如何实现分布式爬虫
-
-
redis是支持分布式的内存数据库
-
可以为scrapy做一个新的调度器(redis),替换scapy的默认调度器, 从而实现分布式功能。
scrapy-redis
-
-
负责分布式爬虫的任务调度
-
依赖于Scrapy和redis。
-
主要组件:Scheduler、Dupefilter、Pipeline和Spider。
【没有使用分布式的时候】
url存在本机内容中,如: start_urls= ['http://www.dushu.com' ] yield scrapy.Request(url)
【使用分布式的时候】
没有了start_urls, 而是使用redis_key,
url存在redis中 命令行执行:redis-cli lpush myspider:start_urls 'http://www.xxx.com' 或者使用脚本执行: rds =Redis('127.0.0.1',6379) rds.lpush(...)
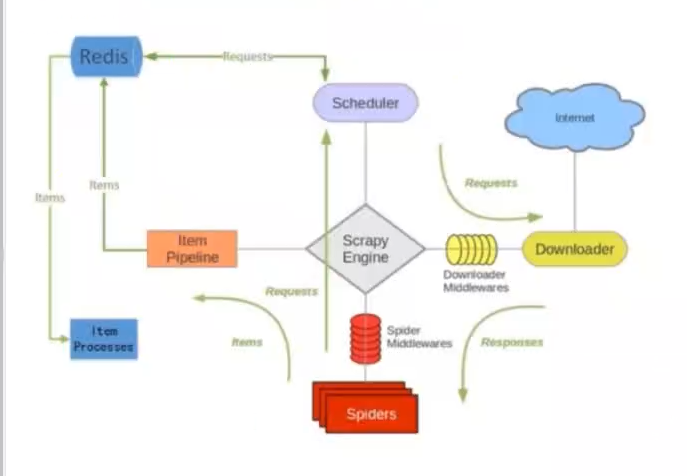
搭建分布式
master服务器的配置
-
-
修改master的redis配置文件redis.conf:
1)将 bind 127.0.0.1 修改为bind 0.0.0.0。(注意防火墙设置)
- 重启redis-server
- 在爬虫项目文件settings.py中添加配置信息
REDIS_HOST = 'localhost' REDIS_PORT = 6379
slave端的配置
- 在爬虫项目的settings.py文件中配置
REDIS_URL = 'redis://redis_server ip:6379'
master和slave端中共同的配置
在settings.py中启用redis存储
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400, }
运行分布式爬虫
# scrapy runspider myspider_redis.py scrapy crawl myspider
redis-cli -h redis_server_ip
redis-cli> lpush myspider_redis:start_urls http://www.xxxxxx.com/aaa/