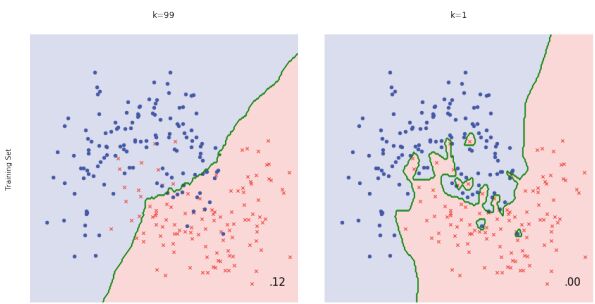
首先,我们看一下什么是过拟合,下面这张图右边,很明显,两类数据的分类率很高,采用了非常复杂的模型,讲两组数据分割开了。但是
我们仔细观察一下,那些混入蓝色区域的红色点,难道不是噪声引起了吗?因此要解决过拟合的问题,我们要讨论如何减少,混入测试数据集中的噪声。
我们以神经网络为例:
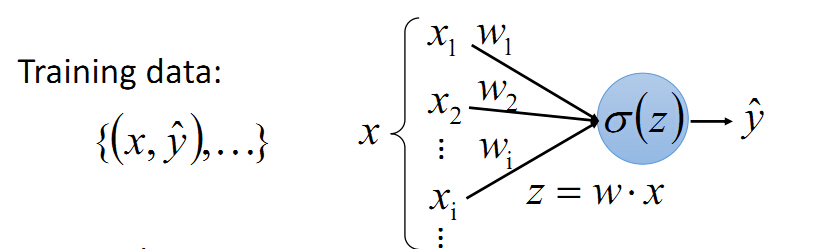
对于测试数据来说,假设测试数据混入了噪声ε。
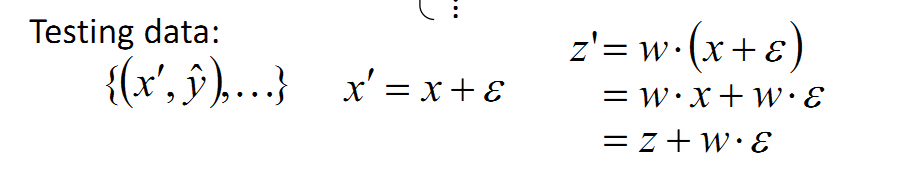
那么,为了保证测试数据的结果与训练数据一致,我们希望Wε最小,为了减少噪声ε影响,也就是说w最好是等于0。
我们定义新的损失函数如下,包括常规的损失函数和正则化项。

正则化项我们使用的2范数,我们希望w越小越好,接近0,对应的2范数中每个元素都接近0,这样其实也解释了稀疏性。我们找到的的参数都希望接近0
对新的损失函数求导:
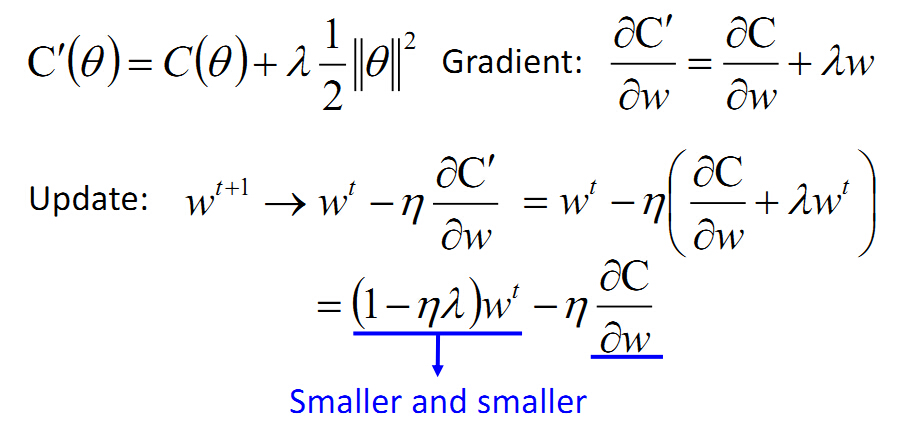
w在每一次更新时,都会乘以(1-ηλ),会变小,因此需要后面的项去平衡。
好了,解释了什么是过拟合,以及处理过拟合的正则化所需要的数学推导。