Dataframe
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(多个series共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二维数组)
dataframe的创建
最常用的方法是传递一个字典或者二维数组的方法创建
DataFrame(data=data,index=['张三','李四','王五'],columns=list('语数外'))
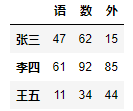
另外通过导入csv文件得到的也是DataFrame
import pandas as pd df1 = pd.read_csv('../backup/data/president_heights.csv') # 路径名
DataFrame属性:values、columns、index、shape
values:表格中的数据(二维数组)
columns:列索引
index:行索引
shape:形状
Dataframe的索引
(1) 对列进行索引
- 通过类似字典的方式
- 通过属性的方式
按照列名进行索引,获取到一个Series
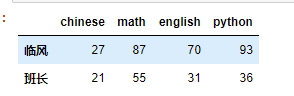
d = np.random.randint(0,100,size=(3,4)) d i = ['临风','班长','孙武空'] # 行索引 c = ['chinese','math','english','python'] # 列索引 df = DataFrame(d,i,c)

df['math'] 临风 87 班长 55 孙武空 28 Name: math, dtype: int32 type(df['math']) pandas.core.series.Series df.math 临风 87 班长 55 孙武空 28 Name: math, dtype: int32
(2) 对行进行索引
- 使用.loc[]加index来进行行索引,显式索引
- 使用.iloc[]加整数来进行行索引,隐式索引
同样返回一个Series,index为原来的columns。
# df.loc['临风'] # 显式索引 df.iloc[0] # 隐式所引进
chinese 27 math 87 english 70 python 93 Name: 临风, dtype: int32
总结
对 列 进行索引 df['列名'] df.列名 得到的是Series
对 行 进行索引 df.loc['行名'] df.iloc[行序号] 得到的是Series
(3) 对元素索引的方法
- 使用列索引
- 使用行索引
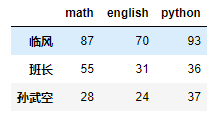
- 使用values属性(二维numpy数组)# 对具体元素进行定位 df.python.loc['班长'] # 先按列找 找到的是Series 在对Series进行索引 df.loc['班长'].iloc[-1] # df的loc或者iloc提供了更加优雅的方式 df.loc['班长','python'] df.iloc[1,-1] df.values # 如果DataFrame的索引记不清 可以直接通过values然后去定位值 array([[27, 87, 70, 93], [21, 55, 31, 36], [38, 28, 24, 37]]) df.values[1,-1]
【注意】 直接使用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
df['临风':'孙武空']
df['临风':'班长'] # 直接使用中括号 不能对列进行切片 而是对行进行切片(因为对行进行切片的需求比较常见)
# 如果非要对列 进行切片 可以使用loc或者iloc df.loc[:,'math':'python']
Dataframe的运算
(0) df和数值
df +5
相当于给表中的所有的数据都+5
# 对某一行样本进行修改
df.loc['临风']+=100
(1) DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
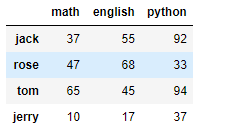
# 创建DataFrame df1 不同人员的各科目成绩,月考一 d = np.random.randint(0,100,size=(4,3)) d i = ['jack','rose','tom','jerry'] # 行索引 c = ['math','english','python'] # 列索引 df1 = DataFrame(d,i,c) df1
# 创建DataFrame df2 不同人员的各科目成绩,月考二 有新学生转入 d = np.random.randint(0,100,size=(5,3)) d i = ['jack','rose','tom','jerry','bob'] # 行索引 c = ['math','english','python'] # 列索引 df2 = DataFrame(d,i,c) df2
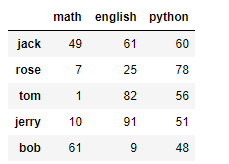
display(df1,df2) 可以让数据同时显示
df1+df2
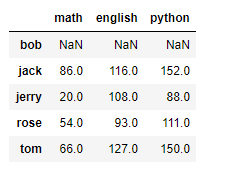
那么有没有办法不显示NaN呢,肯定是有的
其实对象使用 + 相加其实是执行了类中的add方法
所以
df1.add(df2,fill_value=0) # 设置上这个参数就可以给没有的数据设定一个默认值=
结果展示:

下面是Python 操作符与pandas操作函数的对应表:

(2) Series与DataFrame之间的运算
【重要】
-
使用Python操作符:以行为单位操作,对所有行都有效。(类似于numpy中二维数组与一维数组的运算,但可能出现NaN)
-
使用pandas操作函数:
axis=0:以列为单位操作(参数必须是列),对所有列都有效。 axis=1:以行为单位操作(参数必须是行),对所有行都有效。
例子:
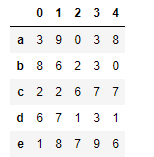
df = DataFrame(data=np.random.randint(0,10,size=(5,5)),index=list('abcde'),columns=list('01234')) df
s1 = Series(data=np.random.randint(0,10,size=5),index=list('01234')) s1
0 1 1 3 2 1 3 1 4 9 dtype: int32
df+s1 # 表格和序列 相加 默认 每一行都要和序列相加 对应项相加
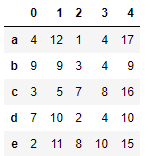
s2 = Series(data=np.random.randint(0,10,size=5),index=list('abcde')) s2
df+s2 # 输出的结果全部都是NaN
# axis='columns' 默认是columns 每一行和Series相加 让列名和Series中的索引去对应 df.add(s2,axis='index')