@
第二章 2.3章末小结
1
机器学习模型按照使用的数据类型,可分为监督学习和无监督学习两大类。
- 监督学习主要包括分类和回归的模型。
- 分类:线性分类,支持向量机(SVM),朴素贝叶斯,k近邻,决策树,集成模型(随机森林(多个决策树)等)。
- 回归:线性回归,支持向量机(SVM),k近邻,回归树,集成模型(随机森林(多个决策树)等)。
- 无监督学习主要包括:数据聚类(k-means)和数据降维(主成分分析)等等。
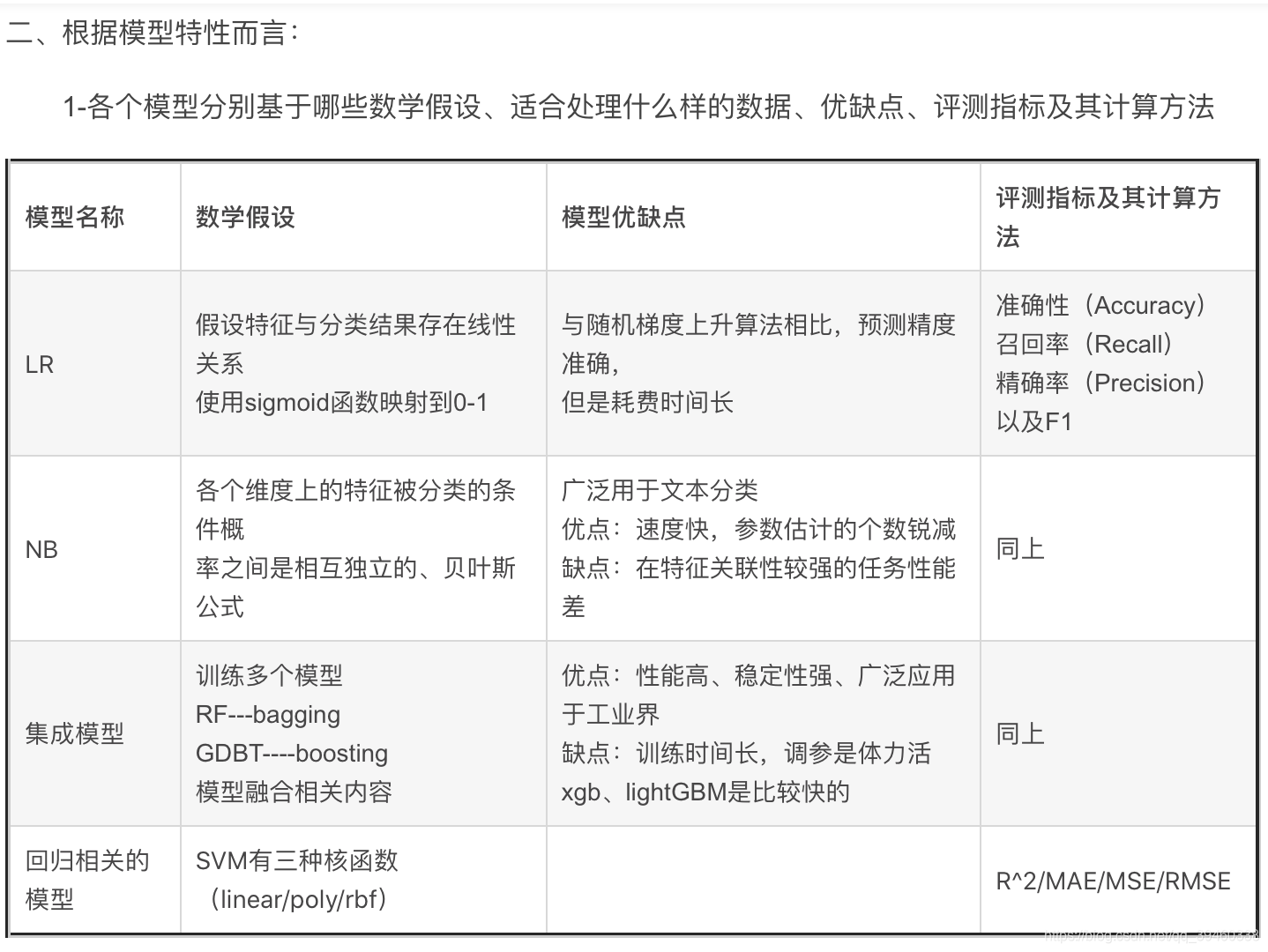
分类模型
线性:假设特征与分类结果存在线性关系,使用sigmoid函数映射到0~1,适合处理具有线性关系的数据。
在科学研究与工程实践中可把线性分类器的表现作为基准。lr使用精确解析,SGD使用随机梯度上升估计模型参数,耗时短,准确率略低
- 评价指标:准确性,召回率,精准率,和后二者混合的F1指标
支持向量机:精妙的模型假设,线性假设,只用考虑两个空间间隔最小的两个不同类别的数据点。可以在高维数据中选择最为有效的少数训练样本。这样不仅节省了模型学习所需要的内存,而且也提高了模型的预测性能,但付出了计算资源和时间的代价。
- 评价指标:同上,在回归中有R^2^,MS(平方)E,MA(绝对)E。
朴素贝叶斯 (naive bayes )基于贝叶斯理论。前提:各个维度上的特征被分类的条件概率之间互相独立。
- 缺点:由于模型的强假设,需要估计的参数规模从幂指数量级到线性数量级减少,极大节约了内存消耗和计算时间。但是对特征关联性较强的任务上表现不佳。
- 评价指标:同线性
k近邻:不需要参数训练,其属于无参数模型。非常高的计算复杂度(平方级)和内存消耗。
决策树:推断逻辑直观,有清晰的可解释性,也方便模型的可视化,易描述非线性关系。模型在学习的时候,需要考虑特征节点的选取顺序。
常用的度量方式包括信息熵和基尼不纯性。并不懂。。
集成模型: 有代表性的随机森林,同时搭建多个决策树模型,开始投票。
决策树可以随机选取特征构建节点(随机森林),或者按次序搭建分类模型(梯度提升决策树GTB)
特点:训练耗费时间,但是往往有更好的表现性能和稳定性。
我看分类这边都在用线性的度量指标。
回归模型
只是评估指标变了,在回归中有R^2^,MS(平方)E 均方误差,MA(绝对)E平方绝对误差。
R^2^用来衡量模型回归结果的波动可被真实值验证的百分比,也暗示了模型在数值回归方面的能力。
无监督学习
数据聚类
主流的k-means采用的迭代算法,直观易懂并非常实用。
- 容易收敛到局部最优解
- 需要预先设定簇的数量
可使用“肘部”观察法粗略地预估相对合理的类簇个数。
数据降维
主成分分析(PCA principal component analysis)
相较于损失的少部分模型性能。维度压缩能够节省大量模型训练时间。
明天开始进阶篇
隐隐约约感觉不太对,这个没啥 基础啊 全是调用