1. 什么是网络爬虫?
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。
网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
2. 网络爬虫的作用
1.可以实现搜索引擎
我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
如果想获取一个简单的网站信息该怎么做呢?
import requests # 获取百度网站信息 r = requests.get('http://www.baidu.com') # 查看状态码 print(r.status_code) # 指定字符编码 r.encoding = 'utf-8' print(r.text)
首先我们要导入requests 库 并用 r.requests.get获取到百度网站的信息 然后使用 r.status_code 查看到当前的状态码 如果是200则表示获取成功
r.encoding 指定字符编码 最后调用 r.text 将获取的内容输出出来
执行一下 我们想要的结果就出来了

那想获取网站上的商品信息又该怎么办呢
首先我们找到一个网站 搜索一件商品 点击进去 复制他的链接
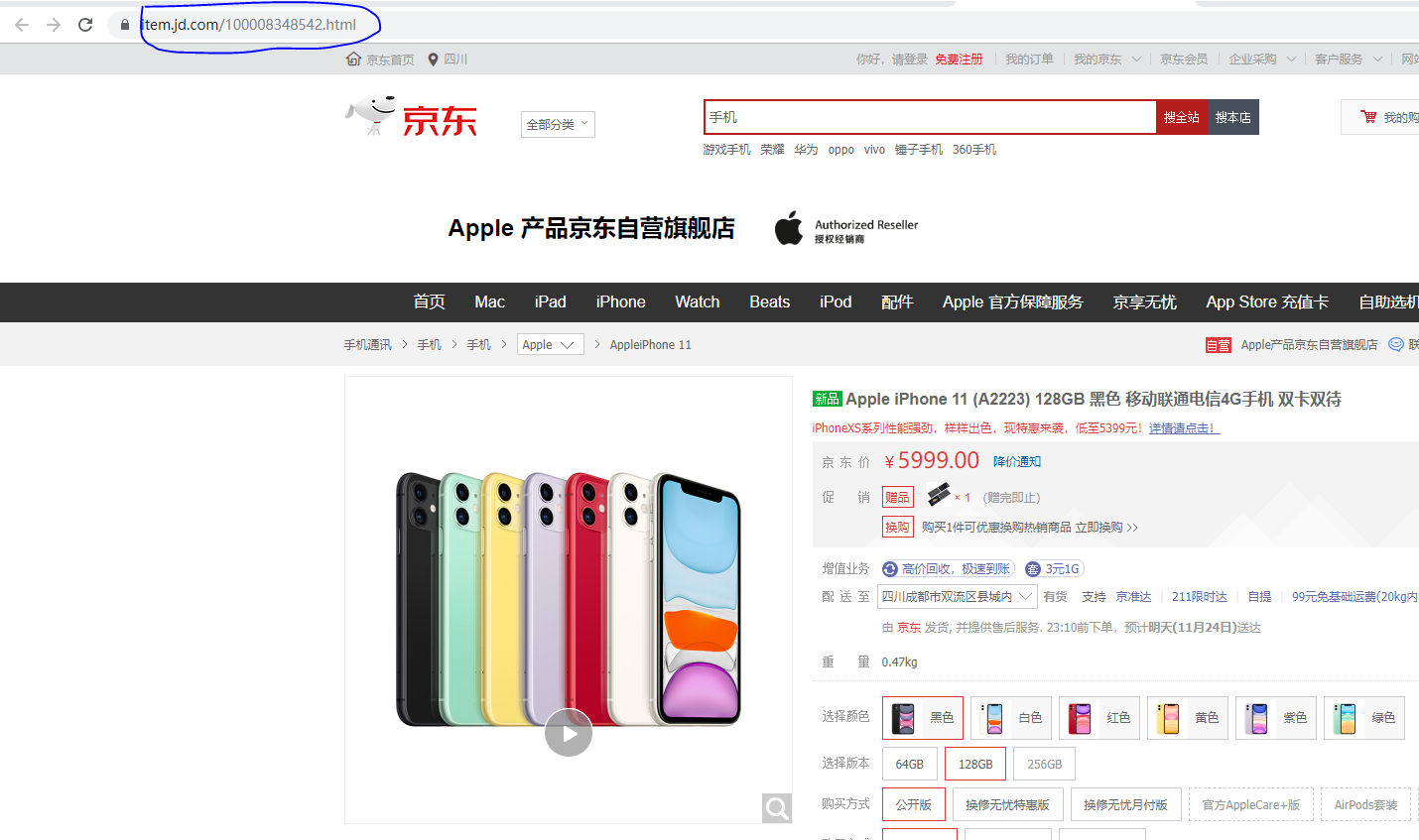
然后进行程序的编写 这里我们要用到 try 和 except 方法
import requests url = 'https://item.jd.com/100008348542.html' try: r = requests.get(url) r.raise_for_status() # 检测状态码如果是200则不报错 如果不是200 则抛出异常 # 获取字符编码 r.encoding = r.apparent_encoding print(r.text[:1000]) except: print("爬取失败")
显示结果

是不是很简单呢?
例2
import requests url = 'https://www.amazon.cn/dp/B06XGXXDV9?ref_=Oct_DLandingSV2_PC_45268aee_0&smid=A26HDXW89ZT98L' try: kv = {"User-Agent": 'Mozilla5.0'} r = requests.get(url, headers=kv) # headers=kv 将自己请求头部信息更改为 kv这个字典的数据 # 若果不更改头部信息默认是以requests库的身份去访问的网站 # 有时候会导致获取信息的获取异常 我们吧头部信息该为 Mozilla5.0 # 就会让服务器认为我们是以用户的身份去访问的网站 r.raise_for_status() r.encoding = r.apparent_encoding print(r.text) print(r.request.headers) except: print("爬取失败")
如果访问一个网站信息时发现 信息没有提取出来 则有可能是访问的服务器 通过判断你的头部信息拒绝了你的访问 这时候我们就要更改自己请求头的信息了
修改前

修改后 User-Agent 被修改了

如果你想要输入一个内容 查看百度返回的结果 可以通过查看百度接口来进行获取

我们可以看到当你输入图片 上面的wd会跟着输入的改变而改变 我们通过这个可以得出 只要修改wd的值就可以查看到相应的内容
下面我们通过代码来实现一下百度的搜索
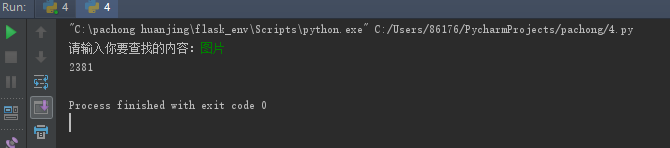
import requests keyword=input("请输入你要查找的内容:") try: kv = {"wd":keyword, "User-Agent": 'Mozilla5.0' } r = requests.get('http://www.baidu.com',kv) r.raise_for_status() print(len(r.text)) except: print("爬取失败")
显示结果 我们以len计算一下数据的长度就可以了
如果我们要获取网上的一张图片并将他保存在本地硬盘该怎么办呢?
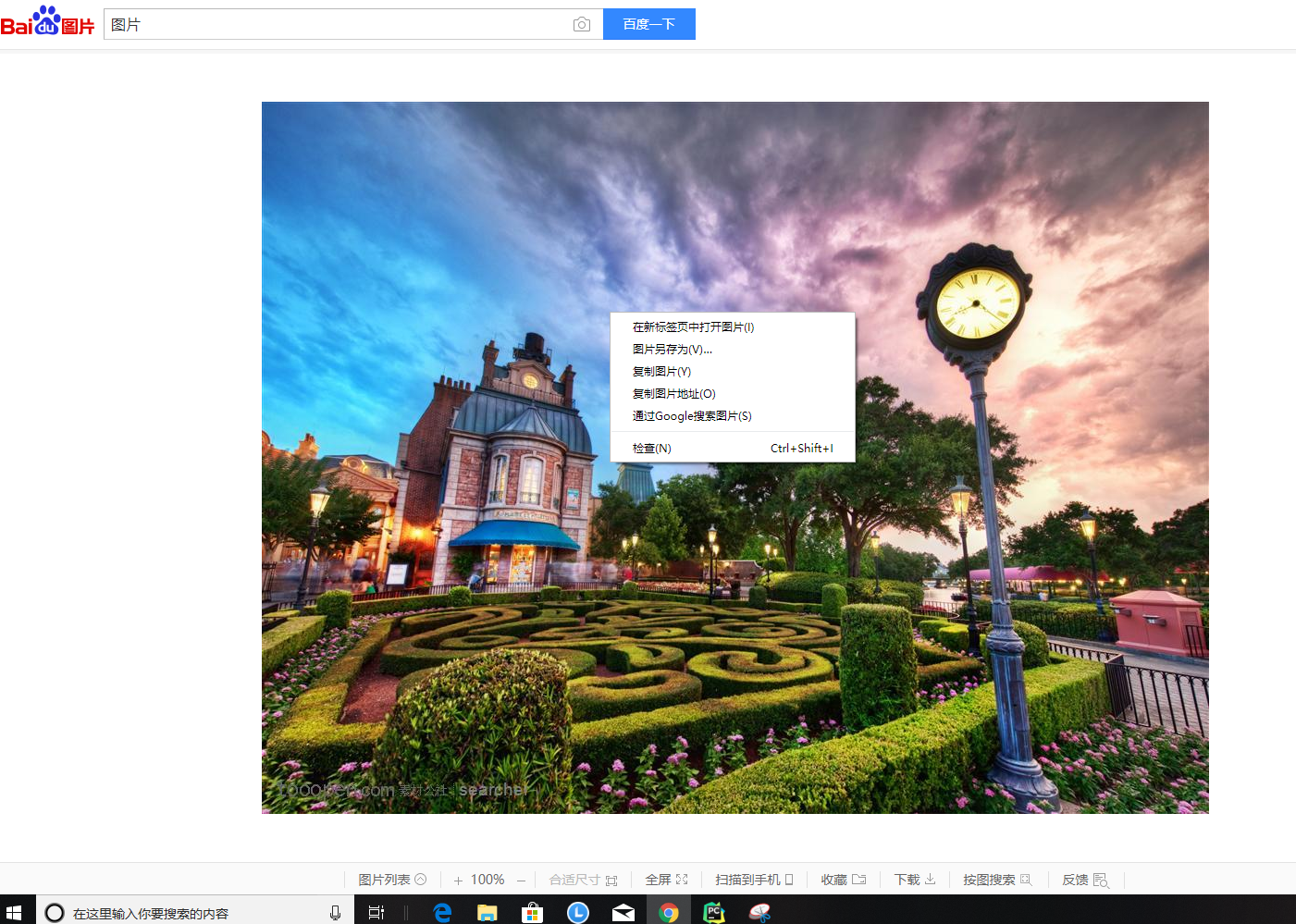
首先我们鼠标右击复制图片地址
然后进行程序的编写
import requests import os #图片链接 url = 'http://b-ssl.duitang.com/uploads/item/201210/03/20121003220216_xTBdK.jpeg' root = 'D://pics//' path = root + url.split('/')[-1] try: if not os.path.exists(root): #判断是否有这个目录 如果没有则创建一个 os.mkdir(root) if not os.path.exists(path): #判断是否有这个文件如果没有 则从url链接上面获取 r = requests.get(url) with open(path,'wb') as f: f.write(r.content) #r.content 是文件的二进制返回内容 f.write(r.content) 将返回的二进制形式写到文件中 f.close() print("文件保存成功") else: print("文件已存在") except : print("爬取失败")
然后产看D盘是否有这个文件
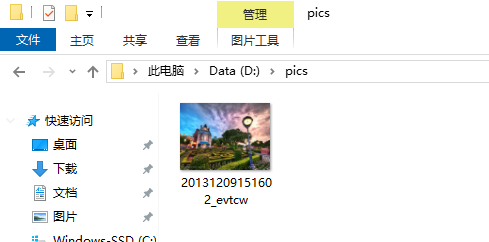
然后你就会发现图片已经保存在了本地 并且在pics目录下