Django之ORM表间操作
之前完成了简单的数据库数据增加操作。这次学习更多的表间操作。
单表操作
增加
方式一
b = Book(title="Python基础", publication_date="2019-10-15", price=20)
b.save()
这是我们之前增加数据的方式,是用实例化对象的方式来添加数据的,这是添加数据的一种方式,接下来,我们看看其他的添加数据的方式。
方式二
Book.objects.create(title="Python基础", publication_date="2019-10-15", price=20)
这种方式来添加数据,不需要创建变量来接收和使用save()保存就会直接将数据添加到数据库。
删除
方式一
b = Book.objects.get(title="Python基础")
b.delete()
方式二
Book.objects.filter(title="Python基础").delete()
修改
方式一
book = Book.objects.get(name="天龙八部")
book.name = "天龙八部2"
book.save()
方式二
Book.objects.filter(name="天龙八部2").update(name="天龙八部") # 注意不能用get取值
这里注意,使用get取到的是一个对象,而使用filter获取的是一个查询集。
补充内容
如果你想看你的每个操作对应的是什么sql语句的话,需要在setting加上日志记录部分


LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
LOGGING
查看对应sql语句之后,我们可以查看对应的sql语句。如果查看两种修改数据的方式,会发现save()函数的执行效率是很低的。
注:在插入和更新数据中,save()方法是更新一行里面的所有列,而某些情况下,我们只需要更新行里的某几列,这个方法会把每个列都重新赋值,不论是不是修改过的,所以这个的效率是特别低的,如果在像修改这样的操作(update),是修改你改的那个字段,其他的并不会重新赋值。
#---------------- update方法直接设定对应属性----------------
models.Book.objects.filter(id=3).update(title="PHP")
##sql:
##UPDATE "app01_book" SET "title" = 'PHP' WHERE "app01_book"."id" = 3; args=('PHP', 3)
#--------------- save方法会将所有属性重新设定一遍,效率低-----------
obj=models.Book.objects.filter(id=3)[0]
obj.title="Python"
obj.save()
# SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price",
# "app01_book"."color", "app01_book"."page_num",
# "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = 3 LIMIT 1;
#
# UPDATE "app01_book" SET "title" = 'Python', "price" = 3333, "color" = 'red', "page_num" = 556,
# "publisher_id" = 1 WHERE "app01_book"."id" = 3;
查询
相关记录查询
查询相关API,使用方法:
模型类名.objects.查询内容
# 查询相关API:
# <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
# <2>all(): 查询所有结果
# <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
#-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()--------
# <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
# <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
# <6>order_by(*field): 对查询结果排序
# <7>reverse(): 对查询结果反向排序
# <8>distinct(): 从返回结果中剔除重复纪录
# <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
# <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。
# <11>first(): 返回第一条记录
# <12>last(): 返回最后一条记录
# <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
我们可以给模型类中加入"__str__"魔法方法,这样当我们打印一个对象的时候,就会输出这个魔法方法中对应的内容。
def __str__(self):
return self.name
这样修改之后,方便我们用控制台查看相关内容。
记录中指定字段的查询
book_list = Book.objects.all().values("title", "price")
如果使用values(),结果会以字典形式存储,如果使用values_list(),会以元组方式进行存储。这里如果进行修改,就需要修改前端的调用方式,因为如果是字典形式数据,是使用键来进行内容读取,而元组和列表是使用下标进行内容读取。
模糊查询
目前,我们已经可以完成基本的数据查询,比如相关记录查询和指定字段查询。但是在大部分的实际使用中,我们要对字段信息进行筛选,比如,查询价格大于50的相关记录。
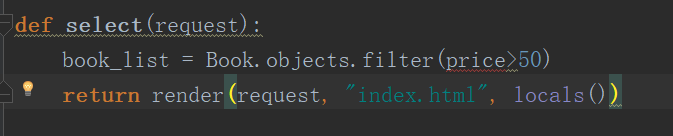
当我们在筛选条件中加入相关判断的时候,会出现报错,说明这种写法并不正确。这里就需要用到神奇的双下划线的相关用法。
book_list = Book.objects.filter(price__gt = 20).values("title", "price")
# 1)模糊查询 contains:是否包含。 startswith、endswith:以指定值开头或结尾。 # 2) 空查询 isnull:是否为null。 # 3) 范围查询 in:是否包含在范围内。 # 4) 比较查询 gt、gte、lt、lte:大于、大于等于、小于、小于等于。 # 5) 日期查询 year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
Model.objects.all() # 获取所有对象的QuerySet
Model.objects.filter() # 获取满足条件的对象的QuerySet
Model.objects.exclude() # 获取不满足条件的对象的QuerySet
Model.objects.get() # 获取单个符合条件的对象的QuerySet
Person.objects.all().extra(select={'is_adult': "age > 18"})
querySet.distinct() 去重复
__exact 精确等于 like 'aaa'
__iexact 精确等于 忽略大小写 ilike 'aaa'
__contains 包含 like '%aaa%'
__icontains 包含 忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__in 存在于一个list范围内
__startswith 以...开头
__istartswith 以...开头 忽略大小写
__endswith 以...结尾
__iendswith 以...结尾,忽略大小写
__range 在...范围内
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
一对多表间关系操作
一对多之增加记录
方式一
出版社表相关信息已有,然后创建book表记录
Book.objects.create(title="西游记", publisher_id=1, publication_date="2018-11-1", price=99)
这种方式,我们直接使用publisher_id来进行赋值。
方式二
这种赋值方式是对publisher进行赋值操作
pub_obj = Publisher.objects.get(name="南方出版社")
Book.objects.create(title="水浒传", publisher=pub_obj, publication_date="2018-11-1", price=99)
一对多查询之对象查询
之前,我们可以通过查询来获取一个对象,也就是表中的相关记录,然后通过调用类属性的方式来得到记录中的相关字段。
book_obj = Book.objects.get(title="悲惨世界")
print(book_obj.title)
print(book_obj.publication_date)
print(book_obj.price)
上面的操作方式仅限于单表,而表与表之间一般会存在着很多的关系,那么在一对多的表间关系中,如何去查询我们想要的内容呢?
现在我们将之前注释掉的设置书籍与出版社一对多关系的设置解开。
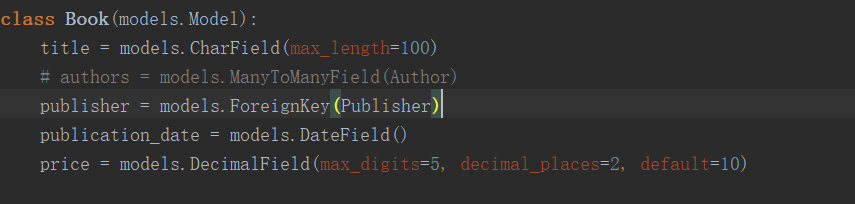
因为此时我们修改了表的相关字段,所以需要重新迁移和生成相关数据表,再手动加入一些记录。
接下来,修改views相关内容,查看相关字段。
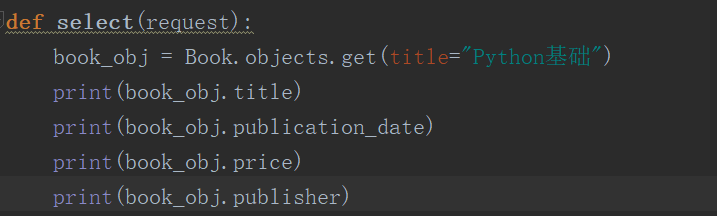
我们建立模型类的时候是使用publisher作为字段名的,所以这里打印这个字段看看对应内容。
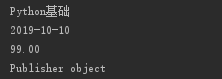
可以看到,打印这个外键得到的时一个publisher对象。其实这个对象就是这个书籍对应的出版社记录。而这个时候,我们可以用"."来获取里面的相关信息。
print(book_obj.publisher.name)
print(book_obj.publisher.city)
总结:
一对多的表间关系中,获得“多”表中记录时,拿到的外键值一定是一个对象。
多对多表间关系操作
多对多的表间关系其实是创建了一个第三方表来存放着他们的关系。我们将之前Book类中注释的多对多关系解开然后重写迁移和生成相关数据表。然后手动往作者表和图书表与作者表的多对多关系表中添加基本信息。
现在book表和author表都有了相关的数据,接下来要往这个多对多的表中添加关联的数据。现在有一个问题,通过查看数据库,我们可以看到这个多对多关联的表,但是我们并没有在模型类中定义这个表,也就是说没有办法通过”模型类名.objects.create()”等方法来创建记录。所以我们只能通过对象方式来绑定关系。
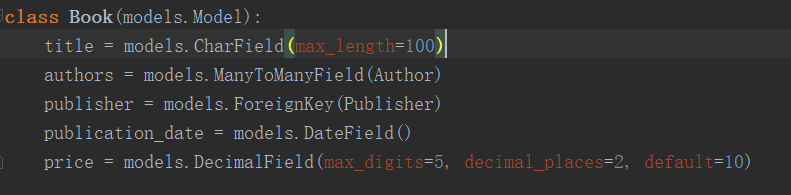
这个是我们模型类中定义的表间关系,之前我们可以通过"Book对象.publisher"来获取这个图书对应的publisher对象。那么"Book对象.author"应该是这本书绑定关系的作者信息。
b = Book.objects.get(id=3)
print(b.authors.all())
当打印之后为两个作者对象。

为了方便查看,可以在Author对象中定义“__str__"魔法函数。
def __str__(self):
return self.title
上面的查找方式是正向查找,除了正向查找,还可以用在一对多查找中使用的"模型类名_set”来进行反向查找。
b = Author.objects.get(id=2)
print(b.book_set.all())
前面,我们简单介绍了多对多表内容间的查询,接下来,我们看看如何用对象的方式来往表中添加数据。
b = Book.objects.get(id=3)
a = Author.objects.get(id=1)
b.authors.add(a)
上面这种是添加一条对应关系,如果给一本书添加多个作者,用以下方式:
b = Book.objects.get(id=3)
a = Author.objects.all()
b.authors.add(*a)
添加使用的是add()函数,想要解除,可以使用remove()函数,它的使用方式和add函数一致。
注意:除了这种方式,我们还可以在model中自己创建一个多对多的表,然后对其进行操作。
class Book_Author(models.Model):
book = models.ForeignKey("Book")
author = models.ForeignKey("Author")