宙无敌帅">楼帅哥</newTag> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2015</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> <newTag name="宇宙无敌帅">楼帅哥</newTag> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2015</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> <newTag name="宇宙无敌帅">楼帅哥</newTag> </country> </data>
import xml.etree.ElementTree as et # 读取xml文档到内存中 得到一个包含所有数据的节点树 # 每一个标签就称为一个节点或元素 a = et.parse('text.xml') # 获取根标签 root = a.getroot() # 获取子标签 找的是第一个 print(root.find('country')) # 获取所有同级子标签 print(root.findall('country')) # 获取year print(root.iter('year')) for i in root.iter('year'): print(i) # 遍历整个xml for country in root: print(country.tag,country.attrib,country.text) for tag in country: print(tag.tag, tag.attrib, tag.text) print(root.find('country').get('name')) # ============================================= tree = et.parse('text.xml') for country in tree.findall('country'): # 修改所有country的year文本 改成加1 yeartag = country.find('year') yeartag.text = str(int(yeartag.text)+1) # 删除所有country的rank元素 country.remove(country.find('rank')) # 添加子标签 newtag = et.Element('newTag') # 文本 newtag.text = '楼帅哥' # 属性 newtag.attrib["name"] = '宇宙无敌帅' # 添加 country.append(newtag) # 写回文件中 tree.write('text.xml',encoding='utf-8')
三.configparser模块
configparser模块是配置解析模块,用于提供程序运行所需要的一些信息文件
配置文件的格式如下:
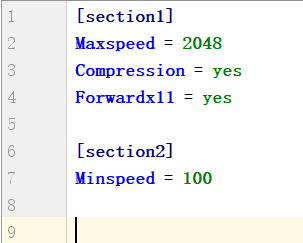
''[]''包含的为section,section下面为类似于key-value的配置内容,configparser默认支持'='或者':'两种分隔
实例代码如下:
import configparser # 得到配置文件对象 cfg = configparser.ConfigParser() # 读取配置文件 cfg.read('download.ini',encoding='utf-8') print(cfg.get('section1','maxspeed')) print(cfg.get('section2','minspeed')) # 修改最大速度为2048 cfg.set('section1','maxspeed','2048') cfg.write(open('download.ini','w',encoding='utf-8'))
四.hashlib模块
hash是一种算法,用于将任意长度的数据映射到一段固定长度的字符
hash的特点:
1.输入数据不同得到的hash值可能相同
2.不能通过hash值来得到输入的值
3.如果算法相同,无论输入的数据长度是多少,得到的hash值长度相同
因为以上特点:常将hash算法用于加密和文件校验
输入用户名和密码 在代码中与数据库中的判断是否相同
思考当你的数据需要在网络中传递时,会受到威胁,黑客通过抓包工具就能截获你发送和接收的数据
所以你的数据如果涉及到隐私 就应该加密发送和接收的数据
常用的md5就是一种hash算法,常用提升安全性的手段就是加盐,就是指在把加密前的数据做一些改动再进行加密
实例代码如下:
import hashlib md = hashlib.md5() # 破解MD5可以尝试撞库,原理:有一个数据库,里面存放了常见的明文和密文的对应关系 # 所以可以拿着一个秘闻 去数据库中查找,有没有已经存在的明文 # 假设我已经拿到了一个众多账号中的以恶密码,可以拿这个密码,挨个测试所有账号 md.update('123456'.encode('utf-8')) print(md.hexdigest()) # 今日在写一些需要网络传输程序时如果要进行加密,最好把加密的过程搞得复杂 # 密码长度为6位 # 在前面加一个abc 在后面加一个cba 之后再加密 pwd = 'abcdef' pwd = 'abc'+pwd+'cba' md2 = hashlib.md5() md2.update(pwd.encode('utf-8')) print(md2.hexdigest())